本文主要是介绍深究KNIME分析平台上的节点是如何实现推荐原理的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kinme节点推荐分为社区推荐和服务器推荐,社区推荐即为官方hub,网址https://hub.knime.com/,这个是knime官方存储节点和流程库的,里面也会时常更新。
社区推荐就根据很多使用社区里面节点的频率。服务器推荐是knime-server上存储的节点,我们在KAP分析平台上可以通过knime-serve的api直接连接到服务器上,可以下载服务器上的节点到KAP分析平台上,它就根据用户在服务上使用的节点频率进行节点推荐,但它推荐的节点只是服务器本地resposity里面现有的节点。
Workspace推荐代码
源码有这么一段话
Frequency of how often the nodes were used in the workflows of your workspace.
在工作区的工作流中使用节点的频率。
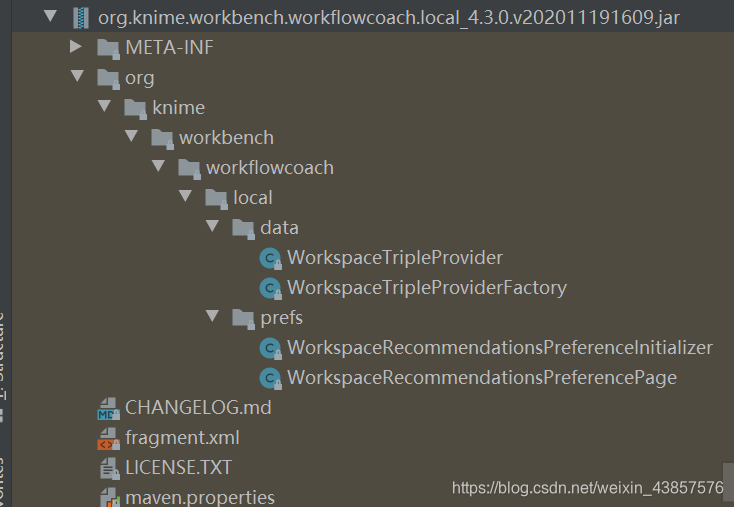
这部分代码是获取节点频率的
return NodeFrequencies.from(Files.newInputStream(WORKSPACE_NODE_TRIPLES_JSON_FILE)).getFrequencies().stream();
worksapce的节点使用率存在了一个名为workspace_recommendations.json的json文件内,每次更新最自动根据KNIME的工作空间(D:\Users\nn\knime-workspace.metadata\knime)路径找到这个文件,并对其更新,在KAP平台上拖动节点,work coach会自动根据最新的json数据来进行节点推荐。
static {PREFS = new ScopedPreferenceStore(InstanceScope.INSTANCE, FrameworkUtil.getBundle(WorkspaceTripleProvider.class).getSymbolicName());WORKSPACE_NODE_TRIPLES_JSON_FILE = Paths.get(KNIMEConstants.getKNIMEHomeDir(), "workspace_recommendations.json");
}
community推荐机制代码
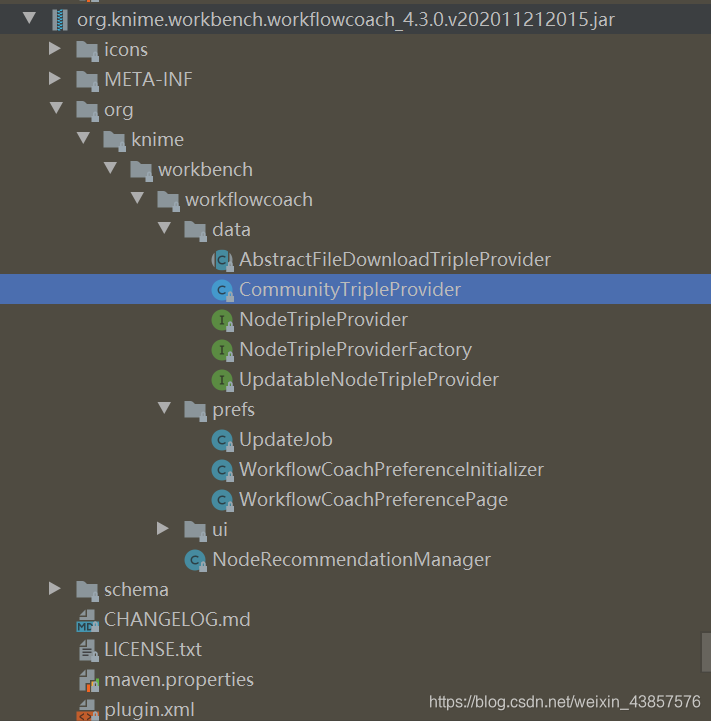
CommunityTripleProvider.java
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//package org.knime.workbench.workflowcoach.data;import java.util.Collections;
import java.util.List;
import org.eclipse.core.runtime.preferences.InstanceScope;
