本文主要是介绍【计算机网络篇】数据链路层(2)封装成帧和透明传输,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 🥚封装成帧和透明传输
- 🎈封装成帧
- 🎈透明传输
- 🗒️面向字节的物理链路使用字节填充的方法实现透明传输。
- 🗒️面向比特的物理链路使用比特填充的方法实现透明传输。
- 🛸练习

🥚封装成帧和透明传输
🎈封装成帧
是指数据链路层给上层交付下来的协议数据单元PDU添加一个首部和一个尾部,使之成为帧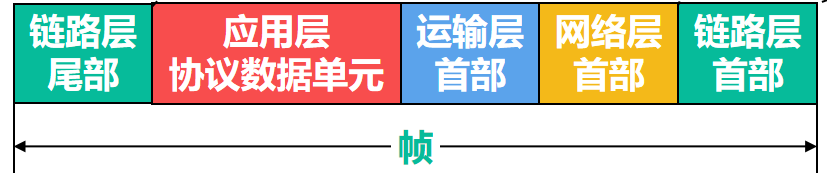
帧的首部和尾部包含一些重要的控制信息,如下图
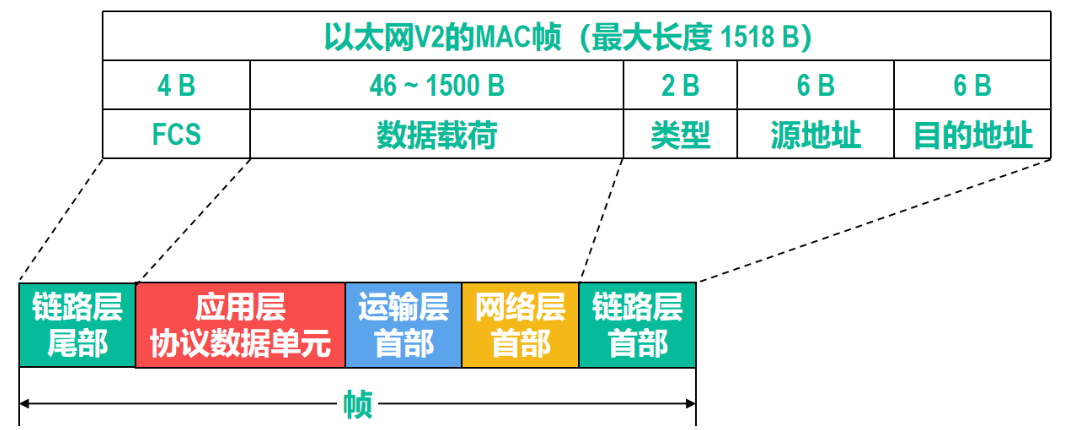
以太网的V2的MAC帧
首部包含:目的地址,源地址,类型这3个字段
尾部包含:帧检查序列FCS字段,
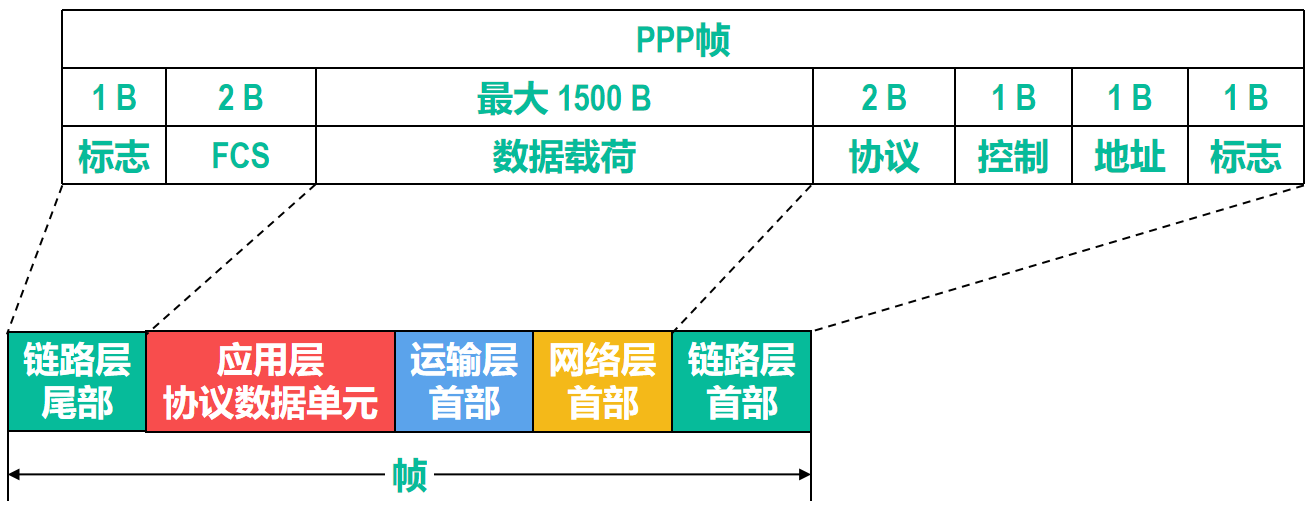
点对点协议PPP的帧格式
首部包含:标志,地址,控制,协议4个字段
