本文主要是介绍【论文阅读】Modeling Multi-turn Conversation with Deep Utterance Aggregation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、简介
- 二、方法
- 1.任务
- 2. 模型架构
- Utterance Representation
- Turns-aware Aggregation
- Matching Attention Flow
- Response Matching
- Attentive Turns Aggregation
- 三、实验
- 1. 数据集
- 2. 评价指标
- 3. 实验设置
- 4. 实验结果
- 四、结果分析
- 1. 实验结果分析
- 2. 注意力可视化
- 3. 消融实验.
- 4. 错误分析

DUA模型: 使用深度话语聚合建模多轮对话
paper地址:https://arxiv.org/pdf/1806.09102v2.pdf
代码地址:https://github.com/cooelf/DeepUtteranceAggregation
一、简介
基于检索的多轮对话回复选择的相关工作只是简单地将对话话语串联起来,忽略了先前话语之间的交互作用。
本文使用提出的DUA深度话语聚合模型将先前的话语转化为上下文,以形成细粒度的上下文表示,然后引入自匹配注意来传递每句话中的重要信息,对每个精细化的话语进行匹配,通过注意转向聚合得到最终的匹配分数。
实验结果表明,在三个多回合对话基准上,包括一个新引入的电子商务对话语料库,本模型优于当时现有的方法。
二、方法
1.任务
多轮对话回复检索任务中的每个会话可以描述为一个< C, R, Y >的三元组。 C = U 1 , … , U t C = {U_1,…, U_t} C=U1,…,Ut是会话上下文,{Uk}表示第k个话语。R是会话的回复,Y属于{0,1},其中 Y i = 1 Y_i= 1 Yi=1表示回复是适当的,否则 Y i = 0 Y_i= 0 Yi=0。
目标:在< C, R, Y >上建立一个鉴别器 F ( ⋅ , ⋅ ) F(·, ·) F(⋅,⋅)。对于每个上下文回复对{C, R},$ F(C, R)$度量对的匹配分数。
2. 模型架构

DUA中有五个模块:
- Utterance Representation,每一个话语或回复被输入到第一个模块,形成一个话语或回复嵌入。
- Turns-aware Aggregation,第二模块将最后一句话和前面的一句话结合起来。
- Matching Attention Flow,第三个模块过滤冗余信息,挖掘话语和回复中的显著特征。
- Response Matching,第四个模块在单词和话语两级匹配回复和每个话语,为卷积神经网络(CNN)编码成匹配向量。
