本文主要是介绍【从零开始学习Redis | 第七篇】认识Redis底层数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言:
动态字符串SDS:
SDS的优势:
IntSet:
IntSet的特点:
Dict:
Dict的扩容:
编辑
Dict的收缩:
Rehash:
Dict的特点:
总结:
前言:
在现代软件开发中,数据存储和处理是至关重要的一环。为了高效地管理数据,并实现快速的读写操作,各种数据库技术应运而生。其中,Redis作为一种高性能的内存数据库,广泛应用于缓存、会话存储、消息队列等场景。要深入了解Redis的工作原理,就必须先了解其底层数据结构。
Redis之所以能够在性能上表现出色,部分原因在于其精心设计的数据结构。这些数据结构不仅简单高效,而且能够满足各种复杂的数据处理需求。本文将深入探讨Redis底层数据结构的设计原理,包括字符串、哈希、列表、集合、有序集合等,希望能够帮助读者更好地理解Redis的内部机制,为进一步应用和优化Redis提供指导。

动态字符串SDS:
Redis虽然是C语言写的,但是他并没有使用C语言中的字符串,主要有以下原因:
1.获取字符串的长度需要运算,存在性能问题。
2.非二进制安全,比如我们无法存储“/0”这种字符串,因为他会被C原因认为是字符串结束的标志,从而无法读取后面的字符串内容。
3.不可修改。
所以Redis构建了一种新的字符串结构,叫做简单动态字符串(Simple Dynamic String)SDS。
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* 已经使用的字节数,不包含结束标识 */uint8_t alloc; /* buf申请的总字节数,不包含结束标识 */unsigned char flags; /*不同的SDS的头类型,用来标识头大小*/char buf[];
};这就是SDS的数据结构,但是有一个问题:我们的len的数据类型是Uint8_t,也就是说最多就只有255个字节。那么超出255个字节呢?
也就是说:其实SDS有多种类型,来保存不同字节范围大小的SDS

其实申请这么多结构类型就是为了节省空间。道理很简单:
如果我们只存储一个字节,那么使用数据类型为unit8_t的SDS肯定要比数据结构为unit64_t的SDS节省空间。

那么通过对源码的解读,我们大概可以推断出:如果要存放一个“JAVA”字符串,那么SDS结构如下:

那么我们SDS在读取字符串的时候,就不会再以“\0” 来作为字符串结束表示了,因为我们的len里面已经存储了使用字符串的长度。我们通过这种方式就避免了传统的C语言字符串无法正常存储“\0”的问题。
而SDS之所以叫做动态字符串,是因为它具有动态扩容的能力,比如我们想往上述的这个结构中,在追加一段字符串“Ni Hao”,那么因为之前的结构体已经达到了存储上限,这里首先会申请新的内存空间。
如果新字符串小于1M,则新空间为扩展后字符串长度的两位+1。
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。
这种流程称为内存预分配。
之所以要预分配,是因为申请内存需要从用户态切换到内核态,频繁的申请内存会造成很大的性能消耗,因此我们要做内存的预分配。
SDS的优势:
1.获取字符串长度的时间复杂度为1。
2.支持动态扩容。
3.减少内存分配的次数。
4.二进制安全。
IntSet:
IntSet是Redis中Set集合的一种实现方式,基于整数数组来实现,并且具有长度可变,有序等特征。IntSet底层就是一个有序的数组
typedef struct intset {uint32_t encoding;//编码方式,支持存放16,32,64位整数uint32_t length;//元素个数int8_t contents[];//整数数组,存放集合数据
} intset;
encoding包含三种模式,代表存储的整数大小不同:

为了方便查找,Redis会把IntSet中的所有整数都按照升序依次保存在数组之中,结构如图所示:
 IntSet也支持编码升级,我们用上图举例:我们上图规定了存储的元素范围必须是int16_t,也就是两个字节,那如果我们尝试向IntSet中存储50000这个超出了int16_t的范围,intset会自动升级编码到合适的大小。
IntSet也支持编码升级,我们用上图举例:我们上图规定了存储的元素范围必须是int16_t,也就是两个字节,那如果我们尝试向IntSet中存储50000这个超出了int16_t的范围,intset会自动升级编码到合适的大小。
我们来文字介绍一下上面案例的扩容过程:
1.升级编码为INSET_ENC_INT32,每个整数占四个字节,并且按照新的编码方式及元素个数扩容数组。
2.倒序将数组中的元素拷贝到扩容后的位置。
3.将待添加的元素放入到数组末尾。
这里可以讲一下为什么要倒序放入新数组:

如果我们正序扩容原数组的话,比如把占两字节的5扩容成为4字节,那么就会覆盖到后面的数据:

导致后面的正常数据被覆盖,导致无法拷贝部分数据,因此我们选择倒序扩容,这样就避免了原有数据被覆盖的问题。
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {//获取当前intset编码uint8_t curenc = intrev32ifbe(is->encoding);//获取新手机uint8_t newenc = _intsetValueEncoding(value);//获取元素个数int length = intrev32ifbe(is->length);//判断新元素大于0还是小于0,小于0插入队首,大于0插入队尾int prepend = value < 0 ? 1 : 0;//重置编码为新编码is->encoding = intrev32ifbe(newenc);//重置数组大小is = intsetResize(is,intrev32ifbe(is->length)+1);//倒序遍历,逐个搬运元素到新位置,_intsetGetEncoded按照旧编码查找旧元素while(length--)//_intsetSet按照新编码方式插入新元素_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));/* 插入新元素,prepend决定是队首还是队尾. */if (prepend)_intsetSet(is,0,value);else_intsetSet(is,intrev32ifbe(is->length),value);//修改数组长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);//返回指针return is;
}
我们来看一看是具体是如何插入一个元素的,而在如下这个代码块的红框中,也证明了Intset会去重。
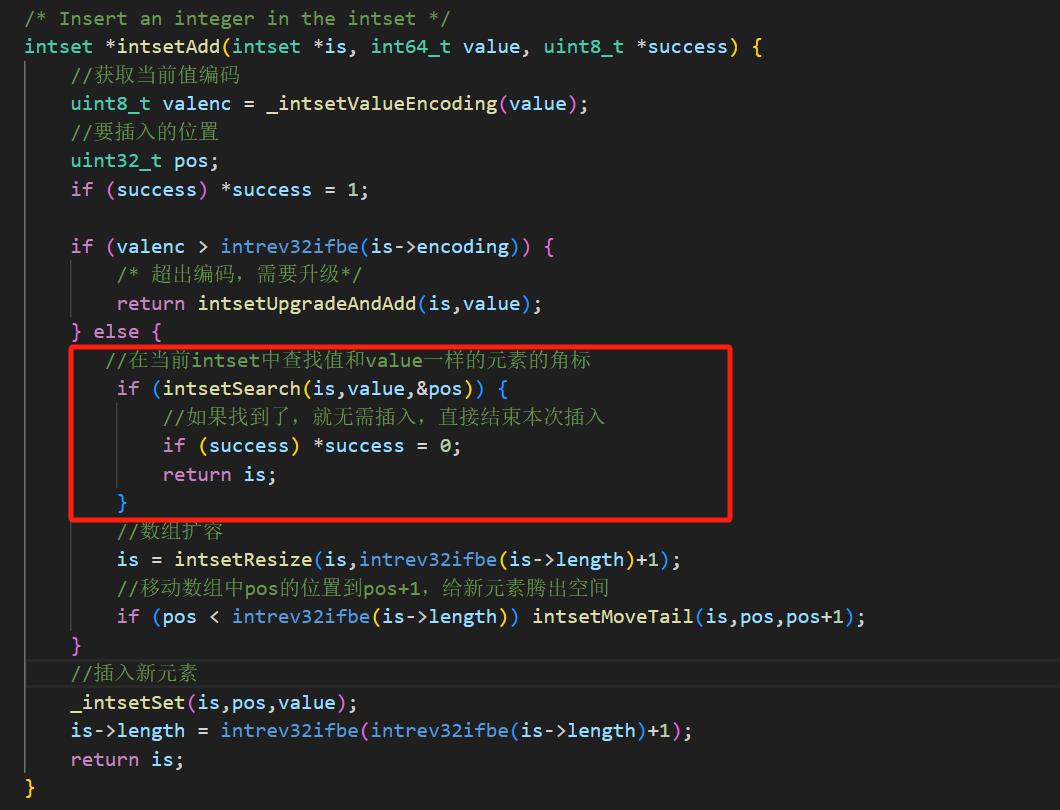
那么我们再来看一下intsetSearch是如何查找重复元素的:

