本文主要是介绍20240316-2-协同过滤(collaborative filtering),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
协同过滤(collaborative filtering)
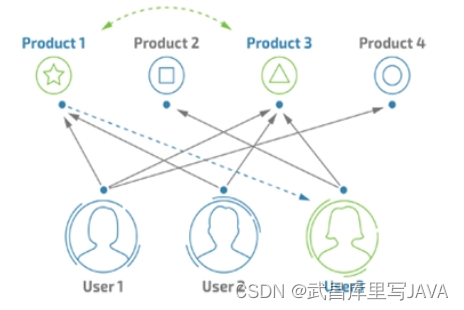
直观解释
协同过滤是推荐算法中最常用的算法之一,它根据user与item的交互,发现item之间的相关性,或者发现user之间的相关性,进行推荐。比如你有位朋友看电影的爱好跟你类似,然后最近新上了《调音师》,他觉得不错,就会推荐给你,这是最简单的基于user的协同过滤算法(user-based collaboratIve filtering),还有一种是基于item的协同过滤算法(item-based collaborative filtering),比如你非常喜欢电影《当幸福来敲门的时候》,那么观影系统可能会推荐一些类似的励志片给你,比如《风雨哈佛路》等。如下主要分析user-based,item-based同理。
核心公式
-
符号定义
r u , i r_{u,i} ru,i:user u u u 对 item i i i 的评分
r ˉ u \bar{r}_{u} rˉu:user u u u 的平均评分
P a , b P_{a,b} Pa,b:用户 a , b a,b a,b都有评价的items集合 -
核心公式
-
item-based CF 邻域方法预测公式
Pred ( u , i ) = r ‾ u + ∑ j ∈ S i ( sim ( i , j ) × r u , j ) ∑ j ∈ S i sim ( i , j ) \operatorname{Pred}(u, i)=\overline{r}_{u}+\frac{\sum_{j \in S_{i}}\left(\operatorname{sim}(i, j) \times r_{u, j}\right)}{\sum_{j \in S_{i}} \operatorname{sim}(i, j)} Pred(u,i)=ru+∑j∈Sisim(i,j)∑j∈Si(sim(i,j)×ru,j) -
偏差优化目标
min b ∑ ( u , i ) ∈ K ( r ( u , i ) − μ − b u − b i ) 2 \min _{b} \sum_{(u, i) \in K}\left(r_{(u, i)}-\mu-b_{u}-b_{i}\right)^{2} bmin(u,i)∈K∑(r(u,i)−μ−bu−bi)2
其中 ( u , i ) ∈ K (u,i) \in K (u,i)∈K表示所有的评分, μ \mu μ总评分均值, b u b_u bu为user u u u的偏差, b i b_i bi为item i i i 的偏差。 -
- 加入正则项后的Funk SVD 优化公式
min u v ∑ ( u , i ) ∈ k n o w n ( r u , i − u u v i ) + λ ( ∣ u ∣ 2 + ∣ v ∣ 2 ) \min _{u v} \sum_{(u, i) \in k n o w n}\left(r_{u,i}-u_{u} v_{i}\right)+\lambda\left(|u|^{2}+|v|^{2}\right) uvmin(u,i)∈known∑(ru,i−uuvi)+λ(∣u∣2+∣v∣2)
其中 u u u_u uu为user u u u的偏好,即为user特征矩阵 U U U的第 u u u行, v i v_i vi为item i i i的特征,即为特征矩阵 V V V的第 i i i列
- 加入正则项后的Funk SVD 优化公式
注意要点
-
相似度与距离之间的关系
距离越大,相似度越小;距离越小,相似度越高。即在求解最大相似度的时候可以转为求解最小距离。 -
在协同过滤中,常用的相似度函数有哪些,简要说明
- 杰卡德相似度(Jaccard similarity)
公式:
s i m j a c c a r d ( u 1 , u 2 ) = items bought by u 1 a n d u 2 items bought by u 1 o r u 2 sim_{jaccard}(u_{1}, u_{2})=\frac{ \text {items} \text { bought by } u_{1}\ and\ u_{2}}{ \text { items bought by } u_{1}\ or\ u_{2}} simjaccard(u1,u2)= items bought by u1 or u2items bought by u1 and u2
