本文主要是介绍Pytorch打怪路(三)Pytorch创建自己的数据集1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

之前讲的例子,程序都是调用的datasets方法,下载的torchvision本身就提供的数据,那么如果想导入自己的数据应该怎么办呢?
本篇就讲解一下如何创建自己的数据集。
还有第二篇……Pytorch打怪路(三)Pytorch创建自己的数据集2
1.用于分类的数据集
以mnist数据集为例
这里的mnist数据集并不是torchvision里面的,而是我自己的以图片格式保存的数据集,因为我在测试STN时,希望自己再把这些手写体做一些形变,
所以就先把MNIST数据集转化成了jpg图片格式,然后做了一些形变,当然这不是重点。首先我们看一下我的数据集的情况:
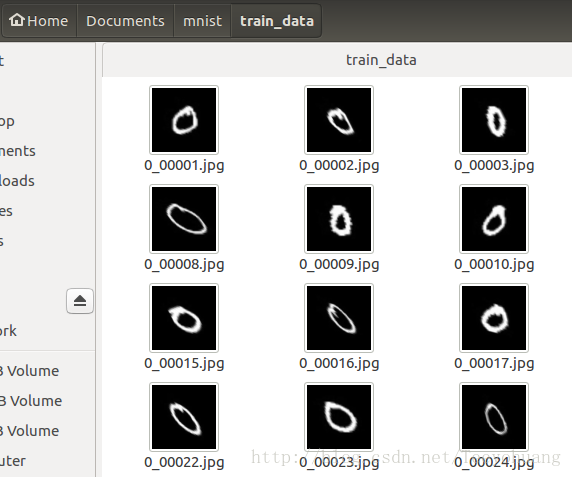
如图所示,我的图片数据集确实是jpg图片
再看我的存储图片名和label信息的文本:
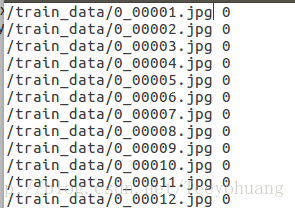
如图所示,我的mnist.txt文本每一行分为两部分,第一部分是具体路径+图片名.jpg
第二部分就是label信息,因为前面这部分图片都是0 ,所以他们的分类的label信息就是0
要创建你自己的 用于分类的 数据集,也要包含上述两个部分,1.图片数据集,2.文本信息(这个txt文件可以用python或者C++轻易创建,再此不详述)
2.代码
主要代码
from PIL import Image
import torchclass MyDataset(torch.utils.data.Dataset): #创建自己的类:MyDataset,这个类是继承的torch.utils.data.Datasetdef __init__(self,root, datatxt, transform=None, target_transform=None): #初始化一些需要传入的参数fh = open(root + datatxt, 'r') #按照传入的路径和txt文本参数,打开这个文本,并读取内容imgs = [] #创建一个名为img的空列表,一会儿用来装东西for line in fh: #按行循环txt文本中的内容line = line.rstrip() # 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询pythonwords = line.split() #通过指定分隔符对字符串进行切片,默认为所有的空字符,包括空格、换行、制表符等imgs.append((words[0],int(words[1]))) #把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lableself.imgs = imgsself.transform = transformself.target_transform = target_transformdef __getitem__(self, index): #这个方法是必须要有的,用于按照索引读取每个元素的具体内容fn, label = self.imgs[index] #fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息img = Image.open(root+fn).convert('RGB') #按照path读入图片from PIL import Image # 按照路径读取图片if self.transform is not None:img = self.transform(img) #是否进行transformreturn img,label #return很关键,return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容def __len__(self): #这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分return len(self.imgs)#根据自己定义的那个勒MyDataset来创建数据集!注意是数据集!而不是loader迭代器
train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor())
test_data=MyDataset(txt=root+'test.txt', transform=transforms.ToTensor())#然后就是调用DataLoader和刚刚创建的数据集,来创建dataloader,这里提一句,loader的长度是有多少个batch,所以和batch_size有关
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=64)
再补充一点代码,以便更好的理解 __getitem__这个方法
for batch_index, data, target in test_loader:if use_cuda:data, target = data.cuda(), target.cuda()data, target = Variable(data, volatile=True), Variable(target)这段代码是我从测试的部分中截取出来的,为什么直接能用for data, target In test_loader这样的语句呢?
其实这个语句还可以这么写:
for batch_index, batch in train_loader
data, target = batch
这样就好理解了,因为这个迭代器每一次循环所得的batch里面装的东西,就是我在__getitem__方法最后return回来的,
所以你想在训练或者测试的时候还得到其他信息的话,就去增加一些返回值即可,只要是能return出来的,就能在每个batch中读取到!
###############################################################################
有朋友可能想问,如果我的label信息不是数字而是图像呢?比如分割任务,它的label就是图像,这样的数据集的建立,也参考我的下一篇博文:
Pytorch打怪路(三)Pytorch创建自己的数据集2
这篇关于Pytorch打怪路(三)Pytorch创建自己的数据集1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






