本文主要是介绍论文笔记-语境重构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文出自彼得攀的小站
论文来自于华为和滑铁卢大学
该文章主要针对解决了汉语对话中语境重构的问题,即把代词、零代词等指称短语替换为它们指代的名词,这样可以在没有上下文中的情况,直接对当前对话句子进行处理。
Motivation
-
作者认为语境重构任务可以被分解为引用表达式检测(即代词和零代词检测)和引用还原(将代词还原为所指代的实体)
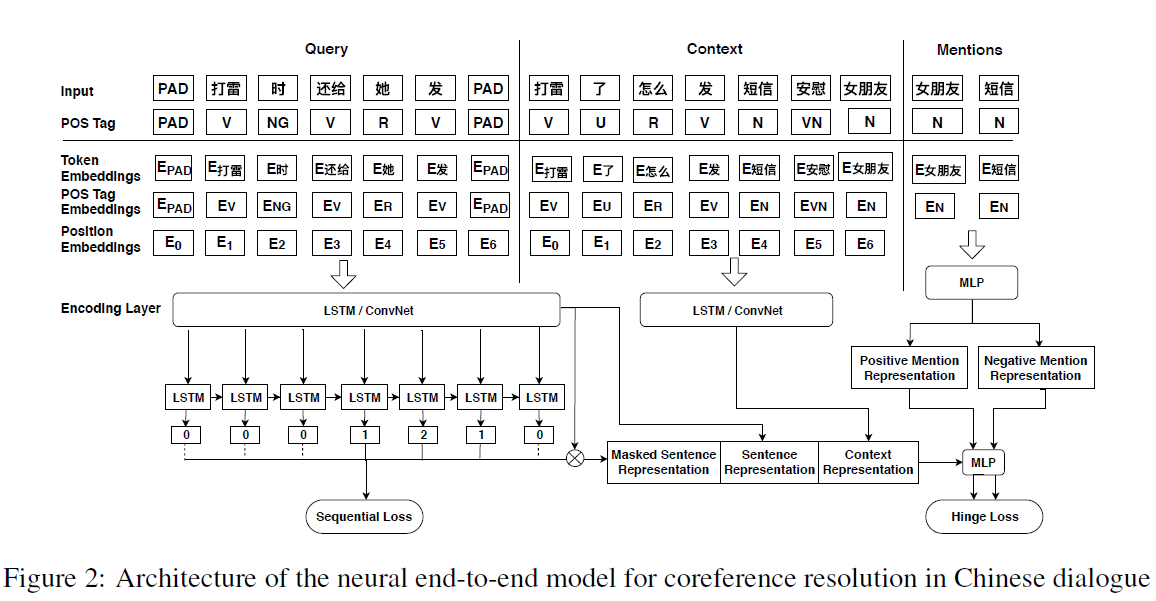
基于这样的认知,作者提出了一种新的端到端结构,来完成语境重构任务。该模型的主要特点是它包括基于神经网络的词性和位置编码以及一种新的代词掩模机制。 -
在构建此类模型时,一个长期存在的问题是缺乏训练数据,为解决这个问题,本文通过扩展以前提出的方法来生成大量实际的训练数据。由于结合了更多的数据和更好的模型,在共同引用解析(coreference resolution )和端到端上下文重建方面,本文模型可以获得比最先进的方法更高的精度
语境重构的目标是,从对轮对话历史中恢复历史信息,这样可以消除当前对话对于之前对话历史的依赖->这样当前对话的句子可以有全部且上下文无关的语义信息。
Introduction
文章利用词性标注模型来来解决指代和省略问题
文章的主要贡献:
- 将对话语境重构问题定义为一个检测问题和一个排序问题,并提出了其与传统的代词检测和零代词检测等任务的区别,提出了候选项的选择
- 分析了神经网络在对话系统中的应用,包括step-step和end-to-end的方法
- 提出了对话语境重构任务,并提出了一种构建大量有效数据的方法
coreference resolution(指代还原)被认为是两个任务:
- referring expressions detection
referring expression主要包含两个部分:- 代词: 如: 他/he,她/she
- 零代词:在汉语中十分普遍,汉语有一个特征:“倘若一个名词短语能够在阅读的过程中被他人从该名词短语所处的语境中猜测出其语义,那么这一名词短语就不需要在该句中明确地出现”,这种语法现象曾经被认为是省略,但现在大多认为是零回指/零代词
与该任务接近的任务是coreference detection,该任务旨在寻找指代相同实体的名词短语和代词。
- mention candidate ranking
该任务旨在将detection任务找到的referring expression还原为对应的实体
论文经过实验发现coreference detection(尤其是zero pronoun detection)是语境重构任务的瓶颈。
Method
语境重构任务可以被分为两个子任务:detection and resolution
Detection是一个序列标注任务,其会去识别需要被恢复的referring experssion,代词会被标记出来,零回指则会以一个符号∅来标记
Resolution是一个ranking的任务,对detection出来的referring expression, 进行排序。排序对象是一个三元组。

上图是一个语境重构的例子:假设一个输入话语为q,它的上下文由c来重构的(c来源于之前的对话)。
在detection任务中,输入q中的的她(代词)和∅(省略的零代词)会被识别出来。
在resolution任务中,会对三元组 ( c , q , m ) (c,q,m) (c,q,m)进行排序,其中 m ∈ { m 1 , m 2 , … , m k } m\in\{m_1,m_2,… ,m_k\} m∈{m1,m2,…,mk}是c中被挑选出来作为candidate的名词短语。在推理时,选择得分最高的candidate m作为替代词。这里选用的是Pairwise的排序模型。c和q是为了共同得到referring expression的representation。而例子中,“她”被替换为女朋友,“∅”被替换为短信
Masking Structure:即加入一个masked sentence representation层,即将序列标注的结果作为mask vector, 和sentence representation 相乘,从而得到一个masked sentence representation 。该过程会突出代词/零代词附近的词。
该论文还引入了一种构建数据集的方式:从百度知道和搜狗问问的数据中构建,为了生成可用的数据,作者使用了以下方式
- 代词: 用代词来替换句子中的实体
- 零代词: 省略句子中的实体
- 负样本:
- 不包括代词和零代词的样本
- 包括代词和零代词,但是没有对应candidate的词
作者构建的数据集叫CAQ.