import org.eclipse.ui.preferences.ScopedPreferenceStore;
import org.osgi.framework.FrameworkUtil;public class CommunityTripleProvider extends AbstractFileDownloadTripleProvider {private static final ScopedPreferenceStore PREFS;static {PREFS = new ScopedPreferenceStore(InstanceScope.INSTANCE, FrameworkUtil.getBundle(CommunityTripleProvider.class).getSymbolicName());}public CommunityTripleProvider() {super("https://update.knime.com/community_recommendations.json", "community_recommendations.json");}public String getName() {return "Community";}public String getDescription() {return "Frequency of how often the KNIME community used this node.";}public boolean isEnabled() {return PREFS.getBoolean("community_node_triple_provider");}public static final class Factory implements NodeTripleProviderFactory {public Factory() {}public List<NodeTripleProvider> createProviders() {return Collections.singletonList(new CommunityTripleProvider());}public String getPreferencePageID() {return "org.knime.workbench.workflowcoach";}}
}上面代码社区的推荐代码,可以看到推荐的原理是我们请求一个url,这个url返回一个json数据,这个数据是最近社区一些节点的使用频率
private static void fillRecommendationsMap(Map<String, List<NodeRecommendationManager.NodeRecommendation>> recommendationMap, NodeTriple nf) {if (!nf.getNode().isPresent() && !nf.getPredecessor().isPresent() && isSourceNode(nf.getSuccessor())) {add(recommendationMap, "<source_nodes>", nf.getSuccessor(), nf.getCount());}if (!nf.getPredecessor().isPresent() && nf.getNode().isPresent() && isSourceNode((NodeInfo)nf.getNode().get())) {add(recommendationMap, "<source_nodes>", (NodeInfo)nf.getNode().get(), nf.getCount());}if (nf.getNode().isPresent()) {add(recommendationMap, getKey((NodeInfo)nf.getNode().get()), nf.getSuccessor(), nf.getCount());}if (nf.getPredecessor().isPresent() && nf.getNode().isPresent()) {add(recommendationMap, getKey((NodeInfo)nf.getPredecessor().get()) + "#" + getKey((NodeInfo)nf.getNode().get()), nf.getSuccessor(), nf.getCount());}}
实验
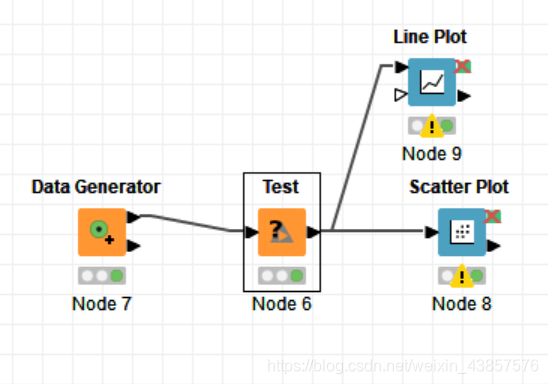
这里我新建一个流程,其中Data Generator为社区的节点,其功能为数字生成器,Test是我自己自定义开发的节点,其功能是可以调整数据保留几位小数。后面两个分别是画直线图和散点图。
一开始我把在eclipse上自定义开发的节点达成jar包放到knime安装目录下的dropin目录下,这样打开KNIME分析平台就可以看到这个节点了。但是当选中此节点时,此时的workflow coach没有任何推荐的节点,我们执行这个流程并保存。
打开workflow coach配置,点击更新,此时会下载更新一个名为workspace_recommendations.json。里面存储了当前工作区每个节点使用的频率。
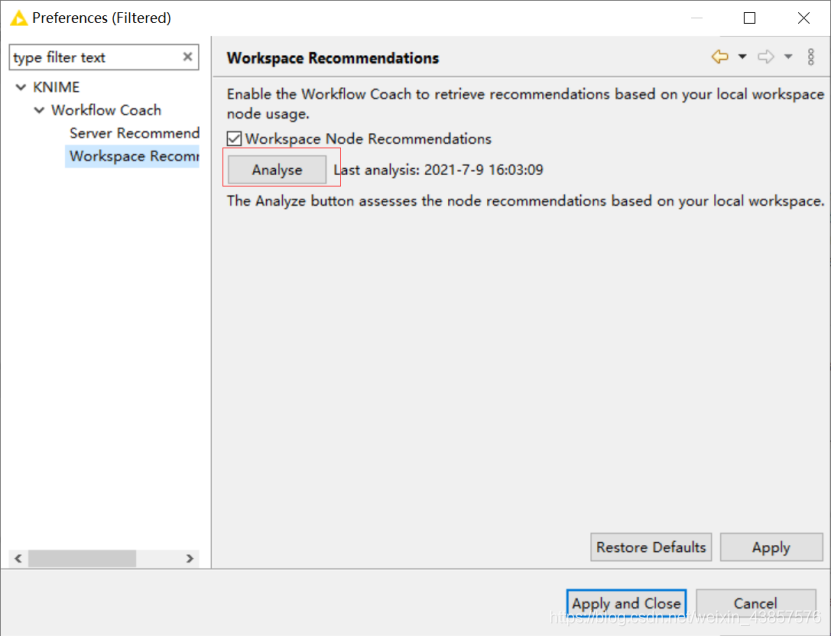
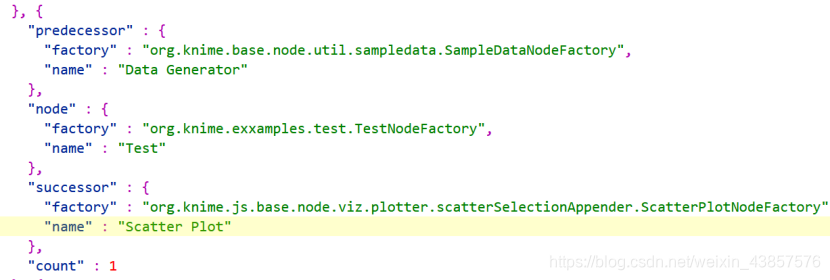
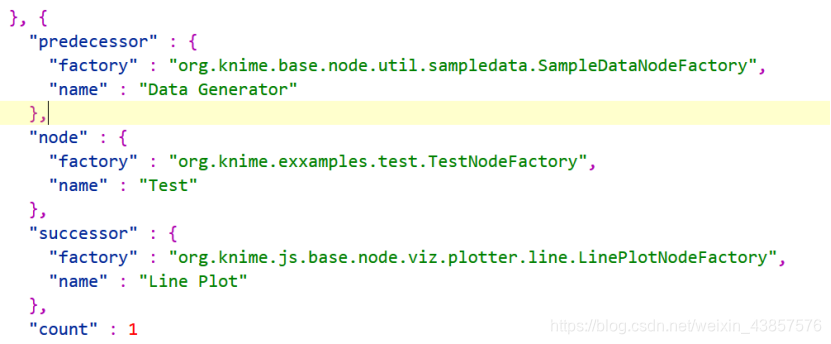
可以看到Test节点的前驱为Data Generator,后继为Scatter Plot和Line Plot
此时再查看workflow coach
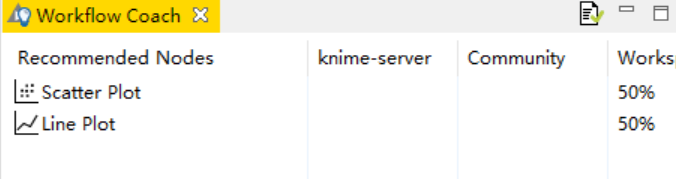
可以看出Scatter Plot和Line Plot分别为50%,同理社区的节点推荐元也是如此,不过这个每次更新都能远程下载一个节点使用频率的json文件,还有在工作区上,分析平台时如何监视节点的,并算出频率的,这些问题还有待研究。
这篇关于深究KNIME分析平台上的节点是如何实现推荐原理的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





