本文主要是介绍Rancher HA 问题汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于前一篇 Rancher HA 高可用安装步骤 内容过长,后续相关内容在这里补充。
下面问题标记
[前]的需要在安装 Rancher HA 前提前考虑。
1. [前]域名问题
假设以下服务器使用的 hostname 为
rancher.mybatis.io
在前面写到了最后安装 Rancher 时要设置 hostname,在没有本地 DNS 服务器的情况下,需要修改本地 hosts 来映射域名。
如果只是修改访问 Rancher 的客户端电脑的 hosts 配置,虽然能打开 Rancher 了,但是仍然存在很多问题。
1.1 无法使用 Launch kubectl
在如下集群界面点击【Launch kubectl】
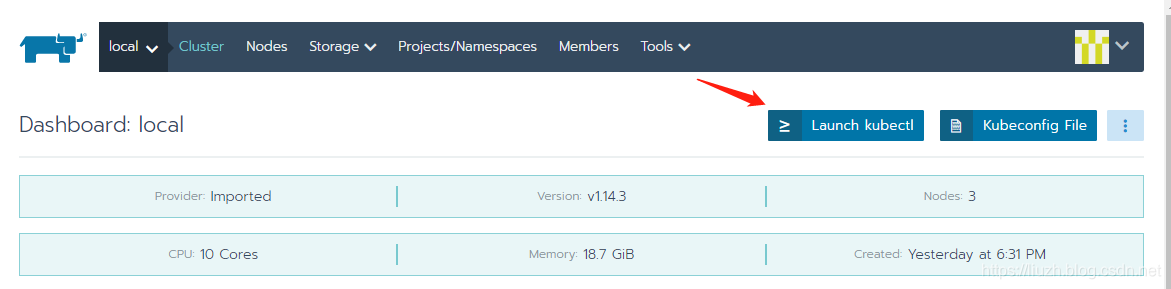
会弹出如下窗口:

这里可以看到 Closed Code: 1006,在 Devtools 的 Network 可以看到 404 错误:
Request URL: wss://rancher.mybatis.io/v3/clusters/local?shell=true
Request Method: GET
Status Code: 404 Not Found
经过搜索在 https://qiita.com/suzukihi724/items/00b167c6f5f2ddeca718 发现了线索。
1.2 cattle-xxx-agent CrashLoopBackOff
直接在集群节点通过 kubectl get pods --all-namespaces 获取 pod 状态:
NAMESPACE NAME READY STATUS RESTARTS AGE
cattle-system cattle-cluster-agent-5d6866db8-69nvc 0/1 CrashLoopBackOff 180 15h
cattle-system cattle-node-agent-4kkm4 0/1 CrashLoopBackOff 180 15h
cattle-system cattle-node-agent-ppwg4 0/1 CrashLoopBackOff 180 15h
cattle-system cattle-node-agent-qxm25 0/1 CrashLoopBackOff 180 15h
可以看到上面的 cattle agent Crash,查看上述有问题的 cluster 日志:
$ kubectl -n cattle-system logs cattle-cluster-agent-5d6866db8-69nvc
INFO: Environment: CATTLE_ADDRESS=10.42.0.6 CATTLE_CA_CHECKSUM=cc83e629bc77fdff27d1f160ab48c40af8e8490e06a291d798039b92a6e5dd2b CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-5d6866db8-69nvc CATTLE_SERVER=https://rancher.mybatis.io
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5
ERROR: https://rancher.mybatis.io/ping is not accessible (The requested URL returned error: 404 Not Found)
查看 node 日志:
$ kubectl -n cattle-system logs cattle-node-agent-4kkm4
INFO: Environment: CATTLE_ADDRESS=10.10.1.238 CATTLE_AGENT_CONNECT=true CATTLE_CA_CHECKSUM=cc83e629bc77fdff27d1f160ab48c40af8e8490e06a291d798039b92a6e5dd2b CATTLE_CLUSTER=false CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=10.10.1.238 CATTLE_SERVER=https://rancher.mybatis.io
