本文主要是介绍SSD硬盘读写原理|FTL|TRIM|写入放大效应,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
大家好,我是jiantaoyab,本篇文章我们来看看SSD硬盘和FTL、磨损均衡,SSD 硬盘,适合读多写少的应用,使用寿命受限于可以擦除的次数。
SSD 的读写原理
SSD 没有像机械硬盘那样的寻道过程,所以它的随机读写都更快。
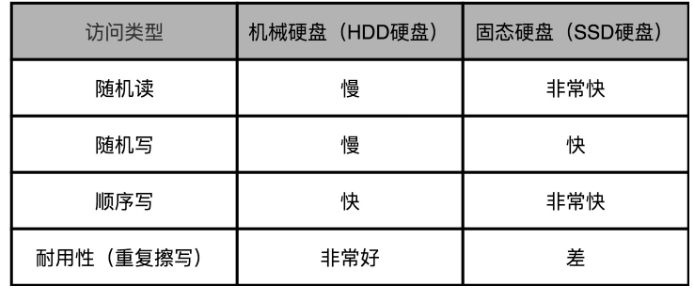
机械硬盘要远强于 SSD,那就是耐用性。如果我们需要频繁地重复写入删除数据,那么机械硬盘要比 SSD 性价比高很多。
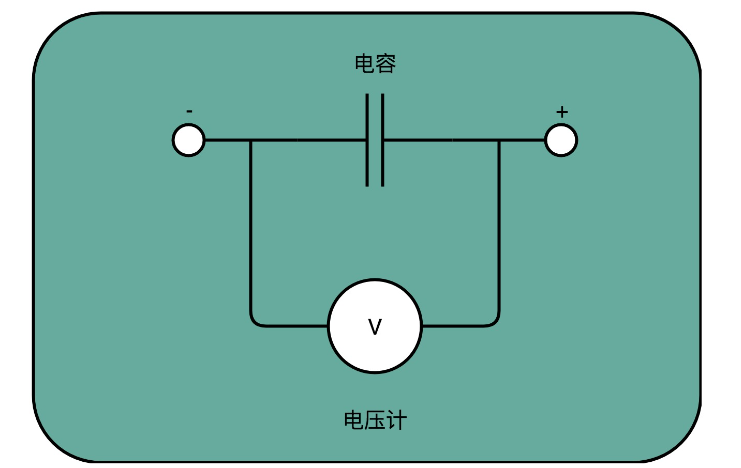
CPU Cache 用的 SRAM 是用一个电容来存放一个比特的数据。对于 SSD 硬盘,也可以先简单地认为,它是由一个电容加上一个电压计组合在一起,记录了一个或者多个比特。
SLC、MLC、TLC 和 QLC
记录一个比特,给电容里面充上电有电压的时候就是 1,给电容放电里面没有电就是 0。
采用这样方式存储数据的 SSD 硬盘,我们一般称之为使用了 SLC 的颗粒,全称是 Single-Level Cell,也就是一个存储单元中只有一位数据。
但是,这样的方式会遇到和 CPU Cache 类似的问题,那就是,同样的面积下,能够存放下的元器件是有限的。如果只用 SLC,就会遇到,存储容量上不去,并且价格下不来的问题。于是硬件工程师们就陆续发明了MLC(Multi-Level Cell)、TLC(Triple-Level Cell)以及QLC(Quad-Level Cell),也就是能在一个电容里面存下 2 个、3 个乃至 4 个比特。
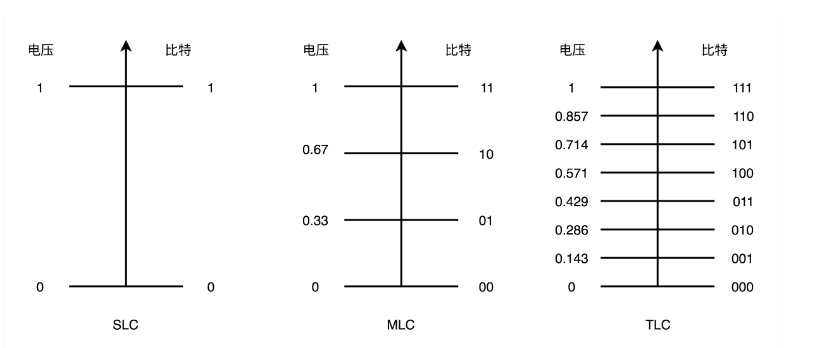
只有一个电容,我们怎么能够表示更多的比特呢?
