本文主要是介绍linux系统------------MySQL 存储引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、存储引擎概念介绍
二、常用的存储引擎
2.1MyISAM
2.1.1MYlSAM的特点
2.1.2MyISAM 表支持 3 种不同的存储格式⭐:
(1)静态(固定长度)表
(2)动态表
(3)压缩表
2.1.3MyISAM适用的生产场景
2.2InnoDB
2.2.1InnoDB特点
2.2.2InnoDB适用生产场景分析
2.2.3企业选择存储引擎依据
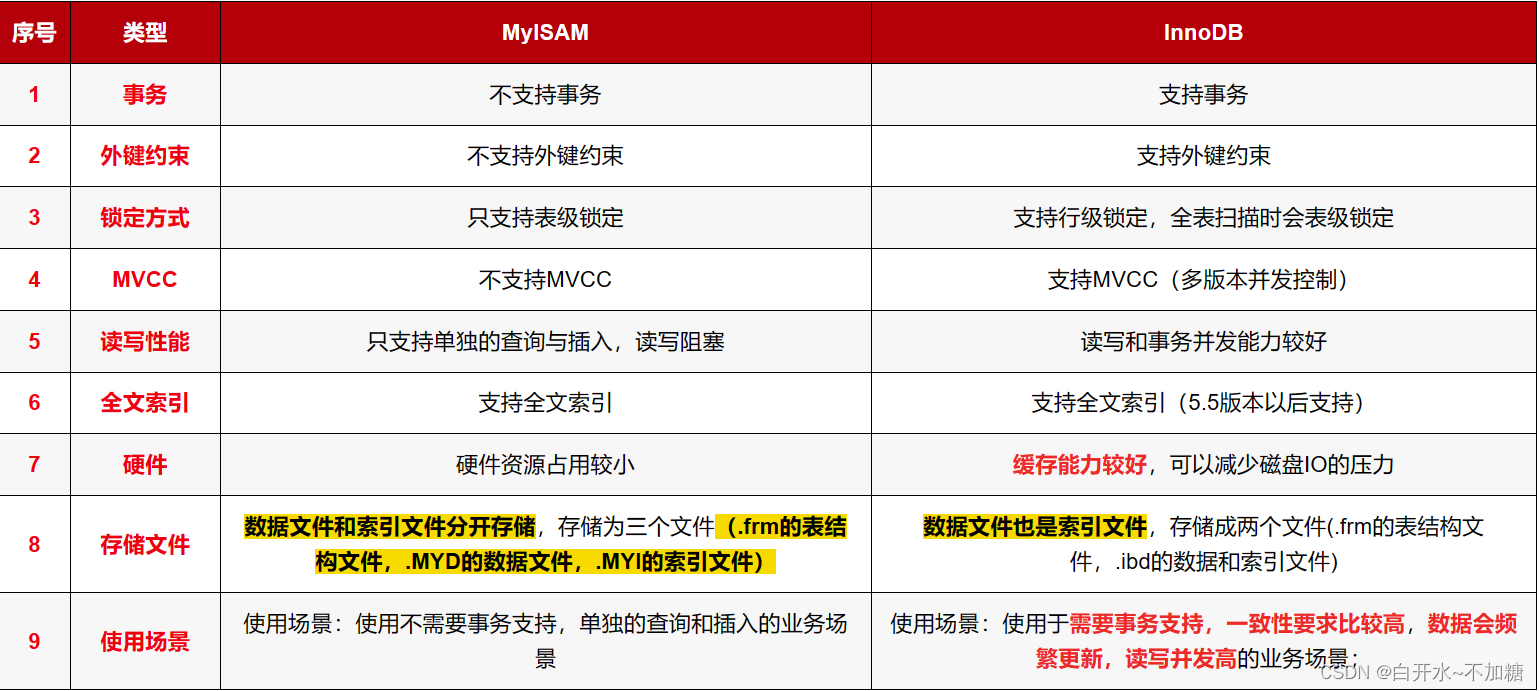
2.3MyISAM和InnoDB的区别
三、查看系统支持的存储引擎
四、查看表使用的存储引擎
五、修改存储引擎
方法一:通过 alter table 修改
方法二:通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务
查看原来feixi表的存储引擎
创建新表feidong查看存储引擎
方法三:通过 create table 创建表时指定存储引擎
一、存储引擎概念介绍
在MySQL数据库的世界里,存储引擎作为数据库的核心组件,负责数据的存储、检索和索引管理等关键任务。MySQL支持多种存储引擎,每种引擎都有其独特的优劣和适用场景,使得MySQL能够灵活适应各种各样的业务需求。
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎
存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
- 存储引擎是MySQL数据库中的一个【组件】,【负责执行实际的数据I/O操作】,工作在文件系统之上,数据库的数据会先传到存储引擎,在按照存储引擎的格式,保存到文件系统
MySQL 整个查询执行过程,即MySQL的工作原理?