- Attentive Turns Aggregation,在最后一个模块中,将匹配向量按照上下文中的话语的时间顺序传递给GRU,得到最终的匹配得分{U, R}。
优势:
- 在对话中最重要的最后一句话在前一句话中被特别融合,从而使最后一句话中的关键指导信息在语义上更加切题。
- 在每句话语中,突出的信息都能被突出,而冗余的部分在一定程度上被忽略,这两者都能有效地指导后续的回复匹配。
- 第三,经过细心的转向聚合后,再次对会话中的连接进行累积,计算匹配分数。
Utterance Representation
给定上下文回复对{C, R},其上下文被分割为话语,C = {U1,…, Ut},一个查找表用于将每个单词映射到一个低维向量。 n u n_u nu和 n r n_r nr表示第k个话语和回复的长度, U k U_k Uk、 R R R可以表示为 U k = [ u 1 , … , u n u ] Uk= [u_1,…,u_{n_u}] Uk=[u1,…,unu], R = [ r 1 , … , r n r ] R = [r1,…,r_{n_r}] R=[r1,…,rnr],其中ui, ri是话语和回复中的第i个单词。
用GRU沿着单词序列 U k U_k Uk和 R R R传递信息,对每个话语和回复进行编码,令 H k = [ h 1 , … , h n ] H_k= [h_1,…, h_n] Hk=[h1,…,hn]为输入序列的隐藏状态
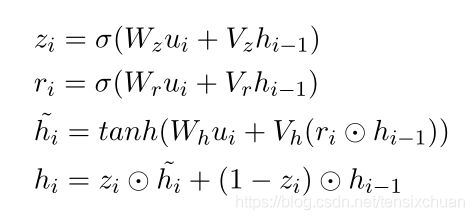
Turns-aware Aggregation
以上述方式对话语序列和回复进行编码的缺点是,会话中的所有话语都得到了公平的处理,未能挖掘出最后一句话语与前一句话语之间的联系。为此,提出了一种第一阶段的回合感知聚合机制。
S = [ S 1 , … , S t , S r ] S = [S_1,…, S_t, S_r] S=[S1,…,St,Sr]表示话语和回复的表征。假设 F = [ F 1 , … , F t , F r ] F = [F_1,…, F_t, F_r] F=[F1,…,Ft,Fr]是每个 S j ∈ S S_j∈S Sj∈S与最后一个话语 S t S_t St的融合,对于每 个 ∀ j ∈ 1 , … , r 个∀j∈{1,…, r} 个∀j∈1,…,r, F j ∈ F F_j∈F Fj∈F:
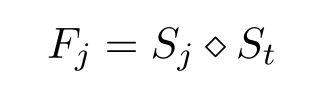
这里采用了一个简单的连接策略(串联),通过聚合得到了回合感知的表示F。
Matching Attention Flow