实验结果
论文在三个数据集中做了实验CONLL2012,OntoNote,CQA数据集
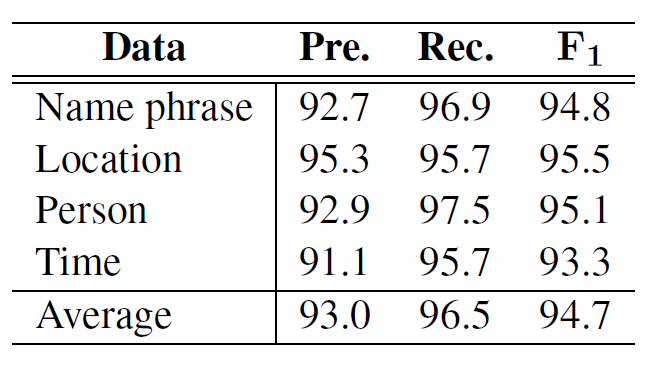
Detection
在CQA数据集上的referring expression detection结果
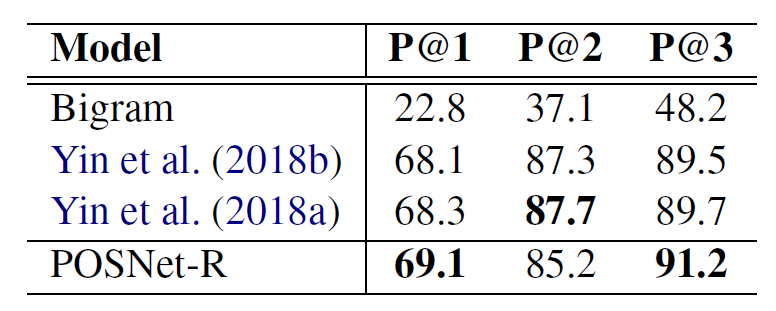
在CQA数据集上的mention candidate排序结果
Resolution
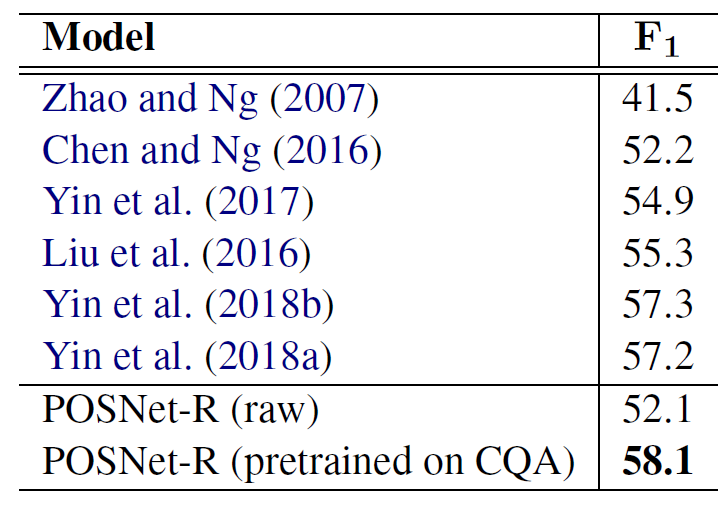
在CQA数据集上coreference resolution任务的结果

在CONLL2012上, 零代词mention candidate ranking的结果
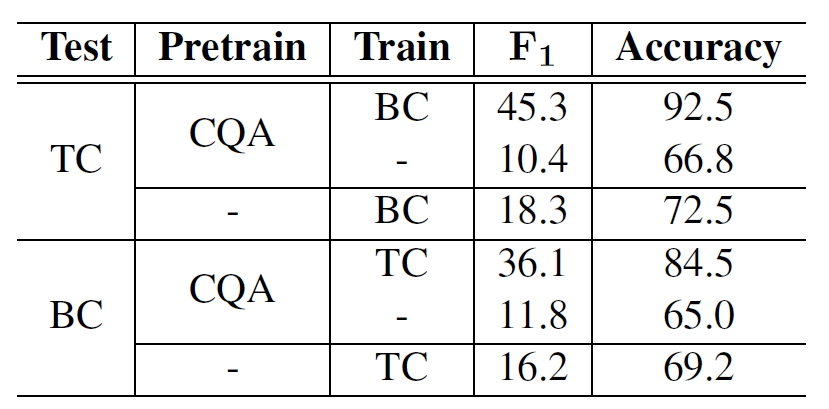
End-to-end
在OntoNote数据集上,zero pronoun resolution 任务的结果
这篇关于论文笔记-语境重构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