1、MySQL服务器接收到来自客户端的数据请求;2、数据库会先查询缓存记录,如果命中缓存,直接返回存储在缓存中的查询结果,如果没有命中,则进行下一步操作;
3、数据库会先由解析器来解析SQL语句的,然后进行预处理,接着用优化器生成最优的执行计划;
4、数据库根据最优的执行计划,调用存储引擎的API接口来执行查询结果,并将结果返回给客户端,同时缓存查询结果;
- MySQL常用的存储引擎:MyISAM 和 InnoDB
- MySQL数据库中的组件,负责执行实际的数据I/O操作
- MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储
二、常用的存储引擎
2.1MyISAM
MyISAM:不支持事务和外键约束,占用空间较小,访问速度快,适用于不需要事务处理,频繁查询的应用场景
2.1.1MYlSAM的特点
①MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的
②访问速度快,对事务完整性没有要求
③MyISAM 适合查询、插入为主的应用场景
④MyISAM在磁盘上存储成三个文件,文件名和表名都相同,但是扩展名分别为:
⑤MyISAM在磁盘上存储成三个文件:
- .frm 文件存储表结构的定义
- 数据文件的扩展名为 .MYD (MYData)
- 索引文件的扩展名是 .MYI (MYIndex)
ls /usr/local/mysql/data/mysql/
⑥表级锁定形式,数据在更新时锁定整个表
你在操作表时,所有人不能进行写入和读取,称为表级锁定
⑦数据库在读写过程中相互阻塞: ————》串行操作,按照顺序操作,每次在读或写的时候会把全表锁起来
- 会在数据写入的过程阻塞用户数据的读取
- 也会在数据读取的过程中阻塞用户的数据写入
⑧数据单独写入或读取,速度过程较快且占用资源相对少
⑨MyIAM支持的存储格式
- 静态表
- 动态表
- 压缩表
MyIsam 是表级锁定,读或写无法同时进行
优点:分开执行时,速度快、资源占用相对较少(相对)
2.1.2MyISAM 表支持 3 种不同的存储格式⭐:
(1)静态(固定长度)表
静态表是默认的存储格式,静态表中的字段都是非可变字段,这样每个记录都是固定长度的
优点:是存储非常迅速,容易缓存,出现故障容易恢复;
缺点:是占用的空间通常比动态表多。
(2)动态表
动态表包含可变字段(varchar),记录不是固定长度的,这样存储的