经过 turns-aware aggregation后,前一个话语和回复的表征由最后一个话语进行细化。然而,这些序列相当长且冗余,这使得提取关键信息变得困难。为了解决这个问题,本文采用了一种自匹配的注意机制,直接将融合的表征与自身进行匹配,动态地从输入序列中收集信息,并过滤冗余信息。输入 ˆ F = [ f 1 , … , f n ] ∈ F ˆF = [f_1,…, f_n]∈F ˆF=[f1,…,fn]∈F,输出 P = [ p 1 , … p n ] P = [p_1,…p_n] P=[p1,…pn]
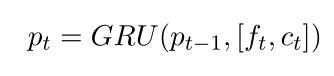
ct就是自匹配注意力的结果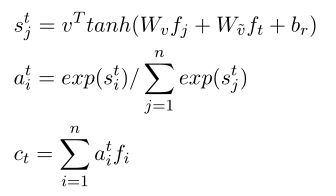
其中 v T v^T vT是随机初始化并联合训练的上下文矩阵
自匹配注意通过融合前一段和后一段话语,根据当前词和整个话语表征,从话语中定位重要部分
Response Matching
使用词语级和话语级表示构建两个匹配矩阵,并使用CNN从矩阵中获取显著匹配信息。假设我们在单词级和话语级对每个话语-回复对有匹配矩阵m1和m2。然后∀k, Uk∈U,∀(i, j)分别定义m1和m2的第(i, j)个元素:
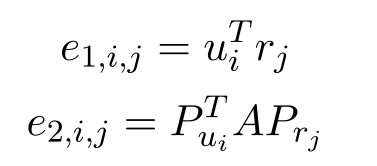
其中 p u i p_{u_i} pui和 p r j p_{r_j} prj分别表示匹配注意流后的话语输出和回复输出。 A ∈ R c × c A∈R^{c×c} A∈Rc×c是一个线性变换矩阵。
对于每一个表述,首先对M1和M2进行卷积运算,然后进行最大池化运算。卷积层用于提取和组合相邻单词的局部特征,接下来的最大池化层形成当前单词的表示。对于卷积运算,利用了一组可变大小l∗l和偏置b的滤波器矩阵K。该滤波器将单词矩阵M1和M2转换为另外两个矩阵 M 1 c M_{1c} M1c和 M 2 c M_{2c} M2c。∀i, k∈(1,2),变换矩阵 M k c M_{kc} Mkc定义为:
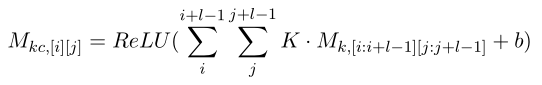
其中I和j分别指向第i行第j列的元素。接下来,采用最大池化操作,将池化后的两个矩阵扁平化并连接,得到会话中第p个话语的表示mp:
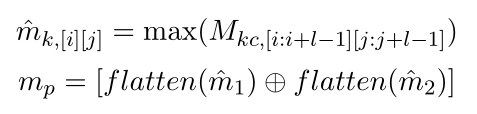
其中flatten()为扁平化运算,⊕为级联运算。
Attentive Turns Aggregation
为了对最后阶段的attentive turns 注意转向匹配信息进行聚合,CNN的输出M = [m1,…, mn],给GRU得到Hm= [hm1,…]定义为:
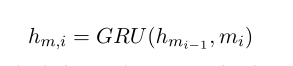
v f = L ( H m ) v_f= L(H_m) vf=L(Hm)为注意操作

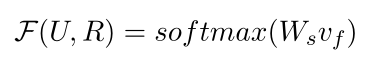
在训练阶段,根据交叉熵损失更新模型参数。