INFO: Using resolv.conf: nameserver 114.114.114.114 nameserver 8.8.8.8
ERROR: https://rancher.mybatis.io/ping is not accessible (The requested URL returned error: 404 Not Found)
问题很明显,虽然客户端配置了 hosts,但是集群节点并不知道 rancher.mybatis.io 是哪个机器。
1.3 解决方案
- 在所有节点配置
/etc/hosts,先让所有节点都能认识rancher.mybatis.io - 最关键的部分,参考:https://www.jianshu.com/p/5c13ebfd9947,为Agent Pod添加主机别名(/etc/hosts)
# 配置 cattle-cluster-agent kubectl -n cattle-system patch deployments cattle-cluster-agent --patch '{"spec": {"template": {"spec": {"hostAliases": [{"hostnames":["rancher.mybatis.io"],"ip": "负载均衡IP"}]}}} }' # 配置 cattle-node-agent kubectl -n cattle-system patch daemonsets cattle-node-agent --patch '{"spec": {"template": {"spec": {"hostAliases": [{"hostnames":["rancher.mybatis.io"],"ip": "负载均衡IP"}]}}} }'
2.[后]监控问题
2.1 启用监控时不显示【监控组件版本】
如下图:
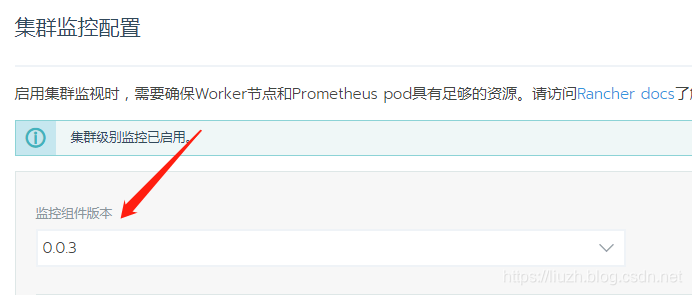
有些情况下会看不到这里的版本号,此时就算你点启用,也会100%失败。
主要原因是因为获取不到 rancher 的 system-charts,在【全局】下点击【工具】【商店】,打开下图:

一般情况下是因为访问不了这里的 url 地址导致的(如果你是局域网环境,肯定获取不到,官方文档也有介绍,这里需要修改地址)。
如果是偶然性访问不到,可以在【启用监控】页面多刷新几次,最直接的解决办法就是 clone 官方的仓库,然后配置为自己的地址。
官方仓库地址:https://github.com/rancher/system-charts.git
注意上图【分支】,需要使用 release-v2.2 分支。
改为自己的地址后,可以再试试。
2.2 监控一直处于未就绪状态
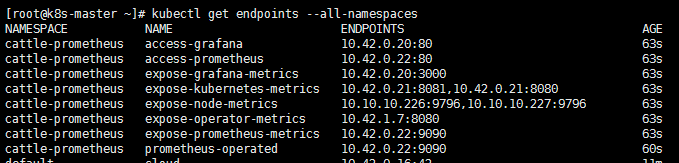
查看 rancher 日志时发现找不到 endpoint cattle-prometheus/prometheus-operated,此时查看 namespace=cattle-prometheus 的所有资源如下:
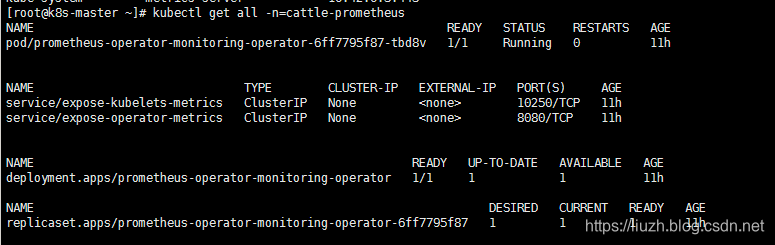
endpoints 如下:

经过查找发现有一个节点(局域网)上没有 rancher/coreos-prometheus-operator 镜像,下载该镜像。
然后,禁用监控,再启用监控,然后发现一切都正常了,此时的资源信息如下:
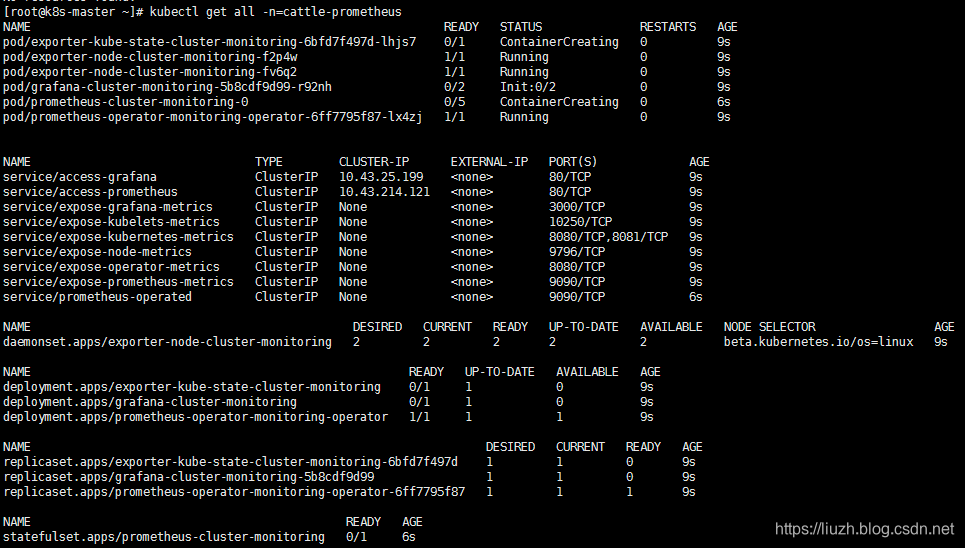
endpoints 如下:
3. rke-network-plugin-deploy-job 状态出错
创建集群时,出现下面的错误:

上面错误在内网环境出的,能访问外网的情况下没有出现过
追踪了一串也没解决,连到外网后重新 rke up 就好了。
4. 集群节点不能通信
内网一个两节点的集群,完全启动后发现两个节点内的容器无法互相访问,还有一个无法访问服务配置的 dns,最终也没从网络路由等方面解决的了。
失败半天后,通过配置 rke 的 cluster.yml 配置文件配置网络解决。
配置如下:
nodes:- address: 10.10.10.226user: k8srole: [controlplane,worker,etcd]- address: 10.10.10.227user: k8srole: [worker]
# 这里配置针对内网获取 rancher 相关镜像
private_registries:- url: 10.10.10.233user: registrypassword: ***is_default: true
# 这里的配置用于解决网络问题
network:plugin: flanneloptions:flannel_iface: ens160flannel_backend_type: vxlanservices:etcd:snapshot: truecreation: 6hretention: 24h
目前仍然不明白原因,但是上面解决问题的地方猜测是 flannel_iface,由于我自己的机器都是双网卡,因此指定了其中一个。
5. Ingress 上传文件大小限制
使用过程中发现文件超过1M就会上传失败(nginx ingress controller 413 request entity too large),经过搜索发现以下解决方案:
https://stackoverflow.com/questions/49918313/413-error-with-kubernetes-and-nginx-ingress-controller
摘抄如下,29
您可以使用注释 nginx.ingress.kubernetes.io/proxy-body-size 在您的 Ingress 对象中设置 max-body-size 选项,而无需更改基础 ConfigMap。
这是用法示例:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:name: my-appannotations:nginx.ingress.kubernetes.io/proxy-body-size: "50m"
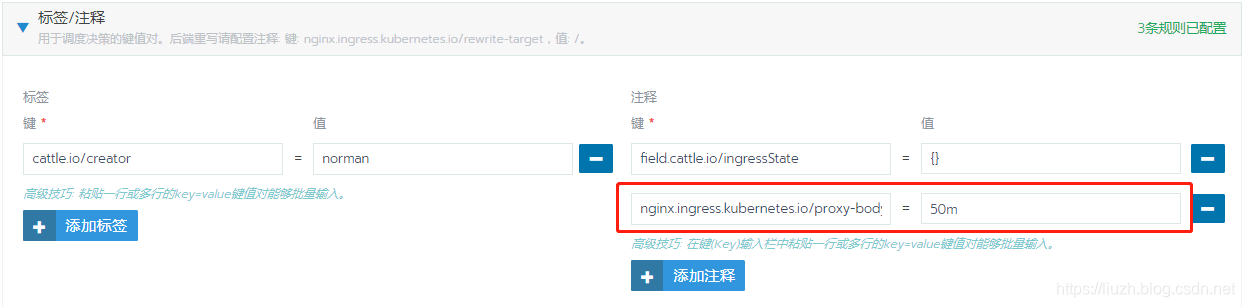
在 Rancher 中,在负载均衡找到想要修改的配置项,点击升级进入修改界面,添加如下:
6. nginx-ingress-controller
最近一次部署时(20191102),使用的镜像版本:image: rancher/nginx-ingress-controller:nginx-0.25.1-rancher1。
使用该镜像时,一直无法启动成功,后台报错如下:
I1103 07:13:18.072914 7 status.go:86] new leader elected: nginx-ingress-controller-dqgqh
E1103 07:13:18.114989 7 controller.go:145] Unexpected failure reloading the backend: -------------------------------------------------------------------------------
Error: exit status 1
nginx: the configuration file /tmp/nginx-cfg716345344 syntax is ok
2019/11/03 07:13:18 [emerg] 46#46: bind() to 0.0.0.0:80 failed (13: Permission denied)
nginx: [emerg] bind() to 0.0.0.0:80 failed (13: Permission denied)
nginx: configuration file /tmp/nginx-cfg716345344 test failed
主要就是 80 端口无法绑定,在 linux 中,1024以下端口都需要 root 权限启动才行。
以前用 rancher 都没问题,这次为什么不行了?
按照网上很多接近的问题答案尝试了一些,没有任何作用。
最后把版本切换到了前一个有效的服务版本: rancher/nginx-ingress-controller:0.21.0-rancher3
切换以后就好了!!!
因此原因不确定,但是降低版本能解决。
这篇关于Rancher HA 问题汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







