本文主要是介绍【论文阅读】Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、简介
- 1. 背景
- 2. 简介
- 二、方法
- 1. 任务
- 2. 模型架构
- Input Embedding
- Transformer Block
- Flow Module
- Response Generator
- 3. 训练目标
- 4. Flow Score
- 三、实验
- 1. 数据集
- 2. 实验设置
- 3. Baseline
- 回复生成
- 交互对话评估
- 4. 评价指标
- dialogue response generation
- interactive dialogue evaluation
- 四、实验结果及分析
- 1. 回复生成
- 结果
- 人类评估
- 对话的历史长度
- 消融实验
- 2. 对话评估
- 结果
- 结果分析
- Flow score
- 案例分析

ACL2021
Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances
DialoFlow模型: 建模对话动态信息流
paper地址:https://arxiv.org/pdf/2106.02227.pdf
代码地址:https://github.com/ictnlp/DialoFlow
一、简介
1. 背景
现有的建模对话历史的方法主要分为两种。一种是直接拼接对话历史,这种方法在某种程度上忽略了对话历史中跨句子的对话动态。另外一种是多层次建模,首先对每句话做表示,再对整个对话做表示,这种方法在对每句话做表示时忽略了其他句子的作用。(flat)
2. 简介
本文提出了建模对话动态信息流的方法DialoFlow,引入dynamic flow 动态流机制通过处理每个话语带来的语义影响来模拟整个对话历史中的动态信息流。
在Reddit上进行了预训练,实验表明,DialoFlow在对话生成任务(Reddit multi-reference、DailyDialog multi-reference)上明显优于DialoGPT。
此外,本文还提出了Flow score,一种基于预训练的DialoFlow的评价人机交互对话质量的有效自动度量,在DSTC9交互式对话评估数据集上的评估结果与人工评估一致性达到0.9。
二、方法
1. 任务
设 D = u 1 , u 2 , … , u N D = {u_1,u_2, …, u_N} D=u1,u2,…,uN表示整个对话。对于每一条话语 u k = u k 1 , u k 2 , … , u k T u_k= {u^1_k, u^2 _k,…, u^T _k} uk=uk1,uk2,…,ukT,其中 u k t u^t_k ukt表示第k条话语中的第t个单词。 u < k = u 1 , u 2 , … , u k − 1 u_{<k}= {u_1, u_2,…, u _{k-1}} u<k=u1,u2,…,uk−1为第k条话语的历史对话,也就是上下文 C k C_k Ck, C k + 1 C_{k+1} Ck+1和 C k C_k Ck间的差异定义为semantic influence I k I_k Ik: I k = C k + 1 − C k I_k=C_{k+1}-C_k Ik=Ck+1−Ck

DialoFlow首先对对话历史进行编码,并根据之前所有的历史上下文 C 1 C_1 C1, C 2 C_2 C2,…, C k C_k Ck预测未来的上下文 C k + 1 ′ C^{'}_{k+1} Ck+1′。然后在回复生成阶段,模型获取预测的目标语义影响 I k ′ I^{'}_{k} Ik′,并考虑预测语义影响和历史子句生成目标回复 u k u_k uk。
2. 模型架构