需要注意的是,Turns-aware Aggregation 回合意识聚合和Attentive Turns Aggregation注意回合聚合可以被视为话语互动的两个阶段(我们将这两个过程称为“语境融合”)。.前者是在话语表征后对更丰富的轮觉信息的简单组合,后者是在注意学习后对每个话语本身和回复的匹配状态进行聚合。
三、实验
1. 数据集
-
Ubuntu Dialogue Corpus
-
Douban Conversation Corpus
-
E-commerce Dialogue Corpus
2. 评价指标
-
Rn@k,n个候选项中k处的查全率
-
MAP ,Mean Average Precision,平均准确率。
例如,假设有两个对话,对话1有4个相关回复,对话2有5个相关回复。某系统对于对话1检索出4个相关回复,其rank分别为1, 2, 4, 7;对于对话2检索出3个相关回复,其rank分别为1,3,5。对于对话1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于对话2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。
-
MRR ,Mean Reciprocal Rank,把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
-
P@1,Precision-at-one
3. 实验设置
-
将最多的话语数限定为10个,每个话语最多包含50个单词。在必要时应用截断和零填充。
-
对训练数据进行word embedding 预训练,维数为200
-
模型是使用Theano实现的,使用ADAM进行优化
-
batch size为200,初始学习率为0.001。卷积和池化的窗口大小为(3,3),GRU的隐藏单位数设置为200。
-
所有的模型都运行在单个GPU (GeForce GTX 1080ti)上
-
运行所有的模型直到5个epoch,并选择在验证中获得最佳结果的模型
4. 实验结果
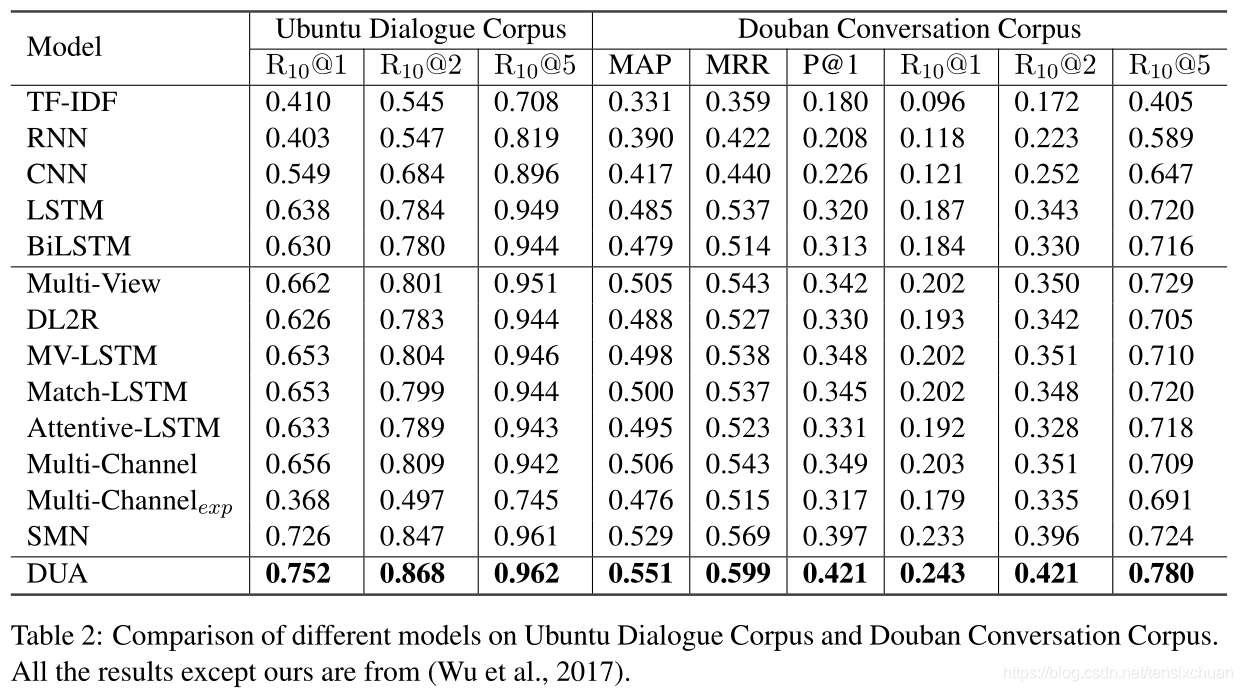
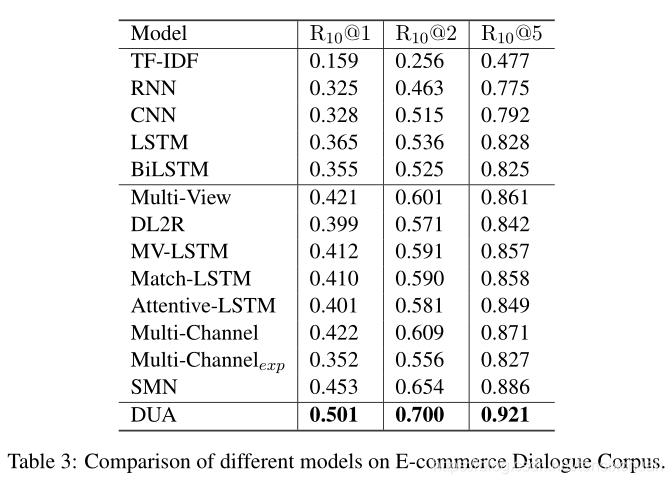
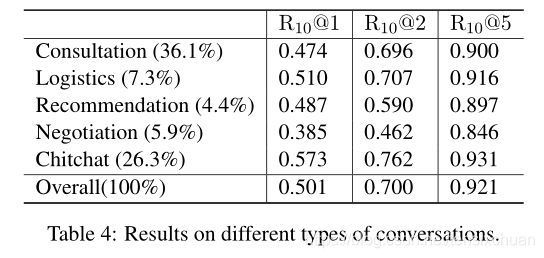
四、结果分析
1. 实验结果分析
-
以前连接话语的单个匹配模型,表现得比DUA差得多,显示话语关系的重要性和简单地将话语连接在一起并不是多轮对话建模的合适解决方案。
-
DUA与当前最先进的多轮回复匹配模型SMN相比取得了很大的进步(ECD 语料库上的 R10@1 为 4.8%),SMN匹配每个话语和回复,无需轮流感知聚合和匹配注意力流,这些比较表明本文的上下文组合方法的有效性,DUA可以很好地模仿向客户服务的真实对话,而不仅仅是擅长闲聊。
-
