本文主要是介绍FDTD仿真发散(个人理解翻译),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
英文原文地址
非专业翻译,仅供参考。
主要讨论如何修复仿真发散的问题
大多数仿真发射是有auto shut-off引起的。“ERROR: Early termination of simulation, the electromagnetic fields are diverging.”(错误:过早的结束仿真,电磁场发散)。当仿真区域中的值达到指定的阈值时,发仿真散一般被分为两种情况:1.dt的稳定因素。2.PML边界条件问题。
区分这两种情况的方法是:将仿真区域的边界条件全部改为Matel边界条件,再次运行仿真。如果不发生发散,则是PML边界问题;否则为dt稳定的问题。
关于dt稳定问题
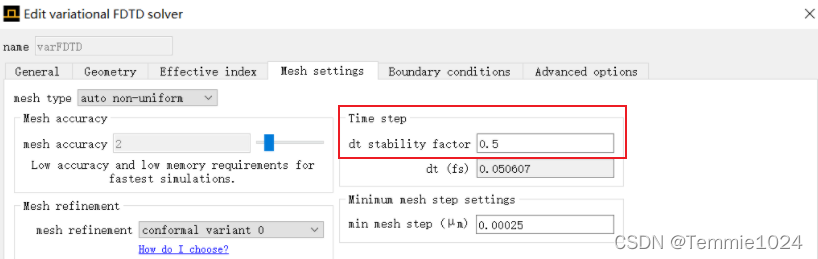
最大的仿真时间是根据mesh网格基于Courant stability准则计算的。默认情况下,软件会使用99%的理论最大仿真时长。最大时间不长是假定于光在均匀或真空介质中传播(homogeneous vacuum大概这么翻译吧)。仿真区域中包含结构或交界面,尤其存在色散材料的时候,仿真时间有时会变得更少。
对于这种发散情形,减小dt stability factor直到仿真稳定。通常情况下,0.95或者0.9就可以让仿真稳定;在其他情况下使用的值一般小于等于0.5。减小仿真步长并不会影响精度以及仿真内存需求,但它会增加仿真时间。dt stability factor从0.99到0.95会增加4%的仿真时间。
照成dt stability facyor不稳定原因:
1.材料未拟合正确,确保材料拟合较好。
2.网格的精细度,长宽比不应过大。尽量长宽比倍数差不要太大,原文中给的例子是5倍。
PML与材料发散
通常,我们应该将结构延伸到仿真区域外,这将给与更高的精度。然而有些色散材料在穿过PML边界的时候会不稳定。此时,材料与边界的交界处就会不稳定。如果你在仿真区域放置一个movie监视器,你可以很容易发现这种情况。
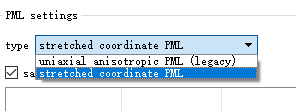
如果你使用的是2015a及之后的版本,你可以使用SPML边界来替换原PML边界以解决这个问题。
使用SCPML的方法:使用以下一种或几种。(我用的是旧版,这里无法验证)
1.alpha setting和PML layers的值进行加大。这种方法一般单独使用来使仿真稳定。
2.增大 alpha,但同时它也会增加边界的反射效果。或者增加PML layers的层数。
3.改变mesh的大小。
4.改变结构,避免材料穿过边界。
使用PML的放大:使用以下一种或几种。
1.减小PML的sigma值。这样会减少边界的吸收效果,但layers的值会自动变大。因此边界的整体效果不变,但会消耗更多的计算机内存。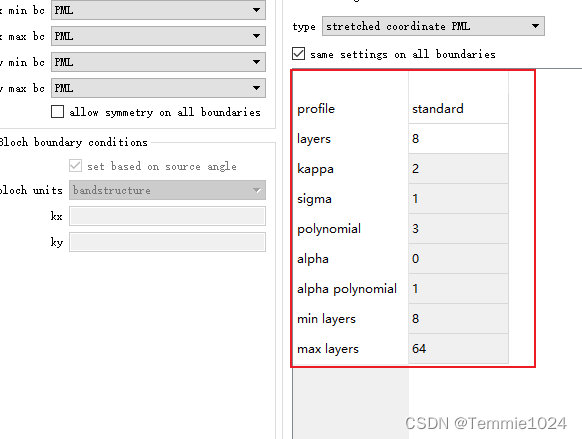
2.增加kappa。它的默认值是2,。将它加到10甚至20通常就会解决发散问题。它会轻微增加边界的反射效果,但也会减少大角度入射边界的反射。kappa的值大于20时会大幅降低PML的特性,因此最好不要大于20。
3.设置Type of PML to Stabilized ,但它会降低大角度入射时的边界性能。
4.改变结构,避免材料穿过边界。在结构穿过前终止,或者勾选extend structure through the pml 来防止结构穿过。

这篇关于FDTD仿真发散(个人理解翻译)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