DialoFlow由输入embeddings、transfoemer块、单向Flow模块和回复生成器四部分组成。
Input Embedding
将token embedding、segment embedding和 position embedding的总和作为模型输入,在句末插入token “[C]”作为话语结束标记。segment embedding 包含“[Speaker1]”和“[Speaker2]”两种,来模拟说话人。
Transformer Block
使用了GPT-2里的pre-normalization
DialoFlow保持单向对话编码,在对话级别训练,而不是上下文-回复级别。可以得到由transformer block编码的第k个话语处的历史上下文:
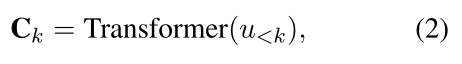
Flow Module
为了捕获对话话语中的动态信息流,本文设计了一个Flow模块来模拟语境变化。Flow模块的结构与一层transformer block相同,接受前面所有的上下文{C1,C2,…,Ck}作为输入,并预测第(k+1)条话语的上下文 C k + 1 ′ C^{'}_{k+1} Ck+1′
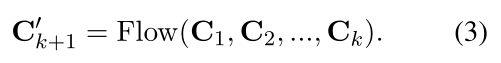
以及预测第k个话语引起的语义影响 I k ′ I^{'}_{k} Ik′
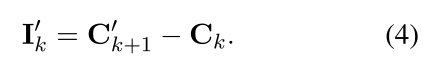
Response Generator
DialoFlow在预测语义影响 I k ′ I^{'}_{k} Ik′的指导下生成话语 u k u_k uk。回复生成器包含一个前馈层和一个softmax层,来将隐藏状态转换为tokens。在生成第t个单词时,回复生成器以预测的语义影响 I k ′ I^{'}_{k} Ik′和隐藏状态 h k t − 1 h^{t-1}_{k} hkt−1为输入,输出第t个单词的概率分布:
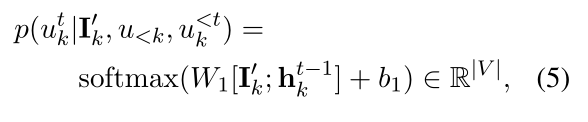
其中|V|为词汇量大小
3. 训练目标
与传统的上下文-回复的训练方法不同,DialoFlow是用包含N个话语的整个对话进行训练,相应地设计了三个训练任务来优化模型:
context flow modeling 目标是最小化预测的上下文 C k ′ C^{'}_k Ck′和真实上下文 C k C_k Ck之间的L2距离
context flow semantic influence
semantic influence modeling 用预测的语义影响 I n ′ I^{'}_{n} In′设计了一个词袋损失来建模第n个话语在上下文 C n − 1 C_{n−1} Cn−1处带来的语义影响

其中 f u k t f_{u_k^t} fukt表示话语 u k u_k uk中第t个单词 u k t u_k^t ukt的概率
response generation modeling 回复生成的目标为:

DialoFlow的整体培训目标可计算如下:
4. Flow Score
聊天机器人的话语所带来的语义影响与期望之间的差距越小,就越像人类。
本文提出了一种基于DialoFlow的交互式对话评价的自动无参考指标Flow score,当机器人生成一个新的话语 u k u_k uk时,测量 u k u_k uk所带来的预测语义影响 I k ′ I^{'}_{k} Ik′与真实语义影响 I k I_{k} Ik之间的相似度作为该话语与人类相似的概率。计算时同时度量余弦相似度和长度相似度:
引入长度相似度是为了考虑长度差异对语义相似度的影响。对于聊天机器人在对话中的整体质量,本文设计的Flow score,可以视为对话级困惑度:
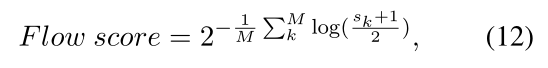
其中M为对话的回合数, ( s k + 1 ) / 2 (s_k+1)/2 (sk+1)/2是为了将相似度值缩放到[0,1]。Flow score越低,对话质量越高。
三、实验
1. 数据集
-
Reddit comments
-
Reddit Test Dataset
-
DailyDialog
-
DSTC9
2. 实验设置
-
DialoFlow基于预训练过的GPT-2进行预训练。
-
使用0.01权值衰减的AdamW优化器和12000热身步骤的linear learning rate scheduler。
-
DialoFlow-base和DialoFlow-medium的学习率是2e-4,DialoFlow-large的学习率是1e-4。
-
所有模型的批处理大小1024,DialoFlow-base和DialoFlow-medium训练4个epochs,DialoFlow-large训练2个epochs。在8个Nvidia V100 gpu上训练DialoFlow-large大约需要两个月的时间。
-
对DialoFlow-medium model 和DialoFlow-large使用 beam search(波束宽度为10),对DialoFlow-base采用贪婪搜索(和DialoGPT保持一致)
-
在DailyDialog数据集上,对预训练的DialoFlow和DialoGPT进行微调,根据validation损失选择checkpoint,然后使用beam search (with beam width 5)进行解码
3. Baseline
回复生成
DialoGPT是Reddit评论中预先训练的一个流行的对话生成模型,选择预训练的OpenAI GPT-2版本进行比较。
交互对话评估
-
FED score,自动评估指标,使用DialoGPT-large,没有任何微调或监督。FED以DialoGPT-large为用户,根据预先设置的几种常见人类话语计算后续话语的可能性,揭示对话的质量。
-
Perplexity,困惑度是用来衡量话语在对话语境下的连贯性。本文使用DialoGPT-large来测量聊天机器人每个话语的困惑度。将整个对话中所有话语的困惑度平均起来作为基线度量。
4. 评价指标
dialogue response generation
-
BLEU
-
METEOR
-
NIST,BLEU的一种变体,它通过n-gram匹配的信息增益来加权,也就是说,它间接惩罚无信息的n-gram,如“我不知道”,比BLEU更合适处理多参考测试集
-
Entropy,评估词汇多样性
使用DialoGPT使用的评估脚本。
interactive dialogue evaluation
- 计算了自动度量和人类评分之间的Pearson和Spearman相关性。
- 使用预训练的DialoFlow-large来计算本文提出的Flow score。
四、实验结果及分析
1. 回复生成
结果