适用于二元情况,即定性情况,比如买或者没买,喜欢或者不喜欢,在数据稀疏的情况,可以转为二元应用。- 余弦相似度
公式: sim ( u 1 , u 2 ) = r u 1 ⋅ r u 2 ∣ r u 1 ∣ 2 ∣ r u 2 ∣ 2 = ∑ i ∈ P u 1 , u 2 r u 1 , i r u 2 , i ∑ i ∈ P u 1 r u 1 , i 2 ∑ i ∈ P u 2 r u 2 , i 2 \operatorname{sim}(u_{1}, u_{2})=\frac{r_{u_{1}} \cdot r_{u_{2}}}{\left|r_{u_{1}}\right|_{2}|r_{u_{2}}|_{2}}=\frac{\sum_{i \in P_{u_1,u_2}} r_{u_{1}, i} r_{u_{2}, i}}{\sqrt{\sum_{i \in P_{u_1}} r_{u_{1},i}^{2}} \sqrt{\sum_{i \in P_{u_2}}r_{u_{2},i}^{2}}} sim(u1,u2)=∣ru1∣2∣ru2∣2ru1⋅ru2=∑i∈Pu1ru1,i2∑i∈Pu2ru2,i2∑i∈Pu1,u2ru1,iru2,i
考虑不同用户的评价范围不一样,比如乐天派一般评分范围一般会高于悲观的人,会将评分进行去中心化再进行计算,即 - 修正余弦相似度,公式变为
sim ( u 1 , u 2 ) = r u 1 ⋅ r u 2 ∣ r u 1 ∣ 2 ∣ r u 2 ∣ 2 = ∑ i ∈ P u 1 , u 2 ( r u 1 , i − r ˉ u 1 ) ( r u 2 , i − r ˉ u 2 ) ∑ i ∈ P u 1 ( r u 1 , i − r ˉ u 1 ) 2 ∑ i ∈ P u 2 ( r u 2 , i − r ˉ u 2 ) 2 \operatorname{sim}(u_{1}, u_{2})=\frac{r_{u_{1}} \cdot r_{u_{2}}}{\left|r_{u_{1}}\right|_{2}|r_{u_{2}}|_{2}}=\frac{\sum_{i \in P_{u_1,u_2}} (r_{u_{1}, i}-{\bar{r}_{u_{1}}}) (r_{u_{2}, i}-\bar{r}_{u_2})}{\sqrt{\sum_{i \in P_{u_1}} (r_{u_{1},i}-\bar{r}_{u_{1}})^{2}} \sqrt{\sum_{i \in P_{u_2}}(r_{u_{2},i}-\bar{r}_{u_{2}})^{2}}} sim(u1,u2)=∣ru1∣2∣ru2∣2ru1⋅ru2=∑i∈Pu1(ru1,i−rˉu1)2∑i∈Pu2(ru2,i−rˉu2)2∑i∈Pu1,u2(ru1,i−rˉu1)(ru2,i−rˉu2)
适用于定量情况,比如评分场景,要求数据具有一定的稠密度。注意如果计算一个评价很少电影的用户与一个评价很多电影的用户会导致相似度为0. - 皮尔森相关系数
公式:
sim ( u 1 , u 2 ) = ∑ i ∈ P u 1 . u 2 ( r u 1 , i − r ‾ u 1 ) ( r u 2 , i − r ‾ u 2 ) ∑ i ∈ P u 1 . u 2 ( r u 1 , i − r ‾ u 1 ) 2 ∑ i ∈ P u 1 . u 2 ( r u 2 , i − r ‾ u 2 ) 2 \operatorname{sim}(u_1, u_2)=\frac{\sum_{i \in P_{u_1.u_2}}\left(r_{u_1, i}-\overline{r}_{u_1}\right)\left(r_{u_2, i}-\overline{r}_{u_2}\right)}{\sqrt{\sum_{i \in P_{u_1.u_2}}\left(r_{u_1, i}-\overline{r}_{u_1}\right)^{2}} \sqrt{\sum_{i \in P_{u_1.u_2}}\left(r_{u_2, i}-\overline{r}_{u_2}\right)^{2}}} sim(u1,u2)=∑i∈Pu1.u2(ru1,i−ru1)2∑i∈Pu1.u2(ru2,i−ru2)2∑i∈Pu1.u2(ru1,i−ru1)(ru2,i−ru2)