电压计,4 个比特一共可以从 0000-1111 表示 16 个不同的数。那么,如果能往电容里面充电的时候,充上 15 个不同的电压,并且我们电压计能够区分出这 15 个不同的电压。加上电容被放空代表的 0,就能够代表从 0000-1111 这样 4 个比特了。
不过,要想表示 15 个不同的电压,充电和读取的时候,对于精度的要求就会更高。这会导致充电和读取的时候都更慢,所以 QLC 的 SSD 的读写速度,要比 SLC 的慢上好几倍。
P/E 擦写问题
SSD 硬盘的硬件构造
1.接口和控制电路。 SSD 硬盘用的是 SATA 或者 PCI Express 接口。
在控制电路里,有一个很重要的模块,叫作FTL(Flash-Translation Layer),也就是闪存转换层。这个可以说是 SSD 硬盘的一个核心模块,SSD 硬盘性能的好坏,很大程度上也取决于FTL算法好不好。
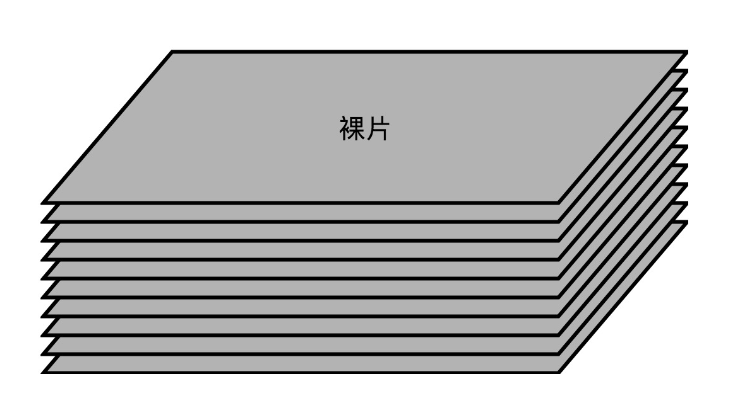
2.实际 I/O 设备,它其实和机械硬盘很像。现在新的大容量 SSD 硬盘都是 3D 封装的了,也就是说,是由很多个裸片(Die)叠在一起的,就好像我们的机械硬盘把很多个盘面(Platter)叠放再一起一样,这样可以在同样的空间下放下更多的容量。
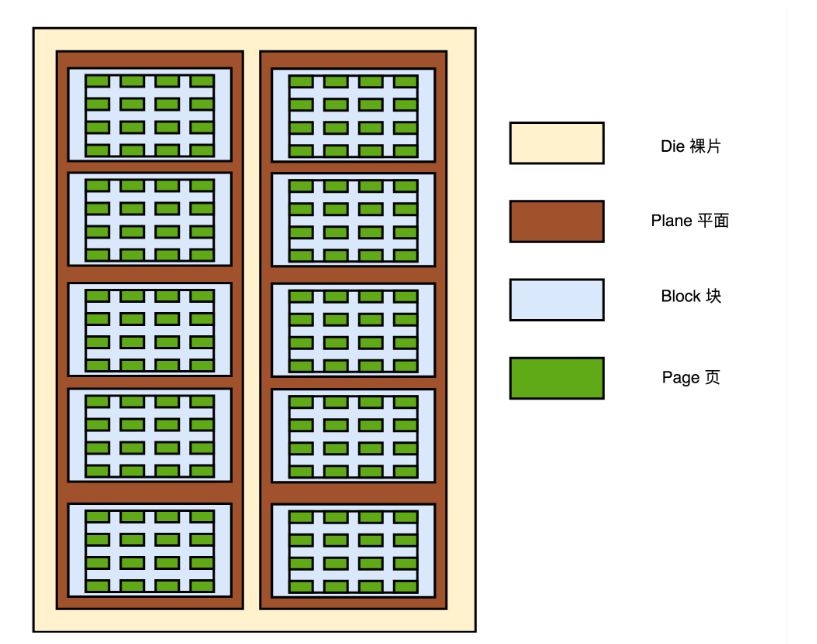
一张裸片上可以放多个平面(Plane),一般一个平面上的存储容量大概在 GB 级别。
一个平面上面,会划分成很多个块,一般一个块(Block)的存储大小, 通常几百 KB 到几 MB 大小。一个块里面,还会区分很多个页(Page),就和我们内存里面的页一样,一个页的大小通常是 4KB。
在这一层一层的结构里面,处在最下面的两层块和页非常重要。