在multi-reference Reddit数据集(平均历史对话长度1.45条)上对比DialoFlow和DialoGPT:
-
NIST可以有效惩罚无信息的n-gram,所以DialoGPT倾向于生成一般回复,而DialoFlow模型可以生成有更多信息的回复。
-
结果还表明,对动态流进行建模有助于提高转换质量,避免收敛于一般的回复。
-
对于词汇多样性,DialoFlow与DialoGPT在熵上表现相当。
在DailyDialog数据集(平均历史长度4.66条)上验证了长对话历史上的性能增益:
-
与DialoGPT相比,DialoFlow显示了所有模型尺寸和所有指标上的显著改进。在DailyDialog上的改进表明,DialoFlow有捕获具有很长历史的动态信息流的强大能力。
-
DailyDialog数据集上的性能改进比Reddit更显著。可能是因为Reddit里的对话主要是论坛里的评论,而DailyDialog里的对话来源于日常生活。所以DailyDialog数据集中的context flow 处于更相似的模式中,与Reddit数据集相比, semantic influences更可预测。
人类评估
使用众包对从DailyDialog测试集中随机抽取的200个案例进行人工评估。比较medium版本的DialoFlow和DialoGPT,将每组回答随机呈现给3位评委,根据relevance相关性、informativeness信息量和human-likeness人类相似性对他们进行排名。

对于DialoFlow生成的响应有很强的偏好。人的评价结果表明,对动态信息流进行建模可以有效地提高对话生成的质量。
对话的历史长度

图3显示了DialoFlow和DialoGPT在不同历史长度上的性能,DialoFlow在所有历史长度上都实现了更好的性能。当历史长度等于1时,即回复是基于一个历史语句生成时,DialoFlow也得到了显著的提升。本文将其归因于预测语义推理的指导。
消融实验
表1的消融实验显示,通过三个训练目标,DialoFlow模型在NIST和METEOR上实现了最佳性能。
-
当放弃语义影响建模任务时,性能略有下降
-
当进一步删除上下文流建模任务(这意味着端到端培训)时,性能再次下降。
结果表明,Context Influence Modeling对对话建模是有效的, Semantic Influence Modeling可以提示CIM任务。
2. 对话评估
结果

表4显示了DSTC9交互式会话数据集上不同自动度量与人类评级的聊天机器人级相关性。本文提出的Flow score 达到了Spearman correlation 0.90 (p<0.001)和Pearson correlation 0.91 (p<0.001)的强相关性。FED仅显示了Spearman correlation 为0.56 (p<0.1)的中等相关性,而且和Perplexity得分也不太相关。
也就是说:
-
Flow score 可以有效地估计聊天机器人的整体质量;
-
高相关性也表明DialoFlow模型在自然的人与人的对话中捕获了一般的动态信息流。
结果分析

