本文主要是介绍STM32CubeIDE 1.15.0 LOAD segment with RWX permissions 警告处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
处理办法:
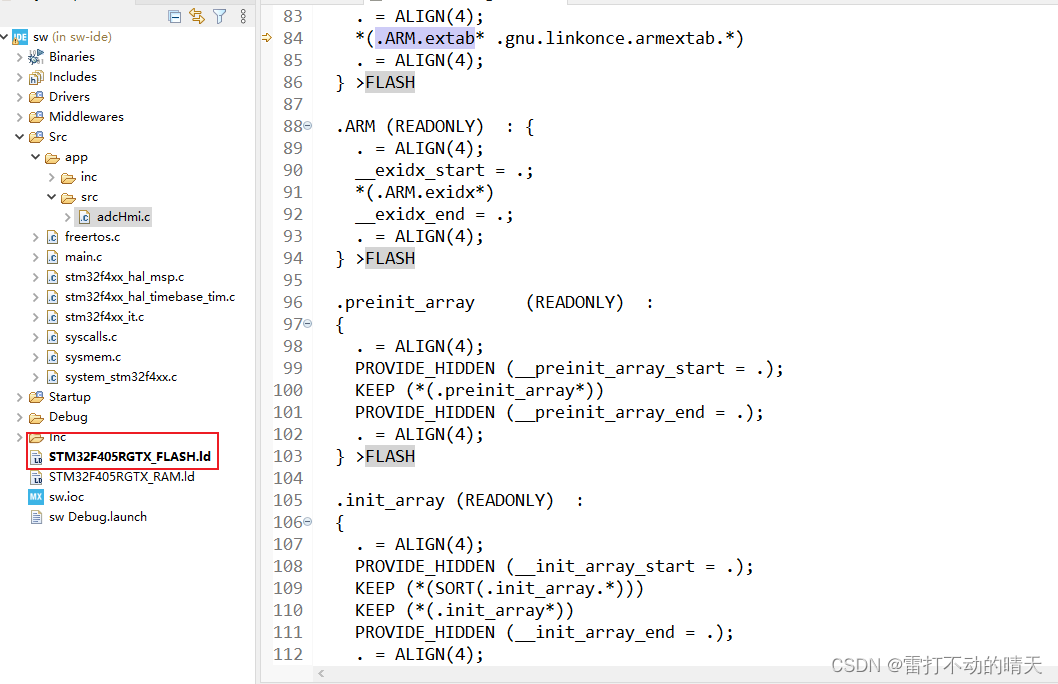
在"xx_FLASH.ld"文件中,找到并添加上(READONLY),即可消除
- .ARM.extab (READONLY) :
- .ARM (READONLY) :
- .preinit_array (READONLY) :
- .init_array (READONLY) :
- .fini_array (READONLY) :
这篇关于STM32CubeIDE 1.15.0 LOAD segment with RWX permissions 警告处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





