本文主要是介绍Scrapy 简易爬取Boss直聘 可设定city job 爬取工作到excel或mysql中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2018-5-17一、 本篇讲述了如何编写利用Scrapy爬虫,把数据放入到MYSQL数据库中和写入到excel中,由于笔者之前爬取过拉勾网,但个人倾向与Boss直聘,所以再次爬取Boss直聘来作为知识梳理
二、 Scrapy工作原理介绍,之前的总结中已经介绍过了,而且网上有data flow 流程图,这里主要说一下,Scrapy中先是将SPIDERS中的url放入调度器,通过引擎,再经过DOWNLOADER处理回到引擎,处理完的item通过yield将经过ITEM PIPELIINES处理,然后再处理下一条url,这里主要是写一下顺序,所以接下来不要纠结为什么在DOWNLOADER中设置refere和user_agent。
三、 有图有真相吧,看一下excel中爬取的Python岗位
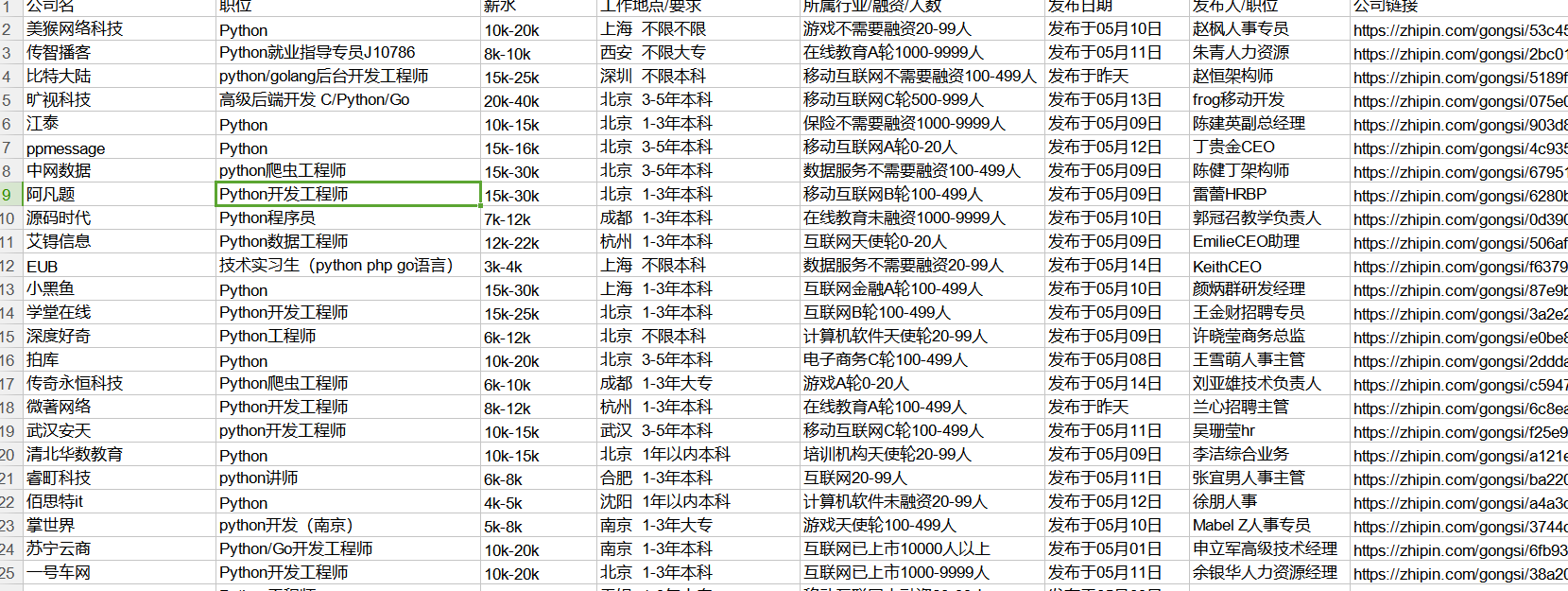
数据可以爬去更多,或是自己处理一下字段
四、 简单使用
1. 首先肯定是先调试好爬取的数据,得到自己想要的数据,在爬取过程中,发现此次不用ItemLoader更舒服,于是乎去掉了ItemLoader的使用,毕竟数据少。爬取时需要注意工作地点要求等一些字段共存于一个p标签中,通过em分离,还有就是加载出来的页面,把鼠标放在岗位上会有职位详情,建议爬取之前先查看源代码
爬取代码如下:
class BossSpider(scrapy.Spider):name = 'boss'allowed_domains = ['www.zhipin.com']# offset = 0 # pagecity = "c100010000/h_100010000" # 查找的城市,后续可以指定,利用input输入job = "Python" # 查找的岗位start_urls = ["https://www.zhipin.com/{0}/?query={1}&page=".format(city, job)]# start_urls = [baseURL]def parse(self, response):lis = response.css(".job-list ul li")for node in lis:item = BossjobItem()item['company_name'] = node.css('.company-text > h3 > a::text').extract_first("")item['job'] = node.css('div.job-title::text').extract_first("")item['salary'] = node.css('h3.name > a > span.red::text').extract_first("")item['experience'] = node.css('.info-primary > p::text').extract() # 地址 经验 学历item['situation'] = node.css('.company-text > p::text').extract() # 公司分类 融资 人数item['publish_time'] = node.css('.info-publis > p::text').extract_first("") # 发布日期item['publish_person'] = node.css('.info-publis > h3::text').extract() # 发布人 发布人的职位item['company_link'] = parse.urljoin('https://zhipin.com', node.css('.company-text > h3 a::attr(href)').extract_first("")) # 记住需要拼接urlyield itemnext_a = response.css('div.page > a.next::attr(href)').extract_first()print(next_a)if next_a != 'javascript:;': # 通过得到下一页的链接print("https://www.zhipin.com"+next_a)yield scrapy.Request("https://www.zhipin.com" + next_a, callback=self.parse)其中city可以在网页中请求boss首页,按F12,在其的两个.json文件中可取出全国所有的城市和岗位,其实岗位可以自己设置,都行,但是城市的话不行
2. spider很简单,写的过程中通过scrapy shell 命令调试。接下来就是插入Excel中了,利用xlwt模块,在pipelines内设置即可。
代码如下:
class BossjobPipeline(object):def __init__(self):self.count = 1self.workbook = xlwt.Workbook()self.sheet = self.workbook.add_sheet("Boss直聘", cell_overwrite_ok=True)row_title = ['公司名', '职位', "薪水", "工作地点/要求", "所属行业/融资/人数", "发布日期", "发布人/职位", "公司链接"]for i in range(0, len(row_title)):self.sheet.write(0, i, row_title[i])def process_item(self, item, spider):craw_list = list()craw_list.append(item["company_name"])craw_list.append(item["job"])craw_list.append(item["salary"])craw_list.append(item["experience"])craw_list.append(item["situation"])craw_list.append(item["publish_time"])craw_list.append(item["publish_person"])craw_list.append(item["company_link"])self.write_in_excel(craw_list)return itemdef write_in_excel(self, crawl_list):for j in range(0,len(crawl_list)):self.sheet.write(self.count, j, crawl_list[j])self.workbook.save("Boss直聘.xlsx")self.count += 13. 接下来就是插入到MySql数据库了,在此之前我觉得有必要先来一个工具类测试一下数据库连接和创建数据库,需要时按自己情况改动。
代码如下:
import MySQLdb
from scrapy.utils.project import get_project_settings # 导入settings配置class DbHelper():def __init__(self):self.settings = get_project_settings()self.host = self.settings['MYSQL_HOST']self.port = self.settings['MYSQL_PORT']self.user = self.settings["MYSQL_USER"]self.passwd = self.settings['MYSQL_PASSWORD']self.db = self.settings['MYSQL_DBNAME']# 连接到mysql,注意不是连接到具体的数据库,中间件也有此操作def connectMysql(self):conn = MySQLdb.connect(host=self.host,post=self.port,user=self.user,passwd=self.passwd,charset='utf8') # 指定为utf8 OKreturn conn# 连接到数据库def connectDatabase(self):conn = MySQLdb.connect(host=self.host,post=self.port,user=self.user,passwd=self.passwd,db=self.db,charset='utf8') # 指定为utf8 OKreturn conn# 创建数据库def createDatabase(self):conn = self.connectMysql()sql = "create database if not exists " + self.dbcur = conn.cursor()cur.execute(sql)cur.close()conn.close()# 创建表def createTable(self, sql):conn = self.connectDatabase()cur = conn.cursor()cur.execute(sql)cur.close()conn.close()# 插入数据def insert(self, sql, *params): # *代表个数不确定,传递元组过来即可conn = self.connectDatabase()cur = conn.cursor()cur.execute(sql, params)conn.commit() # 注意要commitcur.close()conn.close()# 更新数据def update(self, sql, *params):conn = self.connectDatabase()cur = conn.cursor()cur.execute(sql, params)conn.commit() # 注意要commitcur.close()conn.close()# 删除数据def delete(self, sql, *params):conn = self.connectDatabase()cur = conn.cursor()cur.execute(sql, params)conn.commit()cur.close()conn.close()# 测试
class TestDBHelper():def __init__(self):self.dbHelper = DbHelper()# 创建数据库def testCreateDatabase(self):self.dbHelper.createDatabase()# 创建表def testCreateTable(self):sql = '''create table BossJob(id int primary key auto_increment,company_name varchar(50),job varchar(100),salary varchar(30),experience varchar(10),situation varchar(10),publish_time varchar(20),publish_person varchar(20),company_link varchar(100)'''self.dbHelper.createTable(sql)if __name__ == "_main__":try:helper = TestDBHelper()helper.testCreateDatabase()helper.testCreateTable()except Exception as e:print(str(e))主要是试试数据库连接或者创建表情况,检查问题