优点:是占用空间较少
缺点:频繁的更新、删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk -r 命令来改善性能,并且出现故障的时候恢复相对比较困难。
(3)压缩表
压缩表由 myisamchk 工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
2.1.3MyISAM适用的生产场景
- 公司业务不需要事务的支持
- 单方面读取或写入数据比较多的业务
- MyISAM存储引擎数据读写都比较频繁场景不适合
- 使用读写并发访问相对较低的业务
- 数据修改相对较少的业务
- 对数据业务一致性要求不是非常高的业务
- 服务器硬件资源相对比较差
MyIsam:适合于单方向的任务场景、同时并发量不高、对于事务要求不高的场景
2.2InnoDB
InnoDB:支持事务处理、外键约束、占用空间比MyISAM大,适用于需要事务处理、更新删除频繁的应用场景
2.2.1InnoDB特点
- 支持事务,支持4个事务隔离级别(数据不一致问题)⭐⭐
- MySQL从5.5.5版本开始,默认的存储引擎为 InnoDB
- 5.5 之前是myisam (isam) 默认
- 读写阻塞与事务隔离级别相关
- 能非常高效的缓存索引和数据
- 表与主键以簇的方式存储
- 支持分区、表空间,类似oracle数据库(5.5 ——》5.6 和5.7 第三代数据库8.0后版本)
- 支持外键约束,5.5前不支持全文索引,5.5后支持全文索引
- 对硬件资源要求还是比较高的场合
- 行级锁定,但是全表扫描仍然会是表级锁定(select )
- 如update table set a=1 where user like ‘%lic%’;
-
nnoDB 中不保存表的行数,如 select count(*) from table; 时,InnoDB 需要扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数即可。需要注意的是,当 count(*)语句包含 where 条件时 MyISAM 也需要扫描整个表
对于自增长的字段,InnoDB 中必须包含只有该字段的索引但是在 MyISAM 表中可以和其他字段一起建立组合索引
清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重建表(truncate)