相信这段代码的罗i已经很简单了,就是一个简单的二分查找。 先对特殊值进行判断,如果要搜索的value已经小于当前数组的最小值或大于当前数组的最大值,那么就直接进行插入。
之后再用二分法进行查找。
IntSet的特点:
1.Redis会确保IntSet的元素唯一,有序。
2.具备类型升级,可以节省内存空间。
3.底层采用二分法查找的方式来进行查询。
Dict:
Redis是一个键值对类型的数据库,而键和值之间的映射关系就是通过Dict这种数据类型来实现的。
Dict由三部分组成:
1.哈希节点:
struct dictEntry {//键void *key;//值union {void *val;uint64_t u64;int64_t s64;double d;} v;//下一个Entry的指针struct dictEntry *next; /* Next entry in the same hash bucket. */
};
2.哈希表:
typedef struct dictht {//Entry数组dictEntry **table;//哈希表大小unsigned long size;//哈希表大小的掩码unsigned long sizemask;//entry个数unsigned long used;
} dictht;我们可以用哈希表大小减 1 的值作为掩码,通过对哈希函数得到的值进行按位与操作,从而快速地将哈希函数的输出映射到哈希表索引范围内,即
hash_value & (size-1),其中&表示按位与操作。这种技巧能够提高哈希表的性能,因为它避免了对取模运算的使用,取代为了计算索引而进行了取模运算,只需进行了一个按位与操作,这在某些情况下能够更加高效
没理解的可以看一看我的这一篇文章:
https://liyuanxin.blog.csdn.net/article/details/134867511
https://liyuanxin.blog.csdn.net/article/details/134867511这里面介绍了HashMap是如何计算索引下标的,和这里用到的方法是一样的。
3.字典:

Dict的扩容:
Dict作为一个Hash结构的数据结构,他是通过链地址法来解决Hash冲突的。 但是当集合中元素比较多的时候,必然会导致哈希冲突的激增,链表过长导致查询效率大大降低。
因此Dict在每一次新增键值对的时候,都会检查负载因子(used/size),满足下面两种情况就会触发哈希表扩容
1.哈希表的负载因子 1,并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程。
2.哈希表的负载因子5

