本文主要是介绍YOLOv5s处理二维牙齿数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、网络结构
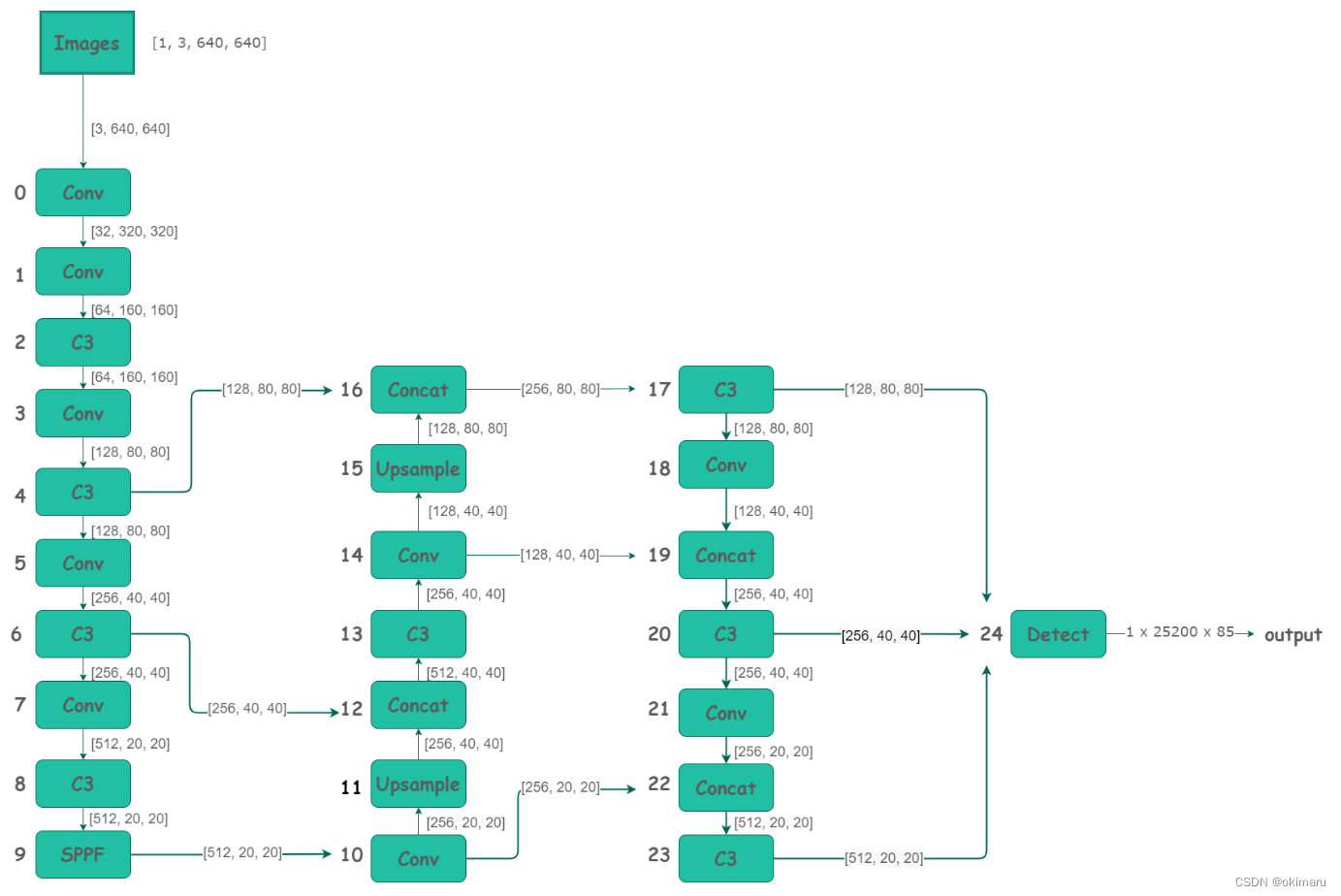
二、输入输出
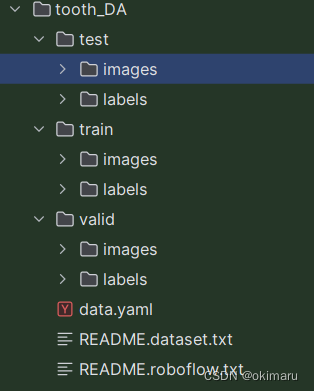
1、输入
640x640的图像
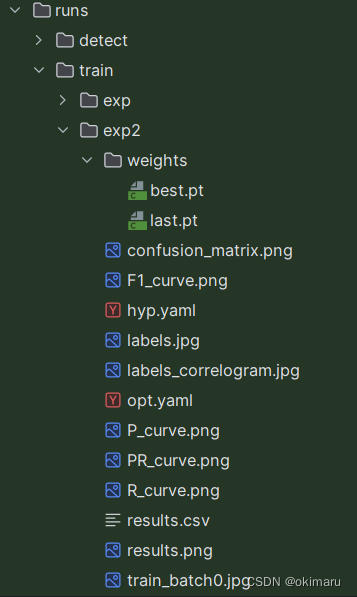
2、输出
权重文件
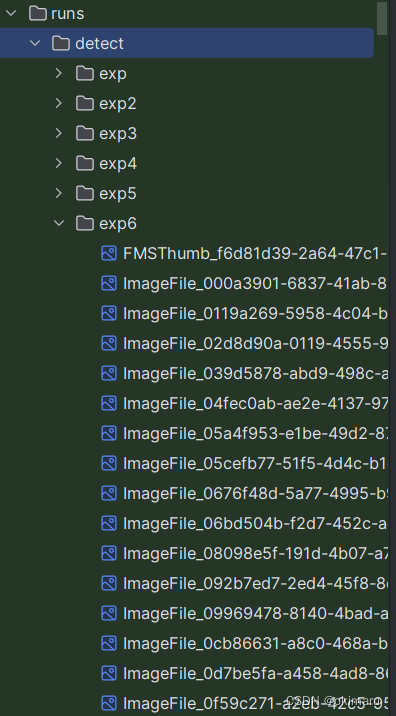
测试图像
三、数据预处理
在github上下载YOLOv5的模型,并安装模型所需环境
pip install -U -r requirements.txt四、训练&测试
对数据集进行训练
python train.py --img 640 --batch 16 --epochs 100 --data ./data/tooth_data.yaml --cfg ./models/yolov5s.yaml --weights ./yolov5s.pt
得出了权重 .../yolo5/runs/train/exp2/weights/best.pt
开始用权重测试
python detect.py --source ./datasets/tooth_DA/test/images --weights ./runs/train/exp2/weights/best.pt
测试完成后得到了图像 .../yolo5/runs/detect/exp6
这篇关于YOLOv5s处理二维牙齿数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