对于 SSD 硬盘来说,数据的写入叫作 Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先去擦除(Erase),然后再写入。
SSD 的读取和写入的基本单位,不是一个比特(bit)或者一个字节(byte),而是一个页(Page)。SSD 的擦除单位就更夸张了,我们不仅不能按照比特或者字节来擦除,连按照页来擦除都不行,我们必须按照块来擦除。
SSD 的使用寿命,其实是每一个块(Block)的擦除的次数。SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而 TLC 和 QLC 就只在几千次了。这也是为什么同样的硬盘容量的价格差别很大,因为它们的芯片颗粒和寿命完全不一样。
SSD 读写的生命周期
下面我们来实际看一看,一块 SSD 硬盘在日常是怎么被用起来的。
用三种颜色分别来表示 SSD 硬盘里面的页的不同状态,白色代表这个页从来没有写入过数据,绿色代表里面写入的是有效的数据,红色代表里面的数据,在操作系统看来已经是删除的了。
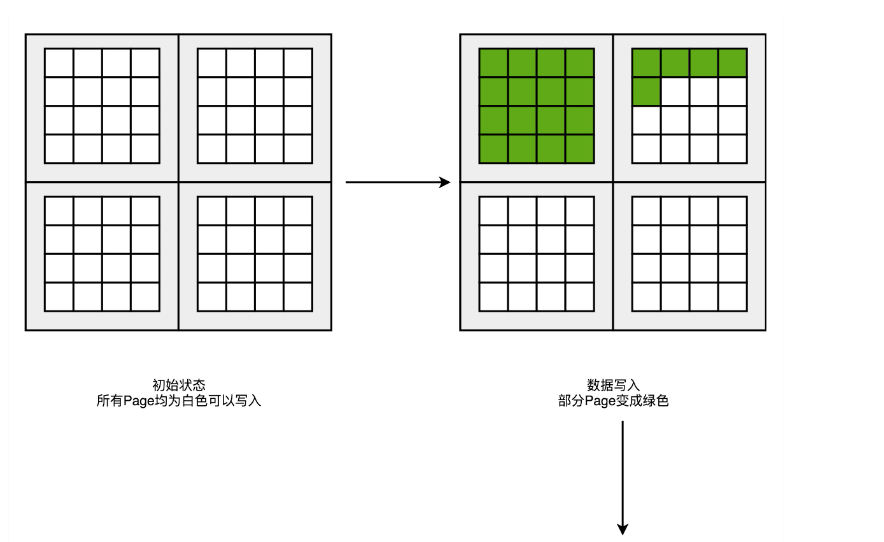
一开始所有块的每一个页都是白色的。随着开始往里面写数据,里面的有些页就变成了绿色。
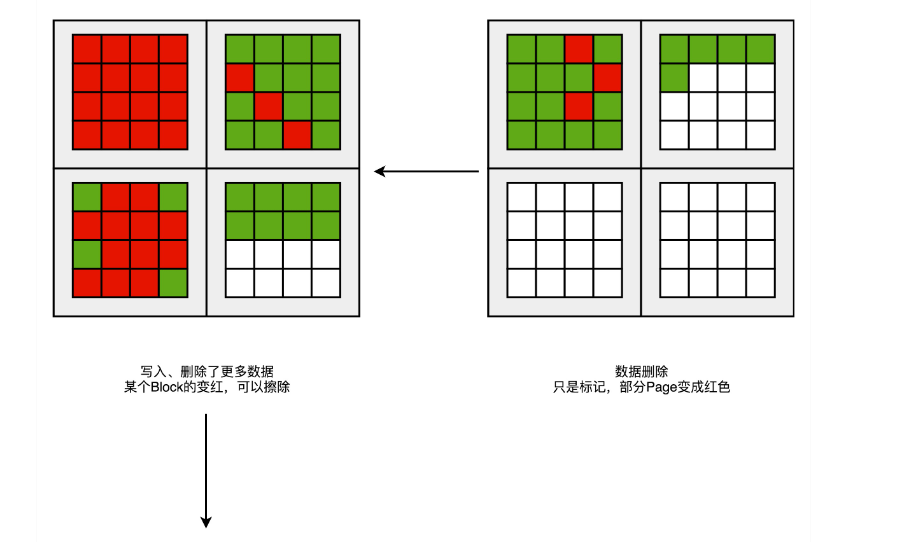
然后,因为删除了硬盘上的一些文件,所以有些页变成了红色。但是这些红色的页,并不能再次写入数据。因为 SSD
硬盘不能单独擦除一个页,必须一次性擦除整个块,所以新的数据,只能往后面的白色的页里面写。这些散落在各个绿色空间里面的红色空洞,就好像硬盘碎片。如果有哪一个块的数据一次性全部被标红了,那我们就可以把整个块进行擦除。它就又会变成白色,可以重新一页一页往里面写数据。这种情况其实也会经常发生。毕竟一个块不大,也就在几百