尾部包含:帧检验序列FCS,标志2个字段
数据链路层将封装好的帧向下交付给物理层,物理层将其看作是比特流,并转换成相应的电信号发送给接收方。
为了提高数据链路层传输帧的效率,应当使帧的数据荷载的长度尽可能地大于数据链路层首部和尾部的长度
考虑到对缓存空间的需求以及差错控制等诸多因素,每一种数据链路层协议都规定了帧的数据载荷的长度上限,即最大传送单元(Maximum Transfer Unit,MTU)。例如,以太网的MTU为1500个字节
🎈透明传输
是指数据链路层对上层交付下来的协议数据单元PDU没有任何限制,就好像数据链路层不存在一样
🗒️面向字节的物理链路使用字节填充的方法实现透明传输。
如下图
发送方的网络层交付给数据链路层的网络层协议数据单元,数据链路层为其添加一个首部和一个尾部使之封装成帧 ,为了简单起见,我们只画出了帧首部和尾部中的帧定界符,使用flag表示。
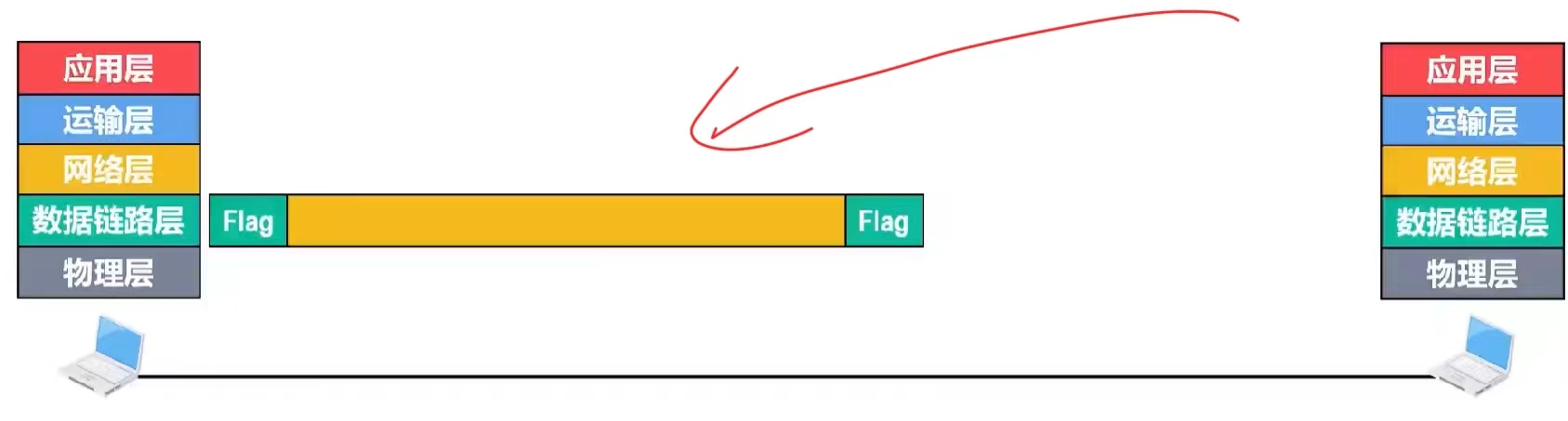
帧定界符是一个特殊数值。那么,如果在上层交付给数据链路层的协议数据单元中恰好也包含了这个特殊数值,接收方还能从接收到的比特流中正确提取出该帧吗,答案是不能