2.2.2InnoDB适用生产场景分析
- 业务需要事务的支持
- 行级锁定对高并发有很好的适应能力,但需确保查询是通过索引来完成
- 业务数据更新较为频繁的场景 如:论坛,微博等
- 业务数据一致性要求较高 如:银行业务
- 硬件设备内存较大,利用lnnoDB较好的缓存能力来提高内存利用率,减少磁盘IO的压力
2.2.3企业选择存储引擎依据
需要考虑每个存储引擎提供的核心功能及应用场景
- 如果读写的并发量大,建议使用InnoDB
- 如果单独的写入或是插入单独的查询,建议使用MyISAM
支持的字段和数据类型
- 所有引擎都支持通用的数据类型
- 但不是所有的引擎都支持其他的字段类型,如二进制对象
锁定类型:不同的存储引擎支持不同级别的锁定
- 表锁定
- 行锁定
表级锁:开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定力度最小,发生锁冲突的概率最低,并发度也最高;
索引的支持
- 建立索引在搜索和恢复数据库中的数据时能显著提高性能
- 不同的存储引擎提供不同的制作索引的技术
- 有些存储引擎根本不支持索引
事务处理的支持
- 提高在向表中更新和插入信息期间的可靠性
- 可根据企业业务是否要支持事务选择存储引擎 innodb
2.3MyISAM和InnoDB的区别
InnoDB支持事务,MyISAM不支持。对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
InnoDB支持外键,而MyISAM不支持。
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快。
Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;5.7以后的InnoDB支持全文索引了。
InnoDB支持表、行级锁(默认),而MyISAM支持表级锁。
InnoDB表必须有主键(用户没有指定的话会自己找或生产一个主键),而Myisam可以没有。
Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI。
Innodb:frm是表定义文件,ibd是数据文件。
Myisam:frm是表定义文件,myd是数据文件,myi是索引文件。
三、查看系统支持的存储引擎
show engines;
字段含义:
| Engine | 存储引擎 |
| Support | 系统是否支持 |
| Comment | 注释信息 |
| Transactions | 是否支持事务 |
| XA | 是否支持XA协议 |
| Savepoints | 是否支持节点 |

InnoDB存储引擎
InnoDB是MySQL的默认存储引擎。InnoDB引擎支持行级锁定,能够有效减少并发操作时的锁争用,提高并发性能。同时,它实现了ACID(原子性、一致性、隔离性、持久性)事务特性,确保了数据的一致性和安全性。此外,InnoDB引擎支持外键约束,提供了良好的数据完整性保障。在现代MySQL版本中,InnoDB还支持分区表、聚集索引和自适应哈希索引等特性,进一步优化了性能。
MRG_MyISAM存储引擎
基于MERGE,将多个MyISAM表合并成一个逻辑表。相同MyISAM表的集合
MEMORY存储引擎
MEMORY(以前称为 HEAP)存储引擎将数据存储在内存中,因此它的查询速度极快,尤其适用于临时表或者需要快速读写的场景。但由于数据仅存在于内存中,一旦MySQL服务器关闭,表中的数据就会丢失。此外,MEMORY引擎也不支持事务和外键约束。
BLACKHOLE黑洞引擎
所有写入都被丢弃,用于记录binlog但不实际存储数据
MyISAM存储引擎
MyISAM曾是MySQL早期的默认存储引擎,虽然在事务处理和行级锁定方面不如InnoDB强大,但因其索引文件和数据文件分离、全表扫描速度快等特点,在读密集型场景中表现出色。MyISAM不支持事务和外键,基于哈希,存储在内存中,对临时表很有用
ARCHIVE存储引擎
ARCHIVE存储引擎主要用于大量历史数据归档,它压缩率极高,适合长期存储且很少需要更新的大容量静态数据。ARCHIVE引擎只支持INSERT和SELECT操作,不支持UPDATE和DELETE,也不支持索引。
CSV存储引擎
以CSV格式存储数据,易于与其他程序交换数据
目前MySQL常用的存储引擎有InnoDB存储引擎与MyISAM存储引擎
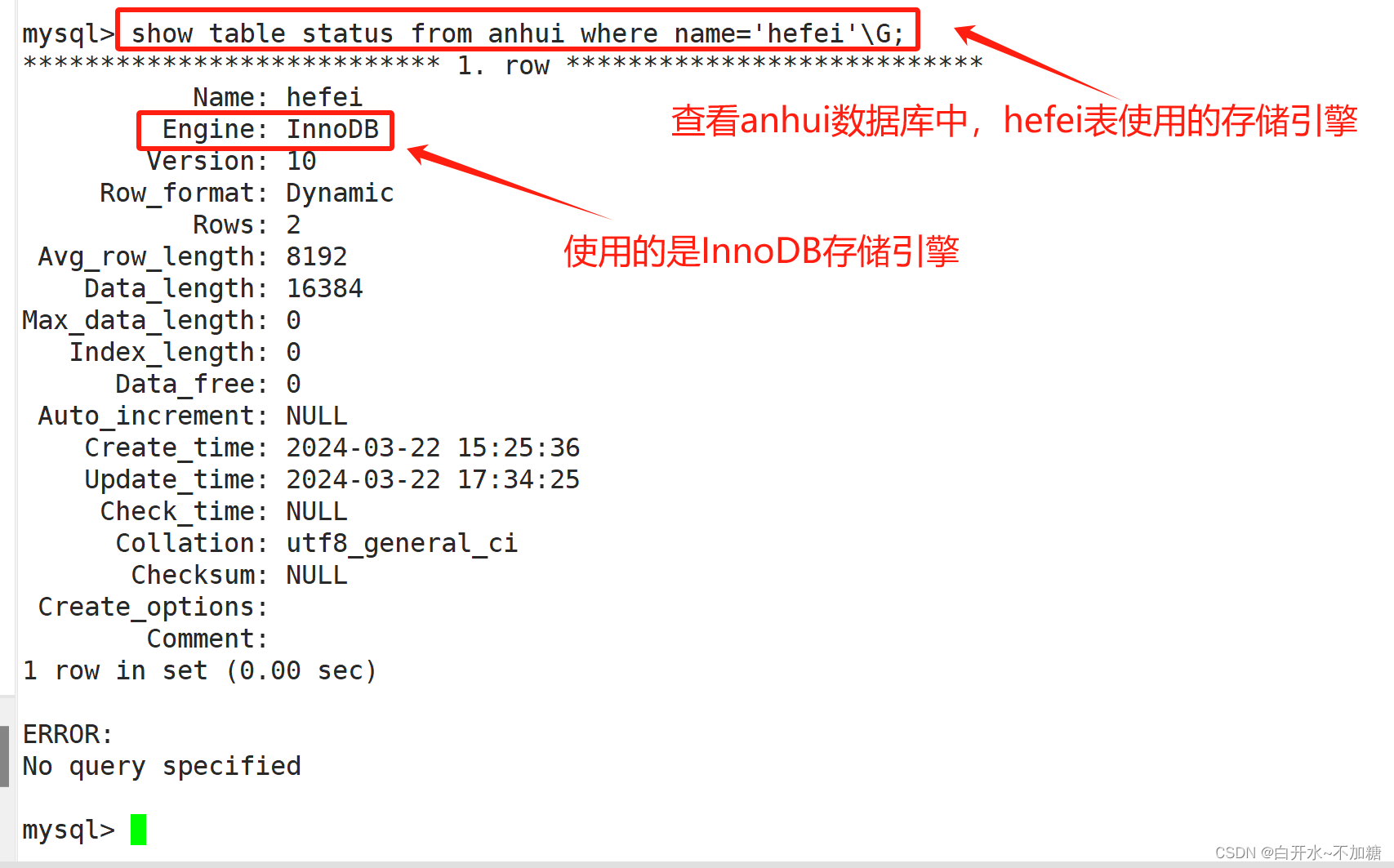
四、查看表使用的存储引擎
方法一:
show table status from 库名 where name='表名'\G
方法二:
use 库名;
show create table 表名;方法一