KB 到几 MB。删除一个几 MB 的文件,数据又是连续存储的,自然会导致整个块可以被擦除。随着硬盘里面的数据越来越多,红色空洞占的地方也会越来越多。于是就要没有白色的空页去写入数据了。这个时候,要做一次类似于 Windows
里面“磁盘碎片整理”或者 Java
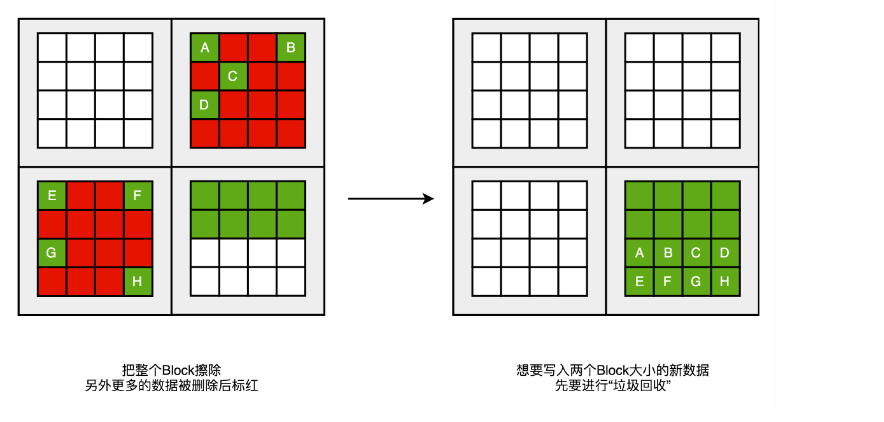
里面的“内存垃圾回收”工作。找一个红色空洞最多的块,把里面的绿色数据,挪到另一个块里面去,然后把整个块擦除,变成白色,可以重新写入数据。
不过,这个“磁盘碎片整理”或者“内存垃圾回收”的工作,不能太主动、太频繁地去做。因为 SSD 的擦除次数是有限的。如果动不动就搞个磁盘碎片整理,那么 SSD 硬盘很快就会报废了。
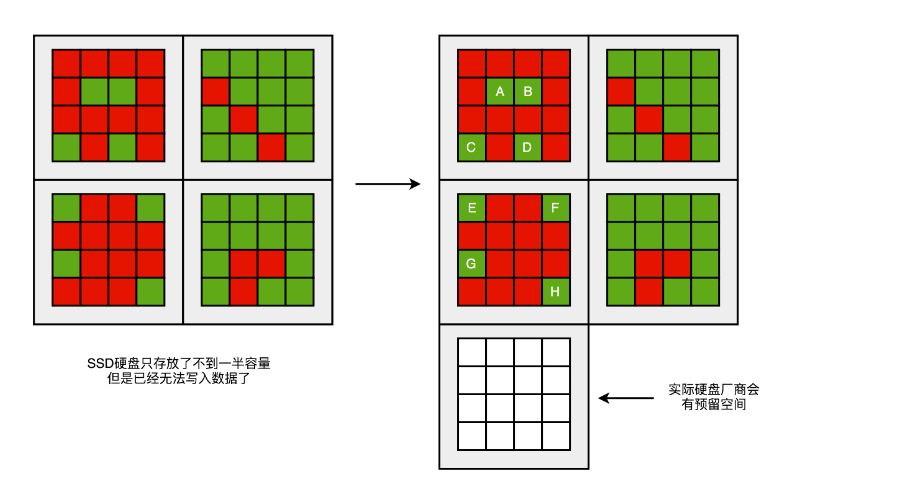
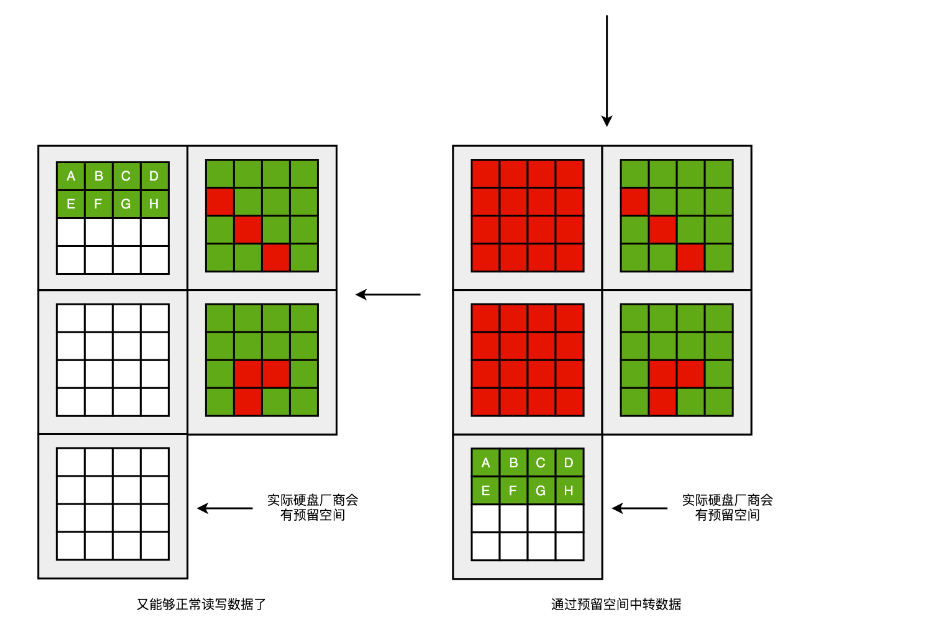
一块 SSD 的硬盘容量,是没办法完全用满的。不过,生产 SSD 硬盘的厂商,其实是预留了一部分空间,专门用来做这个“磁盘碎片整理”工作的。一块标成 240G 的 SSD 硬盘,往往实际有 256G 的硬盘空间。SSD 硬盘通过控制芯片电路,把多出来的硬盘空间,用来进行各种数据的闪转腾挪,让你能够写满那 240G 的空间。这个多出来的 16G 空间,叫作预留空间(Over Provisioning),一般 SSD 的硬盘的预留空间都在 7%-15% 左右。
磨损均衡、TRIM 和写入放大效应
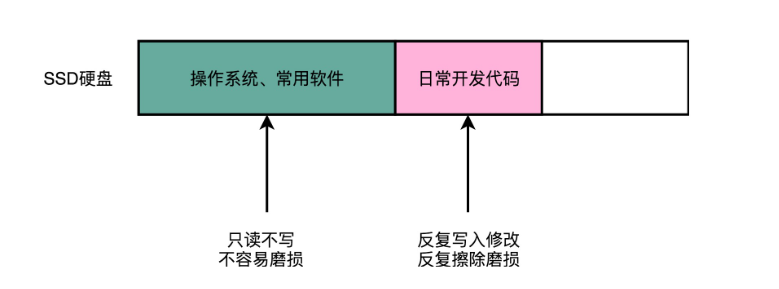
在 Windows 电脑上,用了 SSD 的系统盘,就不能用磁盘碎片整理功能。这是因为,一旦主动去运行磁盘碎片整理功能,就会发生一次块的擦除,对应块的寿命就少了一点点。这个 SSD 的擦除寿命的问题,不仅会影响像磁盘碎片整理这样的功能,其实也很影响我们的日常使用。