将ECD测试集分为5类:咨询、物流、推荐、谈判、闲聊。表4显示了统计数据和模型结果。闲聊和物流的类型往往很容易处理。建议、咨询和谈判往往涉及到不同的话题(如相关商品)和意图,相对来说更难回复,这使得本文的语料库比以往的聊天或问答语料库更具挑战性。
2. 注意力可视化
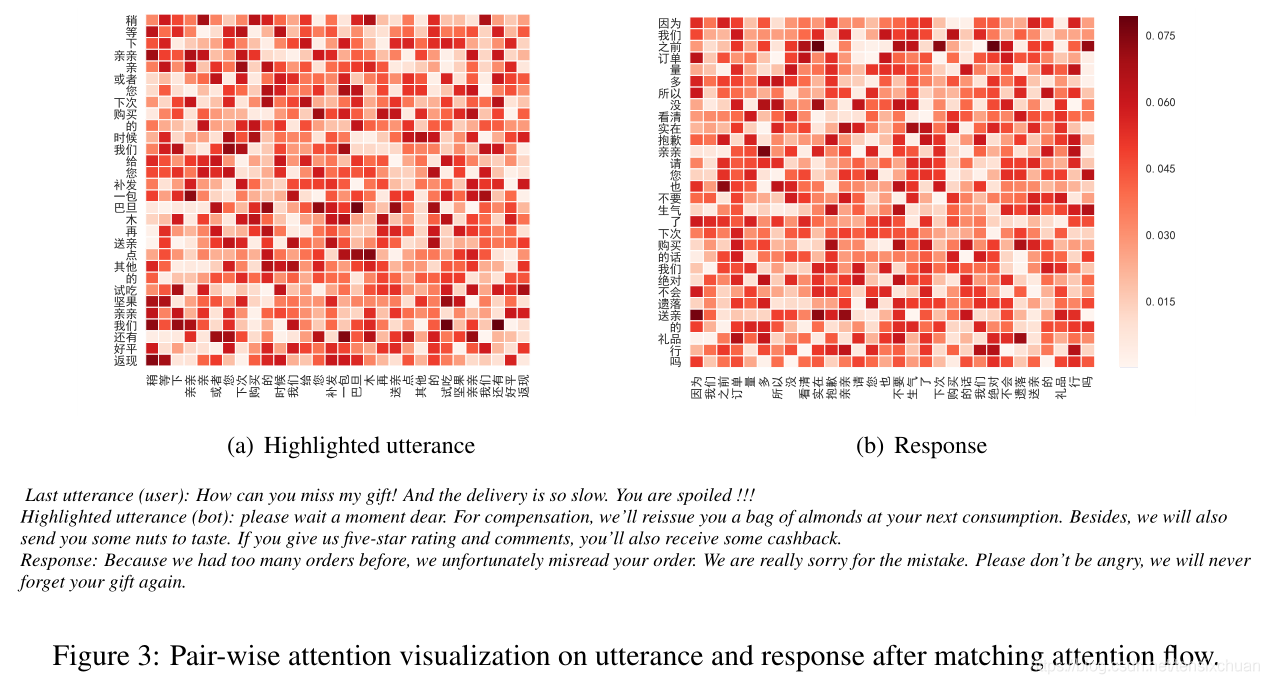
从ECD数据的验证集来看,图3分别显示了一个重要话语(在回复匹配组件中权重很高)和回复的词权值。我们看到模型可以准确的从话语中提炼出关键,{下次消费,再发,一包杏仁,送你,一些坚果,回款},并从回复{之前订单太多,真的很抱歉,别生气,你的礼物}。当用户抱怨缺少礼物、传递速度慢时,我们的模型能够在自匹配后区分用户的意图,并根据所呈现话语的症结本质上寻找合适的回应。这说明我们的模型在匹配注意流后的关键点选择上是有效的,可以引导回复匹配层收集更多的相关片段。
3. 消融实验.
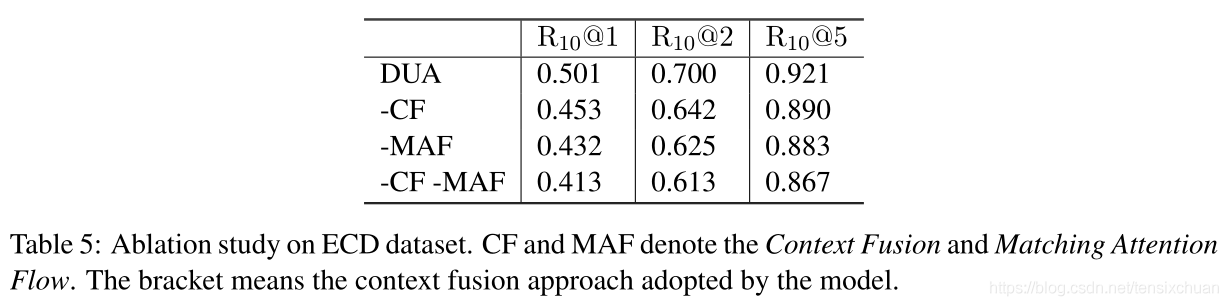
-
删除Matching Attention Flow匹配注意流时,观察到最大的下降(6.9% R10@1),这表明绘制每个话语的关键很重要。
-
删除Context Fusion 上下文融合,包括第一回合感知聚合(第一阶段聚合)和替换最后一阶段聚合(最后阶段聚合),用多层感知器进行匹配积累时,性能也会显著下降(4.8% R10@1),这表明话语关系很重要。
-
在没有Context Fusion 上下文融合与Matching Attention Flow匹配注意流机制的情况下,该模型的表现最差,验证了该机制确实从根本上改善了上下文表示
4. 错误分析
-
Multiple intentions多意图,在电子商务会话中,用户极有可能在单个消息中表达不同的意图,这是除了不同商品之间的会话类型不同之外,有别于以往的多轮会话语料库的另一大区别。例如:{用户:那护肤产品的包装呢?顺便问一下,请问是哪个快递公司负责发货,我能收到货物的时间是多久?} 这将严重混淆模型,即给定的响应可能优先于某个方面或另一个方面。
-
Topic errors话题错误,模型根据与上下文的语义相似度检索响应,没有特别注意会话主题,如当前讨论的商品。当对话涉及到几种商品时,例如:{用户:坚果怎么样?机器人:坚果不错。用户:好吧,那粽子呢?},模型可能会给出与上下文更相关的坚果的响应,而不是粽子。
-
Multiple suitable responses多个正确回复,由于精确匹配的严格限制,有多个正确回复时某些正确回复可能会在评估是判定为错误
参考:IR的评价指标-MAP,NDCG和MRR
有帮助的话可以点个赞喔~

这篇关于【论文阅读】Modeling Multi-turn Conversation with Deep Utterance Aggregation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