真正执行扩容的函数时dictExpand函数:
 如果当前哈希表正在rehash或当前哈希表大小已经大于或等于目标长度了,就不再进行扩容。
如果当前哈希表正在rehash或当前哈希表大小已经大于或等于目标长度了,就不再进行扩容。
Dict的收缩:
Dict 除了扩容之外,每次删除元素,也会对负载因子进行检查,如果负载因子小于01.,就会做哈希表收缩。
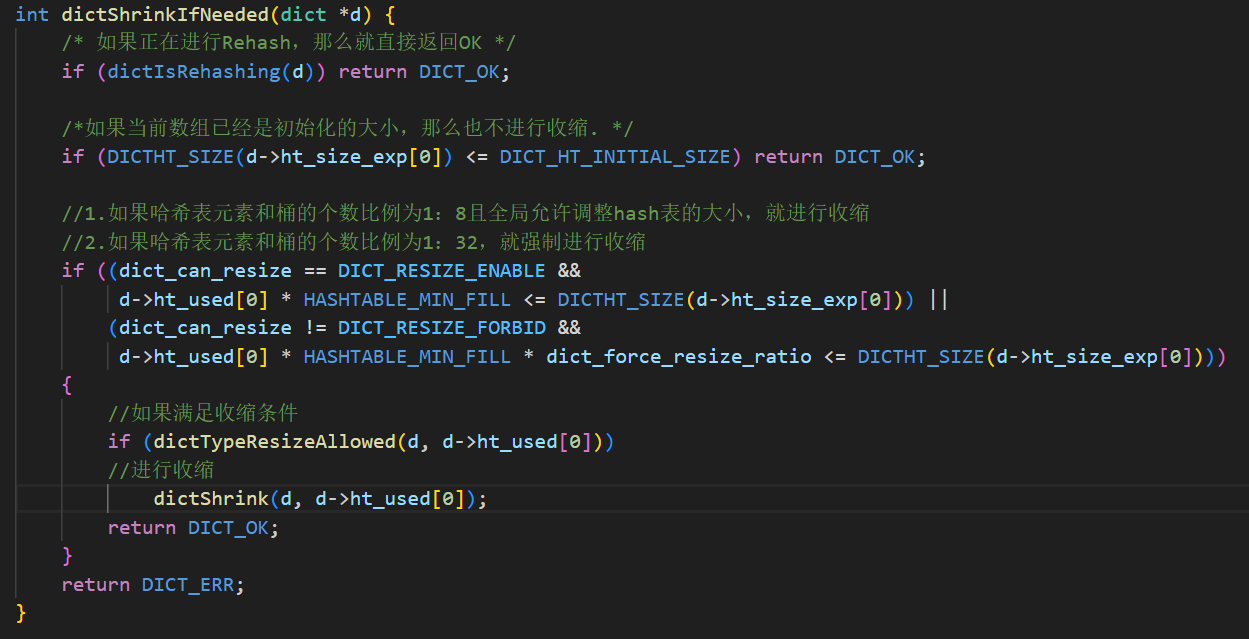
真正执行收缩的函数是dictShrink:
如果当前哈希表正在进行rehash或者已经缩小到目标size了,就拒绝再次缩小,如果满足条件,就是用_dictResize方法来缩小列表。