操作系统上,并没有 SSD 硬盘上各个块目前已经擦写的情况和寿命,所以它对待 SSD 硬盘和普通的机械硬盘没有什么区别。
一旦开始开发,我们就会不断添加新的代码文件,还会不断修改已经有的代码文件。因为 SSD 硬盘没有覆写(Override)的功能,所以,这个过程中,其实我们是在反复地写入新的文件,然后再把原来的文件标记成逻辑上删除的状态。等 SSD 里面空的块少了,我们会用“垃圾回收”的方式,进行擦除。有一天,这些块的擦除次数到了,变成了坏块。这块硬盘的可以用的容量就变小了。
FTL 和磨损均衡
让 SSD 硬盘各个块的擦除次数,均匀分摊到各个块上。这个策略叫作磨损均衡(Wear-Leveling)。实现这个技术的核心办法,和虚拟内存一样,就是添加一个间接层。这个间接层,就是 FTL 这个闪存转换层。
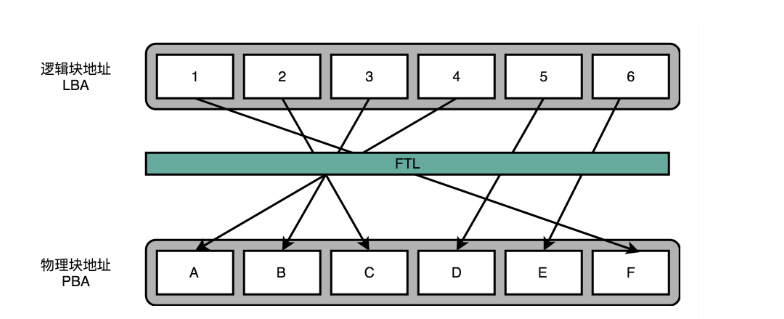
就像在管理内存的时候,通过一个页表映射虚拟内存页和物理页一样,在 FTL 里面,存放了逻辑块地址(Logical Block Address,简称 LBA)到物理块地址(Physical Block Address,简称 PBA)的映射。
操作系统访问的硬盘地址,其实都是逻辑地址。只有通过 FTL 转换之后,才会变成实际的物理地址,找到对应的块进行访问。操作系统本身,不需要去考虑块的磨损程度,只要和操作机械硬盘一样来读写数据就好了。
操作系统所有对于 SSD 硬盘的读写请求,都要经过 FTL。FTL 里面又有逻辑块对应的物理块,所以 FTL 能够记录下来,每个物理块被擦写的次数。如果一个物理块被擦写的次数多了,FTL 就可以将这个物理块,挪到一个擦写次数少的物理块上。但是,逻辑块不用变,操作系统也不需要知道这个变化。