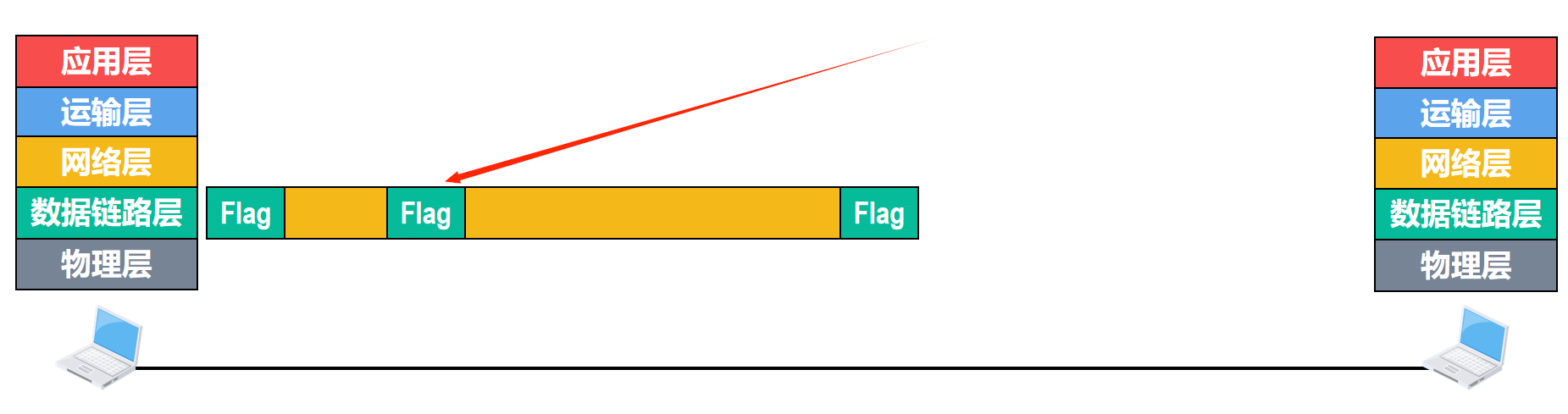
如下图,接收方在收到第一个帧定界符的时候,认为这是帧的开始

当接收方再次收到帧定界符时,会误认为帧结束了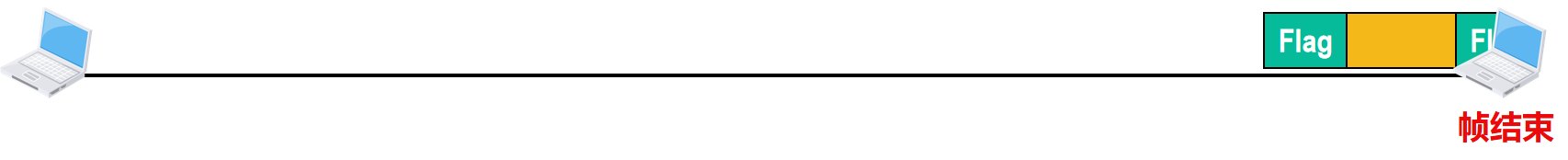
如果数据链路层不采取措施解决该问题,就不能称之为透明传输。因为数据链路层会对上层交付的协议数据单元有限制,其内容不能包含帧定界符,很显然,这样子的数据链路层没有什么应用价值。如果能够采取措施,使得数据链路层对上层交付的协议数据单元的内容没有任何限制,就好像数据链路层不存在一样,就称其为透明传输
实际上,各种数据链路层协议一定会想办法来实现透明传输
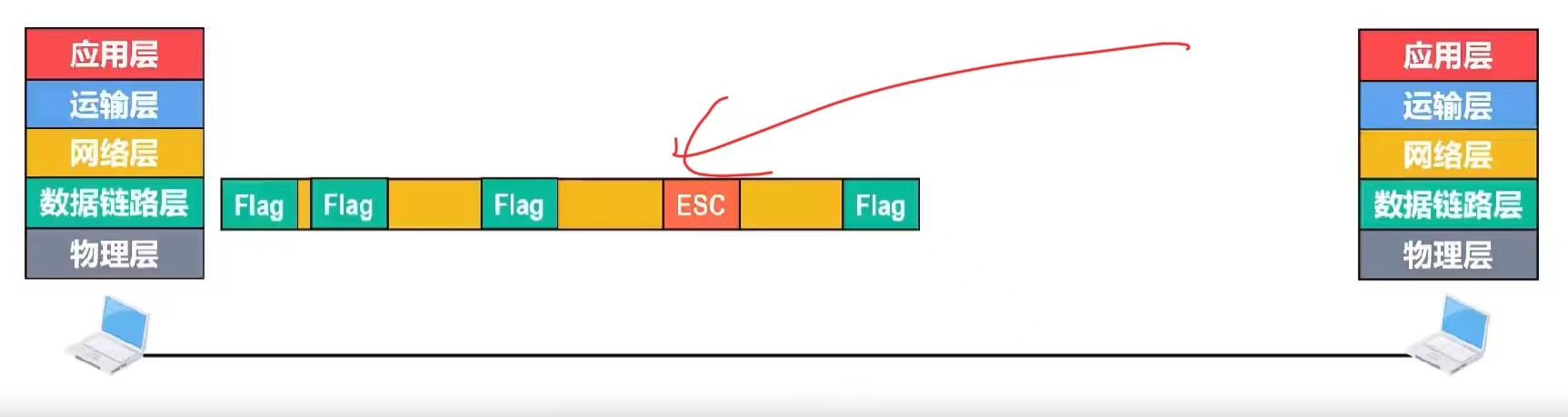
例如:在把帧交付给物理层之前,对帧的数据载荷进行扫描,每出现一个帧定界符,就在其前面插入一个转义字符。(转义字符是一种特殊的控制字符,其长度是一个字节,十进制为27,而并不是E,S,C这3个字符)