show table status from 库名 where name='表名'\G;例:show table status from SCHOOL where name='info'\G;
方法二
use 库名;
show create table 表名;例:use SCHOOL;
show create table info;

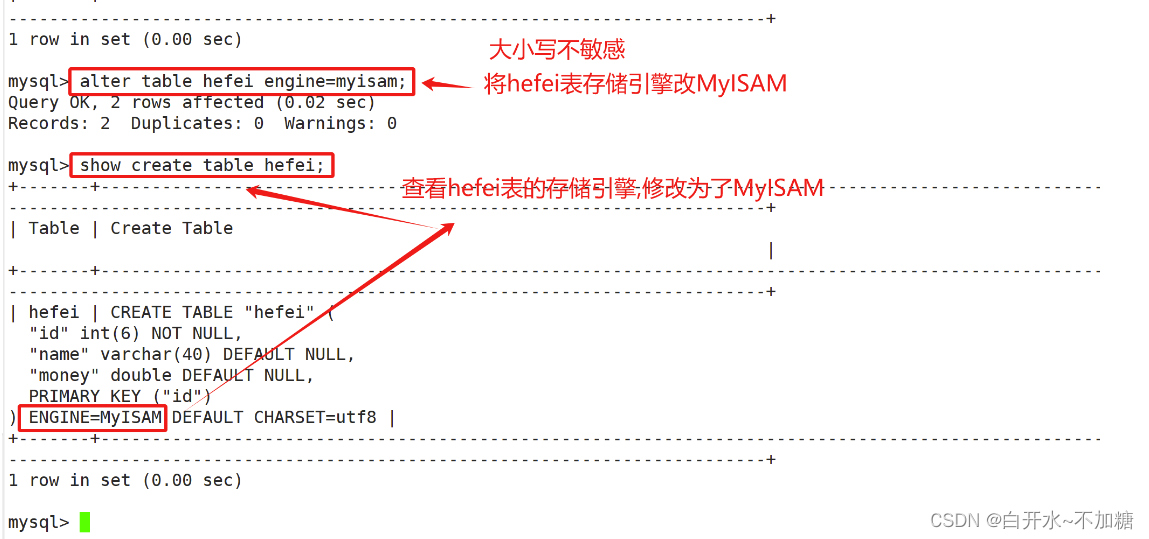
五、修改存储引擎
方法一:通过 alter table 修改
use 库名; alter table 表名 engine=MyISAM;

[root@localhost ~]#mysql -uroot -p123123
mysql> show databases; #查看所有库
+--------------------+
| Database |
+--------------------+
| information_schema |
| anhui |
| beijing |
| class |
| mysql |
| nanjing |
| performance_schema |
| sys |
+--------------------+
8 rows in set (0.00 sec)mysql> use anhui; #切换anhui库
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> show create table hefei;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| hefei | CREATE TABLE "hefei" ("id" int(6) NOT NULL,"name" varchar(40) DEFAULT NULL,"money" double DEFAULT NULL,PRIMARY KEY ("id")
) ENGINE=InnoDB DEFAULT CHARSET=utf8 | #存储引擎是InnoDB
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)mysql> alter table hefei engine=myisam; #修改存储引擎
Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> show create table hefei;