TRIM 指令的支持
操作系统不去关心实际底层的硬件是什么,在 SSD 硬盘的使用上,也会带来一个问题是操作系统的逻辑层和 SSD 的逻辑层里的块状态,是不匹配的。
在操作系统里面去删除一个文件,其实并没有真的在物理层面去删除这个文件,只是在文件系统里面,把对应的 inode 里面的元信息清理掉,这代表这个 inode 还可以继续使用,可以写入新的数据。这个时候,实际物理层面的对应的存储空间,在操作系统里面被标记成可以写入了。
所以,其实日常的文件删除,都只是一个操作系统层面的逻辑删除。这也是为什么,很多时候我们不小心删除了对应的文件,我们可以通过各种恢复软件,把数据找回来。
同样的,这也是为什么,如果我们想要删除干净数据,需要用各种“文件粉碎”的功能才行。这个删除的逻辑在机械硬盘层面没有问题,因为文件被标记成可以写入,后续的写入可以直接覆写这个位置。
但是,在 SSD 硬盘上就不一样了。
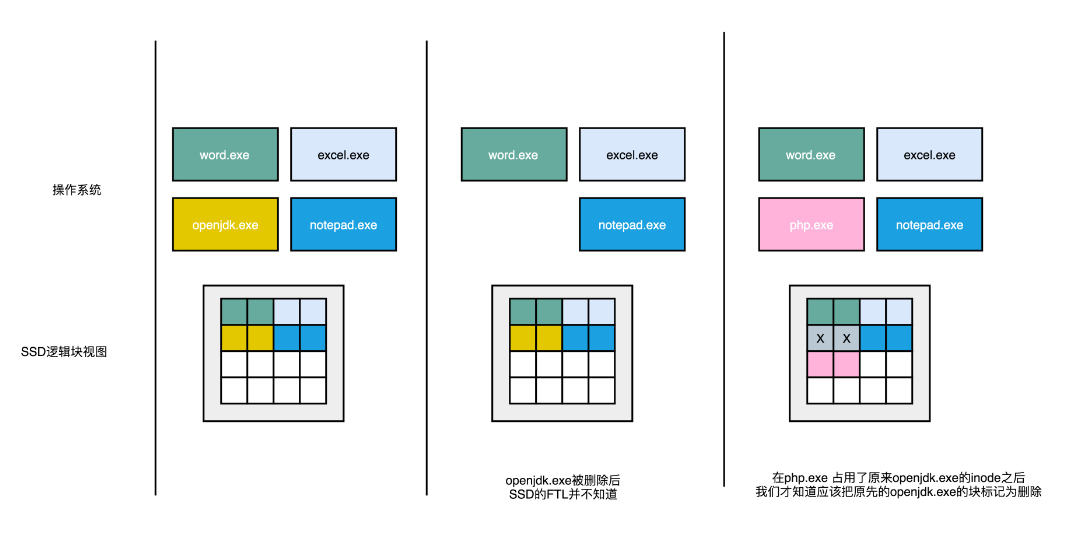
一开始,操作系统里面有好几个文件,不同的文件我用不同的颜色标记出来了。
下面的 SSD 的逻辑块里面占用的页,也用同样的颜色标记出来文件占用的对应页。
在操作系统里面,删除掉一个刚刚下载的文件,比如标记成黄色 openjdk.exe 这样一个 jdk 的安装文件,在操作系统里面,对应的
inode 里面,就没有文件的元信息。但是这个时候, SSD 的逻辑块层面,其实并不知道这个事情。所以在,逻辑块层面,openjdk.exe
仍然是占用了对应的空间。对应的物理页,也仍然被认为是被占用了的。这个时候,如果我们需要对 SSD 进行垃圾回收操作,openjdk.exe 对应的物理页,仍然要在这个过程中,被搬运到其他的 Block