表3显示了详细的人类评分、FED评分、困惑度和本文为DSTC9交互式对话评估跟踪中的11个聊天机器人和采样的人类-人类对话提出的Flow评分。良好的自动度量不仅应该在人机对话中表现良好,也应该在人机对话中表现良好,因为聊天机器人的最终目标是生成类人反应。与其他11个聊天机器人相比,FED在人对人对话中的表现较差。本文提出的Flow评分以人类与人类的对话为最佳,而人类与最佳聊天机器人之间的Flow评分差距与人类评分差距相似。
Flow score
Flow score 可以看作是话语层面上的困惑度。在自然对话中,特定语义有许多不同的表达,传统的word级别的困惑度可以评估话语的连贯性和流畅性,但在变化的表达上总是表现不稳定。而Flow评分直接度量语义相似度,减轻了传统的困惑度的问题。
案例分析

图4显示了由DialoFlow编码的人机对话的语义上下文的二维T-SNE可视化。对话可以分为四个话题:问候(1 ~ 4),谈论为什么糟糕的一天(5 ~ 13),解释看医生的可怕经历(14 ~ 18),讨论游泳(19 ~ 26)。
可以发现,随着话题的切换,语义语境流的可视化也发生了很大的变化,这表明DialoFlow能够捕获对话中的动态信息流,有效地度量每句话语所带来的语义影响。此外,不同的说话者保持着自己的context flows。
备注:
1、捕获动态信息流
DialoFlow中的Transformer Block模块构建话语级历史上下文的context flow,输入给flow module模块预测第(k+1)条消息的上下文 C k + 1 ′ C^{'}_{k+1} Ck+1′, I k ′ = C k + 1 ′ − C k I^{'}_{k}=C^{'}_{k+1}-C_k Ik′=Ck+1′−Ck表示第k个话语引起的语义影响
当第k条消息改变时,只会引起k之后消息的上下文语义变化,而不会带来k之前的上下文语义变化(图4的可视化也证明了这点),也就是文中强调的,可以捕获动态信息流(构建话语级历史上下文的context flow+捕获第k个话语带来的语义影响)。后面提出的Flow score,也用到了这里的语义影响 I I I。
2、Flow score
perplexity(困惑度)的基本思想是:当语言模型训练完之后,测试集中的句子都是正常的句子,那么给测试集的句子赋予较高概率值的语言模型较好。
PPL的计算过程如下:
对于一段句子(sentence)s由词构成,即:s=w1w2…wn, w代表词
对两边都取对数,则:
句子概率越大,语言模型越好,迷惑度越小。
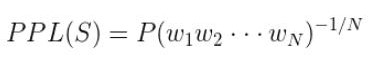
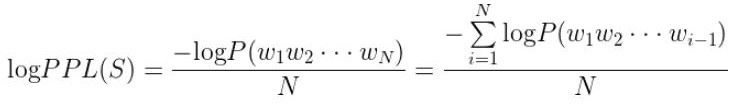
这里的flow score用相似度 s k s_k sk来类比ppl中的句子概率P,机器人生成的话语带来的语义影响与真实的语义影响越相似(相似度 s k s_k sk越高),对话质量越高,flow score就越小。
Flow score计算过程如下:
s k s_k sk表示预测语义影响 I k ′ I^{'}_{k} Ik′与真实语义影响 I k I_{k} Ik之间的相似度
M为对话的回合数,用 ( s k + 1 ) / 2 (s_k+1)/2 (sk+1)/2将相似度值和P一样缩放到[0,1]
相似度越高,对话质量越高,Flow score越小
参考:
中文信息处理实验室六篇长文被acl2021主会录用
困惑度 (Perplexity)
有帮助的话可以点个赞喔~

这篇关于【论文阅读】Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