皮尔森系数跟修正的余弦相似度几乎一致,两者的区别在于分母上,皮尔逊系数的分母采用的评分集是两个用户的共同评分集(就是两个用户都对这个物品有评价),而修正的余弦系数则采用两个用户各自的评分集。 - L p − n o r m s L_{p}-norms Lp−norms
公式: s i m ( u 1 , u 2 ) = 1 ∣ r u 1 − r u 2 ∣ p p + 1 sim(u_1,u_2) =\frac{1}{ \sqrt[p]{| r_{u_1}-r_{u_2} |^p}+1} sim(u1,u2)=p∣ru1−ru2∣p+11
p p p取不同的值对应不同的距离公式,空间距离公式存在的不足这边也存在。对数值比较敏感。
- 余弦相似度
- 杰卡德相似度(Jaccard similarity)
-
有了相似度测量后,那么基于邻域的推荐思路是怎样的呢?
过滤掉被评论较少的items以及较少评价的users,然后计算完users之间的相似度后,寻找跟目标user偏好既有大量相同的items,又存在不同的items的近邻几个users(可采用K-top、阈值法、聚类等方式),然后进行推荐。步骤如下:
(1) 选择:选出最相似几个用户,将这些用户所喜欢的物品提取出来并过滤掉目标用户已经喜欢的物品
(2) 评估:对余下的物品进行评分与相似度加权
(3) 排序:根据加权之后的值进行排序
(4) 推荐:由排序结果对目标用户进行推荐 -
协同过滤算法具有特征学习的特点,试解释原理以及如何学习
- 特征学习:把users做为行,items作为列,即得评分矩阵 R m , n = [ r i , j ] R_{m,n}=[r_{i,j}] Rm,n=[ri,j],通过矩阵分解的方式进行特征学习,即将评分矩阵分解为 R = U m , d V d , n R=U_{m,d}V_{d,n} R=Um,dVd,n,其中 U m , d U_{m,d} Um,d为用户特征矩阵, V d , n V_{d,n} Vd,n表示items特征矩阵,其中 d d d表示对items进行 d d d个主题划分。举个简单例子,比如看电影的评分矩阵划分后, U U U中每一列表示电影的一种主题成分,比如搞笑、动作等, V V V中每一行表示一个用户的偏好,比如喜欢搞笑的程度,喜欢动作的程度,值越大说明越喜欢。这样,相当于,把电影进行了主题划分,把人物偏好也进行主题划分,主题是评分矩阵潜在特征。
- 学习方式
-
-
SVD,分解式为 R m , n = U m , m Σ m , n V n , n T R_{m,n}=U_{m,m}\Sigma_{m,n}V_{n,n}^T Rm,n=Um,mΣm,nVn,nT
其中 U U U为user特征矩阵, Σ \Sigma Σ为权重矩阵体现对应特征提供的信息量, V V V为item特征矩阵。同时可通过SVD进行降维处理,如下奇异值分解的方式,便于处理要目标user(直接添加到用户特征矩阵的尾部即可),然而要求评分矩阵元素不能为空,因此需要事先进行填充处理,同时由于user和item的数量都比较多,矩阵分解的方式计算量大,且矩阵为静态的需要随时更新,因此实际中比较少用。
-
-
-
Funk SVD, Funk SVD 是去掉SVD的 Σ \Sigma Σ成分,优化如下目标函数,可通过梯度下降法,得到的 U , V U,V U,V矩阵
J = min u v ∑ ( u , i ) ∈ k n o w n ( r u , i − u u v i ) + λ ( ∣ u ∣ 2 + ∣ v ∣ 2 ) J=\min _{u v} \sum_{(u, i) \in k n o w n}\left(r_{u,i}-u_{u} v_{i}\right)+\lambda\left(|u|^{2}+|v|^{2}\right) J=uvmin(u,i)∈known∑(ru,i−uuvi)+λ(∣u∣2+∣v∣2)
Funk SVD 只要利用全部有评价的信息,不需要就空置进行处理,同时可以采用梯度下降法,优化较为方便,较为常用。有了user特征信息和item特征信息,就可用 u u v i u_{u} v_{i} uuvi对目标用户进行评分预测,如果目标用户包含在所计算的特征矩阵里面的话。针对于新user、新item,协同过滤失效。
-
-
如何简单计算user偏差以及item偏差?