接收方的数据链路层在物理层交付的比特流中提取帧,遇到第一个帧定界符的时候,认为这是帧的开始,当遇到转移字符时就知道了其后面的1个字节的内容,虽然与帧定界符相同,但是它是数据而不是帧定界符。
移除转移字符后,将其后面的内容作为数据继续提取
当再次提前到帧定界符的时候,表明这是帧的结束
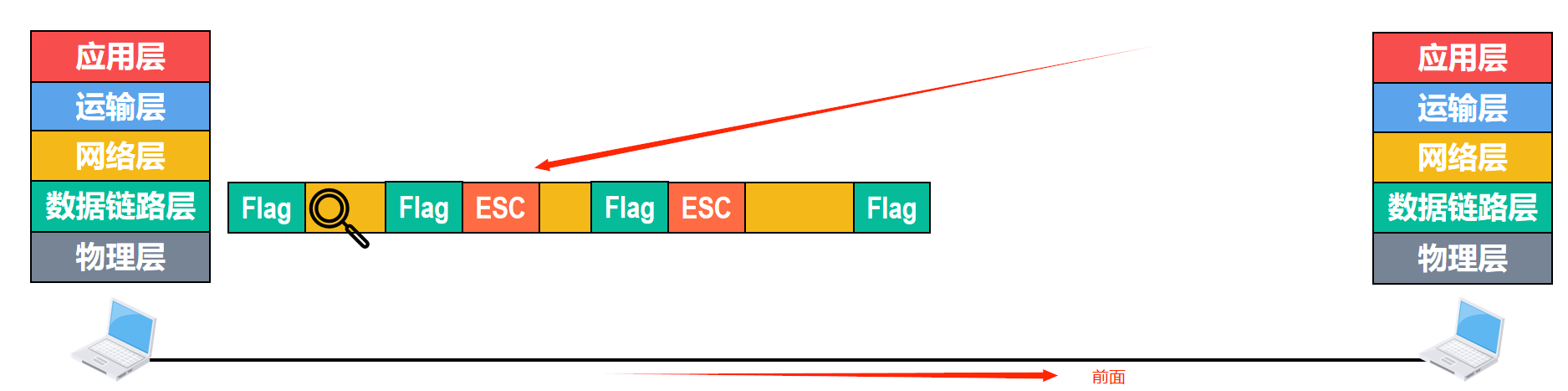

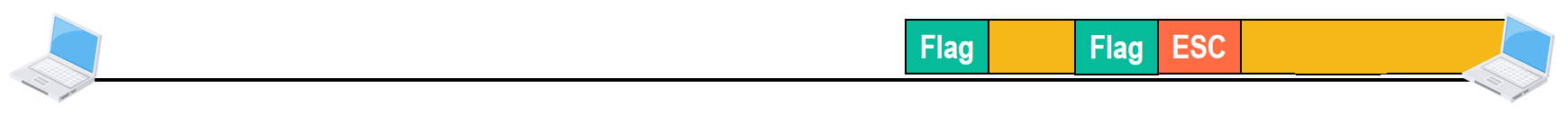

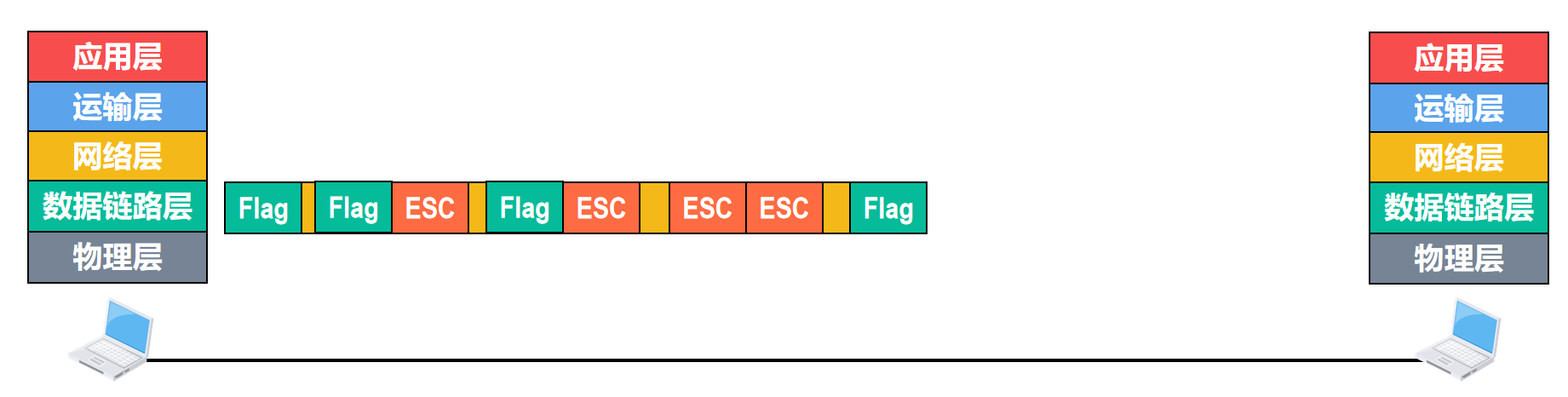
还有一种情况,就是在上层交付给数据链路层的协议数据单元中,既包含了帧定界符,又包含了转义字符
这种情况应该如何处理呢
方法仍然是:在把帧交给物理层之前,对帧的数据载荷进行扫描,每出现一个帧定界符或转义字符,就在其前面插入一个转义字符
🗒️面向比特的物理链路使用比特填充的方法实现透明传输。
我们来举例说明,如下图
设某个数据链路层协议采用8个比特构成的特定位串0111 1110作为帧定界符

这是发送方的数据链路层封装成的一个帧,然而,在该帧的数据载荷部分,恰好包含有作为帧定界符的特定位串,发送方的数据链路层在将该帧交付给物理层进行发送之前,会扫描帧的时间载荷。只要出现5个连续的比特1,就在其后添加一个比特0
经过这种比特0填充后的数据载荷,就可以确保其不会包含帧定界符。

接收方的数据链路层在把数据载荷向上交给网络层之前,对数据载荷进行扫描,没当发现5个连续的比特1时,就把其后面的比特0删除,这样子就可以还原出原始的数据载荷
如下图,发送方给接收方连续发送了2个帧,每个帧的首部和尾部都有标志字段,我们称为帧定界符。接收方的数据链路层根据帧定界符,就能从一连串的比特流中,识别出一个个的帧。
注意:上面介绍的字符填充法和比特填充法只是实现透明传输的一般原理性方法,各种数据链路层协议,都有其实现透明传输的具体方法,其中,有的是基于字符填充法或比特填充法,而有点没有使用这2种方法
🛸练习

这篇关于【计算机网络篇】数据链路层(2)封装成帧和透明传输的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