里面去。只有当操作系统在刚才的 inode 里面写入数据的时候,才会知道原来的些黄色的页,其实都已经没有用了,我们才会把它标记成废弃掉。所以,在使用 SSD 的硬盘情况下,会发现,操作系统对于文件的删除,SSD
硬盘其实并不知道。这就导致,为了磨损均衡,很多时候在都在搬运很多已经删除了的数据。这就会产生很多不必要的数据读写和擦除,既消耗了 SSD
的性能,也缩短了 SSD 的使用寿命。
为了解决这个问题,现在的操作系统和 SSD 的主控芯片,都支持TRIM 命令。
这个命令可以在文件被删除的时候,让操作系统去通知 SSD 硬盘,对应的逻辑块已经标记成已删除了。现在的 SSD 硬盘都已经支持了 TRIM 命令。无论是 Linux、Windows 还是 MacOS,这些操作系统也都已经支持了 TRIM 命令了。
写入放大
其实,TRIM 命令的发明,也反应了一个使用 SSD 硬盘的问题,那就是,SSD 硬盘容易越用越慢。
当 SSD 硬盘的存储空间被占用得越来越多,每一次写入新数据,我们都可能没有足够的空白。我们可能不得不去进行垃圾回收,合并一些块里面的页,然后再擦除掉一些页,才能匀出一些空间来。
这个时候,从应用层或者操作系统层面来看,我们可能只是写入了一个 4KB 或者 4MB 的数据。但是,实际通过 FTL 之后,我们可能要去搬运 8MB、16MB 甚至更多的数据。
我们通过“实际的闪存写入的数据量 / 系统通过 FTL 写入的数据量 = 写入放大”,可以得到,写入放大的倍数越多,意味着实际的 SSD 性能也就越差,会远远比不上实际 SSD 硬盘标称的指标。
而解决写入放大,需要我们在后台定时进行垃圾回收,在硬盘比较空闲的时候,就把搬运数据、擦除数据、留出空白的块的工作做完,而不是等实际数据写入的时候,再进行这样的操作。
AeroSpike:如何最大化 SSD 的使用效率?