综合来看:其实无论是哈希表的扩容还是收缩,本质上调用的都是dict_Resize这个函数。只不过因为传入的size不同,所以最终的结果不同。
Resize中的逻辑就是将Hash数组的长度变为距离size最近的一个整数。为了求最近的二进制整数,采用了前导零的思想。
static signed char _dictNextExp(unsigned long size)
{if (size <= DICT_HT_INITIAL_SIZE) return DICT_HT_INITIAL_EXP;if (size >= LONG_MAX) return (8*sizeof(long)-1);return 8*sizeof(long) - __builtin_clzl(size-1);
}
Rehash:
无论是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询和sizemake有关。因此必须对哈希表中的key重新计算索引,插入新的哈希表,这个过程叫做rehash。流程如下:
1.重新计算新哈希表的realeSize,值取决于当前要做的是扩容还是收缩:
(1)如果是扩容,则新size等于第一个大于等于dict.ht[0].used+1的
(2)如果是收缩,则新size为第一个大于等于dict.ht[0].used的(不得小于4)
2.按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
3.设置dict.rehashidx=0,标志开始rehash
4.将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
5.将dict.ht[1]赋值给dict.ht[0],给dict[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
我们用流程图来向大家详细的介绍一遍rehash的过程:
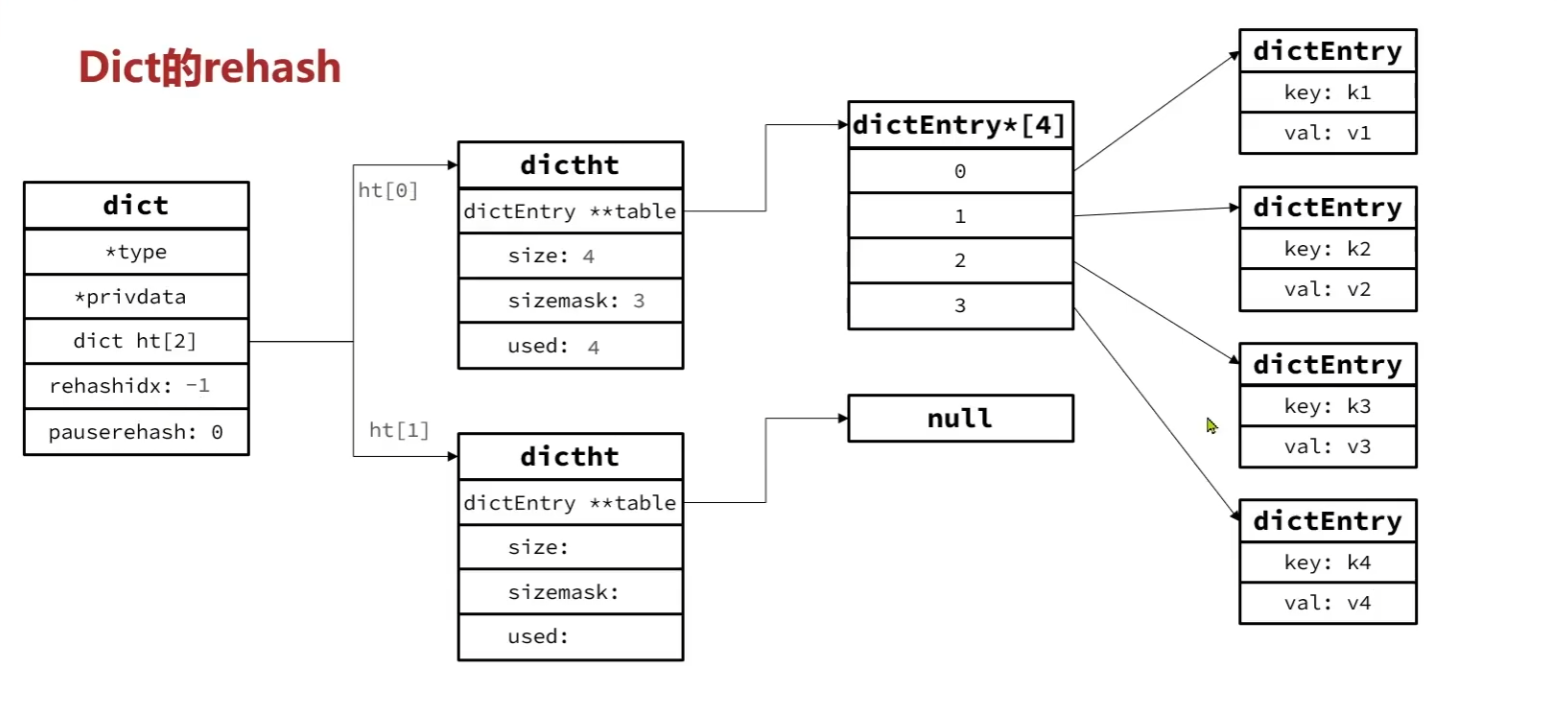
添加新元素时进行扩容:
 在ht[1]中创建扩容后的数组:
在ht[1]中创建扩容后的数组:
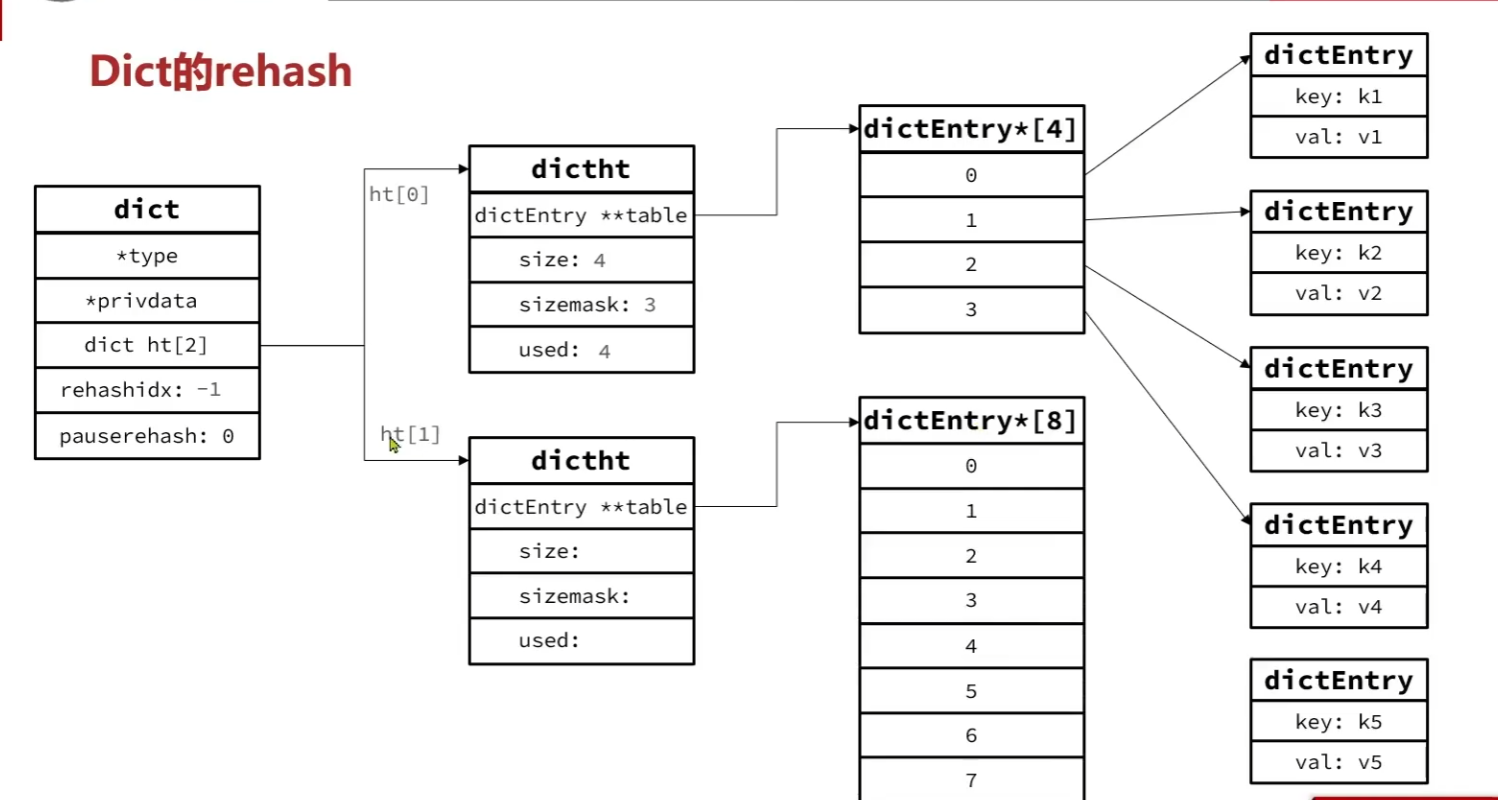 在扩容的新数组中一一建立映射关系:
在扩容的新数组中一一建立映射关系:

将ht[1]指向的数组变为ht[0]指向。

清空ht[1]中的所有数据。
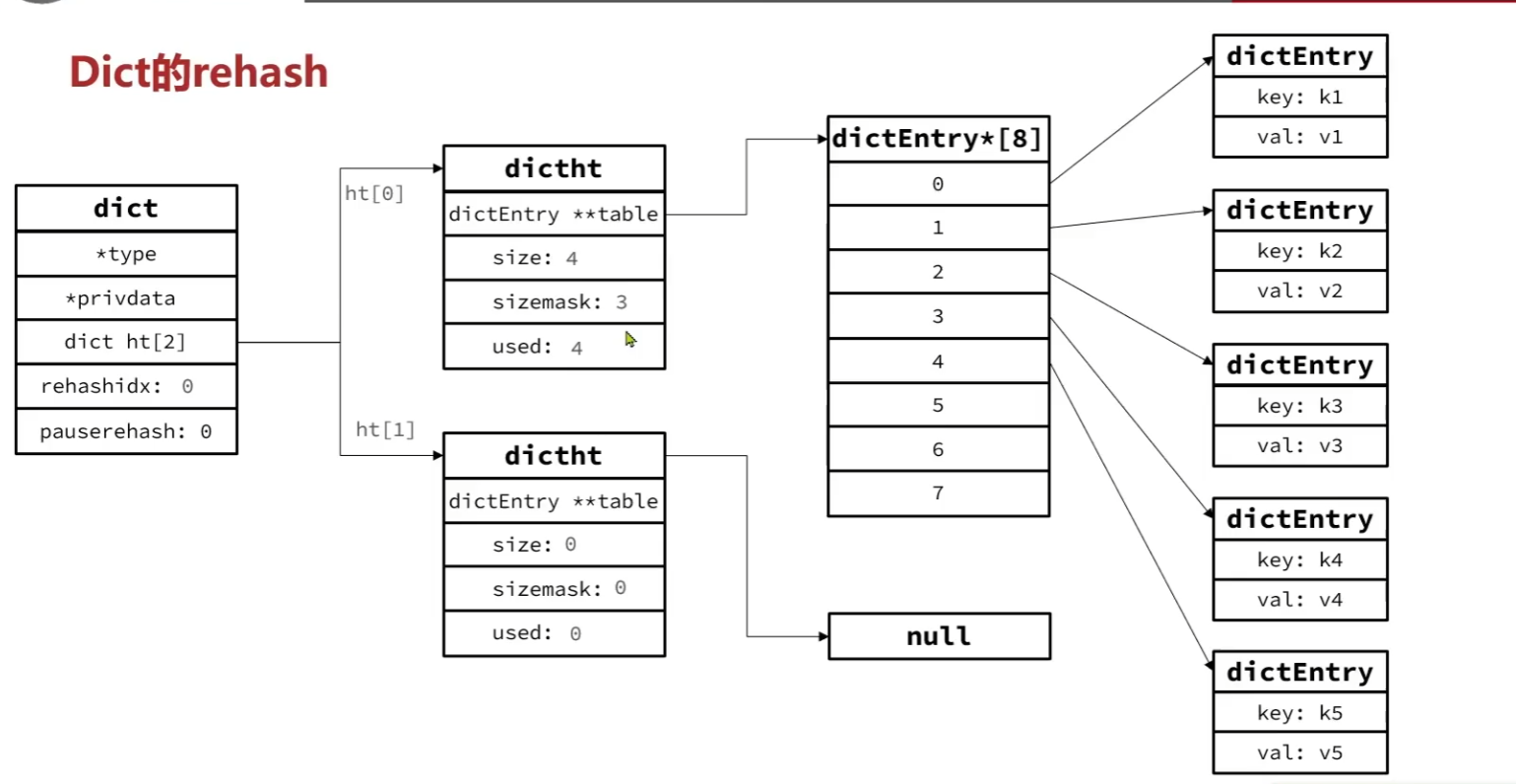
而这种方式存在一个很直接的问题:如果我们要扩容几百万的数组,那么创建数组,重新计算rehash的话,就会造成主线程阻塞,这是我们一定要避免的。
而Redis的官方为了避免这种问题,采用的是渐进式rehash。也就是分多次进行rehash完成扩容或者缩小操作。
即每一次执行新增,查询,修改,删除,操作的时候,都要检查一下rehashidx是否大于-1,如果是的话就迁移一小部分数据,直到把所有的数据都从dict.ht[0]迁移到dict.ht[1]。
Dict的特点:
1.类似java的HashMap,底层用数组+链表来解决哈希冲突。
2.Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash。
3.rehash时ht[0]只增不减,新增操作只在ht[1]中执行,其他操作在两个哈希表。
4.Dict采用渐进式Rehash,每次访问Dict的时候执行一次Rehash。
总结:
今天我们介绍了Redis的三种底层数据结构,分别是动态字符串SDS,数字集合IntSet,哈希表底层实现:Dict。
碍于篇幅原因,我们把ZipList,SkipList,RedisObject放到下一个篇中。而Redis供我们直接使用的String,list,Hash,set,Zset也会一起讲的。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!

这篇关于【从零开始学习Redis | 第七篇】认识Redis底层数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