4. 接下来就需要在Scrapy中将数据库操作写好,数据库执行语句肯定首选异步操作,Scrapy中含有twisted,直接用就好
首先在item中定义好它的insert参数,方便后续扩展
def get_insert_sql(self):insert_sql = '''insert into boss(company_name,job,salary,experience,situation,publish_time,publish_person,company_link VALUES (%s,%s,%s,%s,%s,%s,%s,%s)ON DUPLICATE KEY UPDATE salary=VALUES(salary),publish_time=VALUES(publish_time))'''params = (self['company_name'], self['job'], self['salary'], self['experience'],self['situation'], self['publish_time'],self['publish_person'],self['company_link'])return insert_sql, paramsclass BossJobMySql(object):def __init__(self, dbpool):self.dppool = dbpool@classmethoddef from_settings(cls, settings):dbparms = dict(host=settings["MYSQL_HOST"],db=settings['MYSQL_DBNAME'],user=settings["MYSQL_USER"],passwd=settings["MYSQL_PASSWORD"],charset="utf8", # 此处可能填写utf-8 数据库会连接失败,报错cursorclass=MySQLdb.cursors.DictCursor,use_unicode=True,)dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms) # 这里使用变长参数return cls(dbpool)def process_item(self, item, spider):query = self.dppool.runInteraction(self.do_insert, item)query.addErrback(self.handle_error, item, spider)def do_insert(self, cursor, item):insert_sql, params = item.get_insert_sql()cursor.execute(insert_sql, params)def handle_error(self, failure, item, spider):print(failure)5. 最后在爬虫前设置一下User_Agent和Referer,当然是写一个middlerware,类中主要方法是:
class CustomUserAgentMiddleware(object):def __init__(self, crawler):super().__init__()self.ua = UserAgent()self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', "random")@classmethoddef from_crawler(cls, crawler):return cls(crawler)def process_request(self, request, spider):def get_ua():return getattr(self.ua, self.ua_type)request.headers.setdefault('User_Agent', get_ua())request.headers.setdefault('Referer', 'https://www.zhipin.com/')利用的fake_useragent的ua.random()方法随机得到User_Agent,如果不设置User_Agent,默认的僵尸Scrapy,然后反爬虫反的就是你咯
6. setting.py中部分设置
RANDOM_UA_TYPE = 'random'ROBOTSTXT_OBEY = FalseDOWNLOADER_MIDDLEWARES = {'BossJob.middlewares.CustomUserAgentMiddleware': 542,# 想要使用自定义User_Agent,当然得屏蔽Scrapy它自己的,否则无效'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None}ITEM_PIPELINES = {'BossJob.pipelines.BossjobPipeline': 300,'BossJob.pipelines.BossJobMySql': 310,}MYSQL_HOST = "127.0.0.1"MYSQL_DBNAME = "job"MYSQL_USER = "你的用户名"MYSQL_PASSWORD = "你的密码"MYSQL_PORT = "3306"五、 最后一步肯定是运行得到结果咯,其实找工作时,特别是你比较着急时,你可以从SPIDERS类的job字段下手,在职位面前加一些特点的匹配字段,例如,着急嘛....
六、 项目地址: click there to get code source 有误请纠正,谢谢!
这篇关于Scrapy 简易爬取Boss直聘 可设定city job 爬取工作到excel或mysql中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