AeroSpike 操作 SSD 硬盘,并没有通过操作系统的文件系统。而是直接操作 SSD 里面的块和页。因为操作系统里面的文件系统,对于 KV 数据库来说,只是让我们多了一层间接层,只会降低性能,对我们没有什么实际的作用。
其次,AeroSpike 在读写数据的时候,做了两个优化。在写入数据的时候,AeroSpike 尽可能去写一个较大的数据块,而不是频繁地去写很多小的数据块。这样,硬盘就不太容易频繁出现磁盘碎片。并且,一次性写入一个大的数据块,也更容易利用好顺序写入的性能优势。AeroSpike 写入的一个数据块,是 128KB,远比一个页的 4KB 要大得多。
另外,在读取数据的时候,AeroSpike 倒是可以读取 512 字节(Bytes)这样的小数据。因为 SSD 的随机读取性能很好,也不像写入数据那样有擦除寿命问题。而且,很多时候我们读取的数据是键值对里面的值的数据,这些数据要在网络上传输。如果一次性必须读出比较大的数据,就会导致我们的网络带宽不够用。
因为 AeroSpike 是一个对于响应时间要求很高的实时 KV 数据库,如果出现了严重的写放大效应,会导致写入数据的响应时间大幅度变长。所以 AeroSpike 做了这样几个动作:
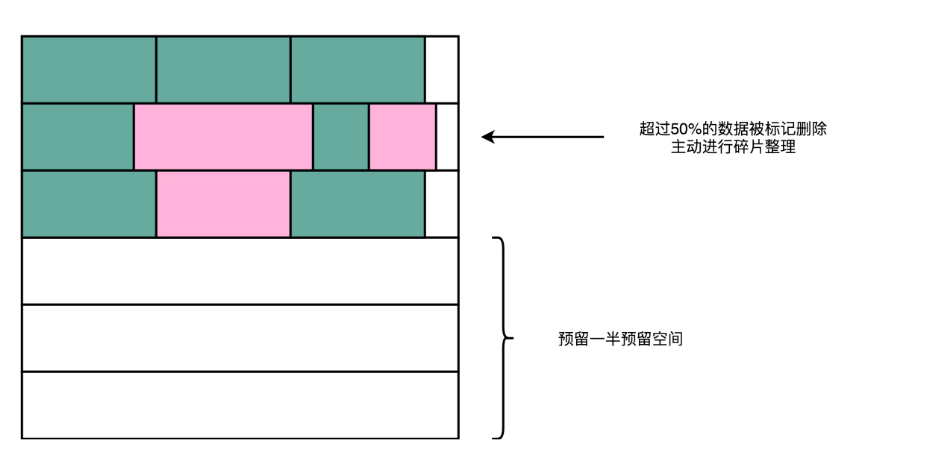
1.持续地进行磁盘碎片整理。AeroSpike 用了所谓的高水位(High Watermark)算法。其实这个算法很简单,就是一旦一个物理块里面的数据碎片超过
50%,就把这个物理块搬运压缩,然后进行数据擦除,确保磁盘始终有足够的空间可以写入。2.在 AeroSpike 给出的最佳实践中,为了保障数据库的性能,建议你只用到 SSD 硬盘标定容量的一半。也就是说,我们人为地给 SSD 硬盘预留了 50% 的预留空间,以确保 SSD 硬盘的写放大效应尽可能小,不会影响数据库的访问性能。
这篇关于SSD硬盘读写原理|FTL|TRIM|写入放大效应的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