b u = 1 ∣ I u ∣ ∑ i ∈ I u ( r u , i − μ ) b i = 1 ∣ U i ∣ ∑ u ∈ U i ( r u , i − b u − μ ) b_u=\frac{1}{|I_u|}\sum_{i \in I_u}(r_{u,i}-\mu) \ b_i=\frac{1}{|U_i|}\sum_{u \in U_i}(r_{u,i}-b_u-\mu) bu=∣Iu∣1i∈Iu∑(ru,i−μ) bi=∣Ui∣1u∈Ui∑(ru,i−bu−μ) -
如何选择协同过滤算法是基于user还是基于item
一般,谁的量多就不选谁。然而基于user的会给推荐目标带来惊喜,选择的范围更为宽阔,而不是基于推荐目标当前的相似item。因此如果要给推荐目标意想不到的推荐,就选择基于user的方式。可以两者结合。 -
协同过滤的优缺点
- 缺点:
(1)稀疏性—— 这是协同过滤中最大的问题,大部分数据不足只能推荐比较流行的items,因为很多人只有对少量items进行评价,而且一般items的量非常多,很难找到近邻。导致大量的user木有数据可推荐(一般推荐比较流行的items),大量的item不会被推荐
(2)孤独用户——孤独user具有非一般的品味,难以找到近邻,所以推荐不准确
(3) 冷启动——只有大量的评分之后,才能协同出较多信息,所以前期数据比较少,推荐相对不准确;而如果没有人进行评分,将无法被推荐
(4)相似性——协同过滤是与内容无关的推荐,只根据用户行为,所以倾向于推荐较为流行的items。
- 缺点:
-
优点:
(1)不需要领域知识,存在users和items的互动,便能进行推荐(2)简单易于理解
(3)相似度计算可预计算,预测效率高 -
协同过滤与关联规则的异同
关联规则是不考虑tems或者使用它们的users情况下分析内容之间的关系,而协同过滤是不考虑内容直接分析items之间的关系或者users之间的关系。两者殊途同归均能用于推荐系统,但是计算方式不同。 -
实践中的一些注意点
(1) 过滤掉被评价较少的items
(2) 过滤掉评价较少的users
(3) 可用聚类方式缩小搜索空间,但是面临找不到相同偏好的用户(如果用户在分界点,被误分的情况),这种方式通过缩小搜索空间的方式优化协同过滤算法
(4) 使用的时候,可以考虑时间范围,偏好随着时间的改变会改变
面试真题
使用协同过滤算法之前,数据应该如何进行预处理?
协同过滤的方式有哪些?
如何通过相似度计算设计协同过滤推荐系统?
请谈谈你对协同过滤中特征学习的理解?
如何将协同过滤用于推荐系统?
FUNK SVD相对于SVD有哪些优势?
如何求解FUNK SVD?
请描述下协同过滤的优缺点?
这篇关于20240316-2-协同过滤(collaborative filtering)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





