本文主要是介绍MPViT实战:植物幼苗分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 数据增强Cutout和Mixup
- 项目结构
- 数据集
- 导入模型文件
- 安装库,并导入需要的库
- 设置全局参数
- 数据预处理
- 数据读取
- 设置模型
- 定义训练和验证函数
- 测试
- 第一种写法
- 第二种写法
摘要
结合重叠卷积块嵌入,MPViT可以同时对不同尺度、相同序列长度特征进行嵌入聚合。不同尺度的Token分别送入到不同的Transformer模块中(即并行架构)以构建同特征层级的粗粒度与细粒度特征的。
在ImageNet分类任务中:
-
在同等参数量与计算复杂度约束下,MPViT取得了比有ViT架构更优的性能;
-
MPViT-XS与Small分别比CoaT-Lite Mini与Small性能高2.0%、1.1%;
-
MPViT-Small具有更大网络PVT-L、DeiT-B/16、XCiT-M24/16更优的性能;
-
MPViT-B以74M参数量取得了84.3%的指标,超过了近期同等参数的Swin-Base以及Focal-Base。
在COCO检测任务中:
-
相比同尺寸的其他ViT方案,MPViT均取得了更优的性能;
-
基于RetinaNet,MPViT-S取得了47.6%的指标,超越了Swin-T与Focal-T;
-
基于Mask R-CNN,MPViT-XS与MPViT-S优于同尺寸的CoaT-Lite Mini与Small;值得一提的是,MPViT-S取得了比XCiT-M24/8和Focal-B更高的指标,同时具有更少的FLOPs。
在ADE20K分割任务中:
-
MPViT优于其他同尺寸的ViT方案;
-
MPViT-S以48.3%的指标大幅超越了Swin-T、Focal-T以及XCiT-S12/16;
-
MPViT-B以50.3%的指标超越了近期SOTA方案Focal-B。
论文链接:https://arxiv.org/abs/2112.11010
github地址:https://git.io/MPViT
gitee地址:AIhao4585/MPViT (gitee.com)
本文使用植物幼苗数据集,实现图像分类任务。通过本文你可以学到:
1、如何使用官方的mpvit.py模型实现分类任务?
2、如何自定义数据集加载方式?
3、如何使用Cutout数据增强?
4、如何使用Mixup数据增强?
5、如何自定义分类类别?
6、如何实现训练和验证?
7、预测的两种写法。
数据增强Cutout和Mixup
ConvNext使用了Cutout和Mixup,为了提高成绩我在我的代码中也加入这两种增强方式。官方使用timm,我没有采用官方的,而选择用torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout# 数据预处理transform = transforms.Compose([transforms.Resize((224, 224)),Cutout(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
Mixup实现,在train方法中。需要导入包:from torchtoolbox.tools import mixup_data, mixup_criterion
for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)data, labels_a, labels_b, lam = mixup_data(data, target, alpha)optimizer.zero_grad()output = model(data)loss = mixup_criterion(criterion, output, labels_a, labels_b, lam)loss.backward()optimizer.step()print_loss = loss.data.item()
项目结构
使用tree命令,打印项目结构
MPViT_demo
├─data
│ ├─test
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─dataset
│ ├─ __init__.py
│ └─ dataset.py
├─Model
│ └─mpvit.py
├─ test1.py
├─ test2.py
└─ train.py
mpvit.py:来自官方的代码中。
train.py:本文定义。
dataset.py:本文定义
test1.py:本文定义
test2.py:本文定义
数据集
数据集选用植物幼苗分类,总共12类。数据集连接如下:
链接:https://pan.baidu.com/s/1TOLSNj9JE4-MFhU0Yv8TNQ
提取码:syng
在工程的根目录新建data文件夹,获取数据集后,将trian和test解压放到data文件夹下面,如下图:
导入模型文件
从官方的链接中找到mpvit.py文件,将其放入Model文件夹中。如图:
安装库,并导入需要的库
模型用到了timm库,如果没有需要安装,执行命令:
pip install timm
新建train_connext.py文件,导入所需要的包:
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transformsfrom dataset.dataset import SeedlingData
from torch.autograd import Variable
from Model.mpvit import mpvit_tiny
from torchtoolbox.tools import mixup_data, mixup_criterion
from torchtoolbox.transform import Cutout
设置全局参数
设置使用GPU,设置学习率、BatchSize、epoch等参数。
# 设置全局参数
modellr = 1e-4
BATCH_SIZE = 8
EPOCHS = 300
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据预处理
数据处理比较简单,没有做复杂的尝试,有兴趣的可以加入一些处理。
# 数据预处理transform = transforms.Compose([transforms.Resize((224, 224)),Cutout(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
数据读取
然后我们在dataset文件夹下面新建 init.py和dataset.py,在datasets.py文件夹写入下面的代码:
# coding:utf8
import os
from PIL import Image
from torch.utils import data
from torchvision import transforms as T
from sklearn.model_selection import train_test_splitLabels = {'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3,'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7, 'Scentless Mayweed': 8,'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}class SeedlingData(data.Dataset):def __init__(self, root, transforms=None, train=True, test=False):"""主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据"""self.test = testself.transforms = transformsif self.test:imgs = [os.path.join(root, img) for img in os.listdir(root)]self.imgs = imgselse:imgs_labels = [os.path.join(root, img) for img in os.listdir(root)]imgs = []for imglable in imgs_labels:for imgname in os.listdir(imglable):imgpath = os.path.join(imglable, imgname)imgs.append(imgpath)trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42)if train:self.imgs = trainval_fileselse:self.imgs = val_filesdef __getitem__(self, index):"""一次返回一张图片的数据"""img_path = self.imgs[index]img_path = img_path.replace("\\", '/')if self.test:label = -1else:labelname = img_path.split('/')[-2]label = Labels[labelname]data = Image.open(img_path).convert('RGB')data = self.transforms(data)return data, labeldef __len__(self):return len(self.imgs)