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| hefei | CREATE TABLE "hefei" ("id" int(6) NOT NULL,"name" varchar(40) DEFAULT NULL,"money" double DEFAULT NULL,PRIMARY KEY ("id")
) ENGINE=MyISAM DEFAULT CHARSET=utf8 | #存储引擎修改为MyISAM
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)mysql>
方法二:通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务vim /etc/my.cnf[mysqld]default-storage-engine=INNODB ----------------------------------- systemctl restart mysql.service修改完记得重启mysql服务
#注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更

此时创建一个表并查看所用的存储引擎





修改配置文件/etc/my.cnf 改为MyISAM存储引擎


查看原来feixi表的存储引擎
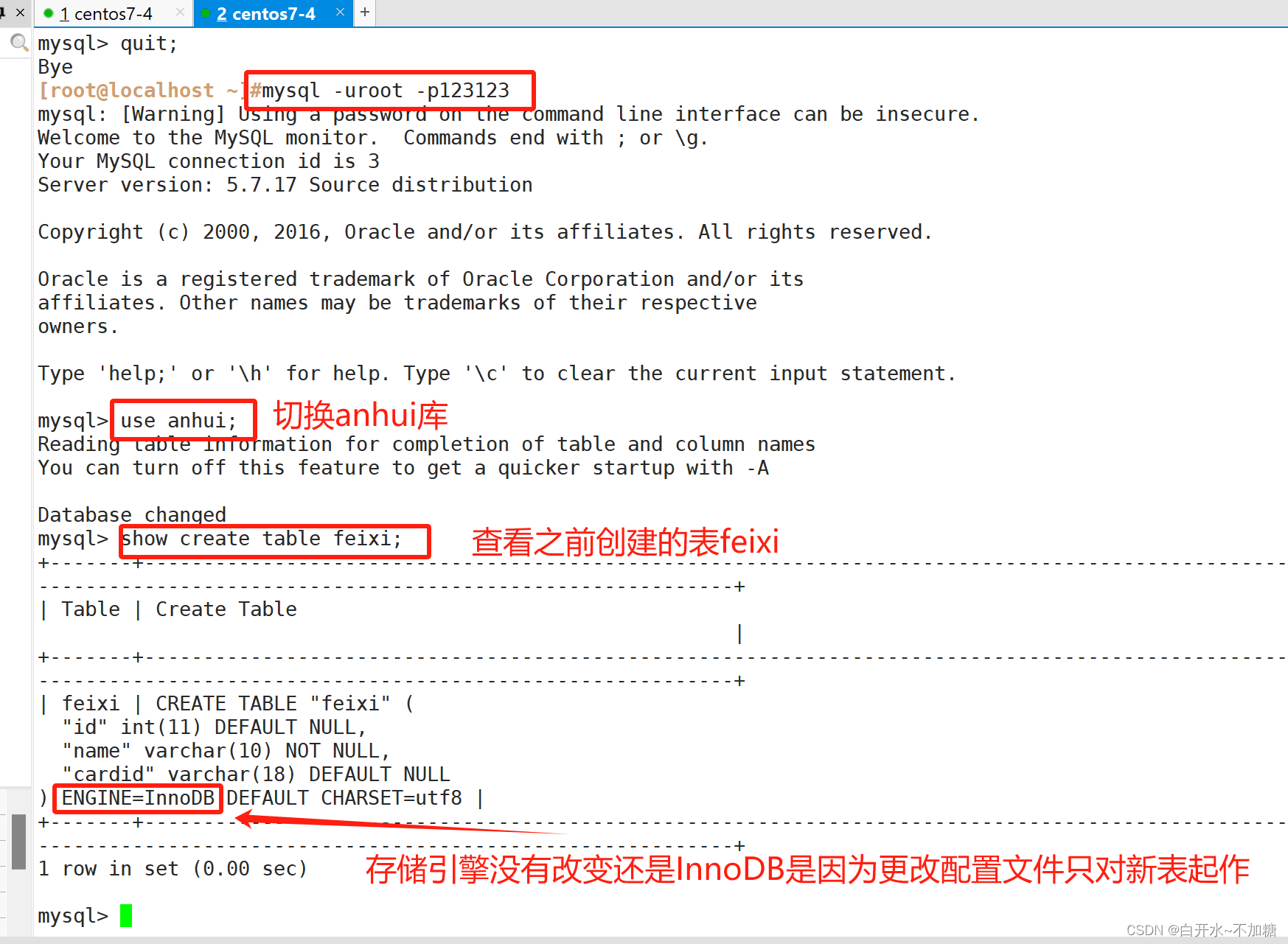
创建新表feidong查看存储引擎

此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更
方法三:通过 create table 创建表时指定存储引擎
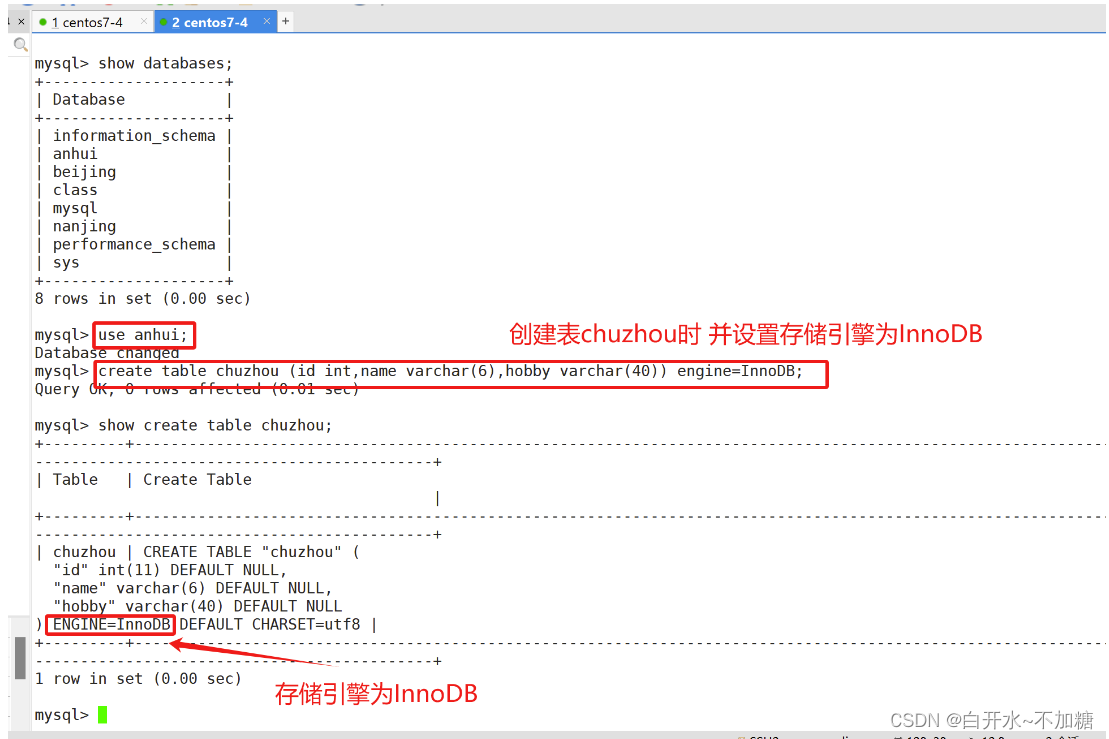
use 库名; create table 表名(字段1 数据类型,...) engine=MyISAM;例:mysql -u root -p
use SCHOOL;
create table hellolic (name varchar(10),age char(4)) engine=myisam;
这篇关于linux系统------------MySQL 存储引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