说一下代码的核心逻辑。
第一步 建立字典,定义类别对应的ID,用数字代替类别。
第二步 在__init__里面编写获取图片路径的方法。测试集只有一层路径直接读取,训练集在train文件夹下面是类别文件夹,先获取到类别,再获取到具体的图片路径。然后使用sklearn中切分数据集的方法,按照7:3的比例切分训练集和验证集。
第三步 在__getitem__方法中定义读取单个图片和类别的方法,由于图像中有位深度32位的,所以我在读取图像的时候做了转换。
然后我们在train.py调用SeedlingData读取数据 ,记着导入刚才写的dataset.py(from mydatasets import SeedlingData)
# 读取数据
dataset_train = SeedlingData('data/train', transforms=transform, train=True)
dataset_test = SeedlingData("data/train", transforms=transform_test, train=False)
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型
设置loss函数为nn.CrossEntropyLoss()。
-
设置模型为mpvit_tiny,修改最后一层全连接输出改为12(数据集的类别)。
-
优化器设置为adam。
-
学习率调整策略改为余弦退火
# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
#criterion = SoftTargetCrossEntropy()
model_ft = mpvit_tiny()num_ftrs = model_ft.cls_head.cls.in_features
model_ft.cls_head.cls = nn.Linear(num_ftrs, 12)
model_ft.to(DEVICE)
print(model_ft)# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=20,eta_min=1e-9)
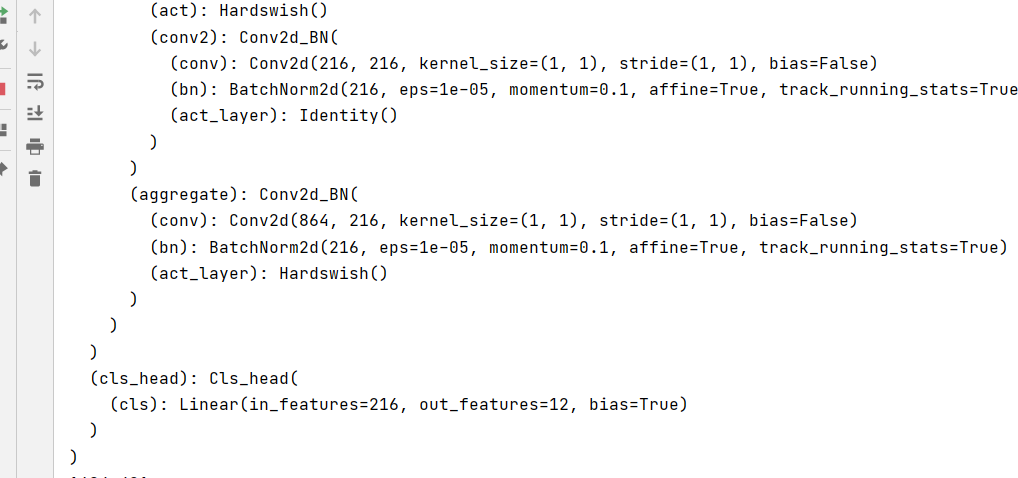
通过输出模型的最后一层,可以看出,输出的类别已经变成我们设定的类别了。
定义训练和验证函数
alpha=0.2 Mixup所需的参数。
# 定义训练过程
alpha=0.2
def train(model, device, train_loader, optimizer, epoch):model.train()sum_loss = 0total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)data, labels_a, labels_b, lam = mixup_data(data, target, alpha)optimizer.zero_grad()output = model(data)loss = mixup_criterion(criterion, output, labels_a, labels_b, lam)loss.backward()optimizer.step()print_loss = loss.data.item()sum_loss += print_lossif (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item()))ave_loss = sum_loss / len(train_loader)print('epoch:{},loss:{}'.format(epoch, ave_loss))ACC=0
# 验证过程
def val(model, device, test_loader):global ACCmodel.eval()test_loss = 0correct = 0total_num = len(test_loader.dataset)print(total_num, len(test_loader))with torch.no_grad():for data, target in test_loader:data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)_, pred = torch.max(output.data, 1)correct += torch.sum(pred == target)print_loss = loss.data.item()test_loss += print_losscorrect = correct.data.item()acc = correct / total_numavgloss = test_loss / len(test_loader)print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(avgloss, correct, len(test_loader.dataset), 100 * acc))if acc > ACC:torch.save(model_ft, 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')ACC = acc# 训练for epoch in range(1, EPOCHS + 1):train(model_ft, DEVICE, train_loader, optimizer, epoch)cosine_schedule.step()val(model_ft, DEVICE, test_loader)然后就可以开始训练了

由于没有使用预训练模型,训练20个epoch能得到80%的正确率,

测试
第一种写法
测试集存放的目录如下图:
第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
classes = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
第三步 加载model,并将模型放在DEVICE里。
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model_8_0.971.pth")
model.eval()
model.to(DEVICE)
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
path = 'data/test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))
测试完整代码:
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import osclasses = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model_8_0.971.pth")
model.eval()
model.to(DEVICE)path = 'data/test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))
运行结果:

第二种写法
第二种,使用自定义的Dataset读取图片。前三步同上,差别主要在第四步。读取数据的时候,使用Dataset的SeedlingData读取。
dataset_test =SeedlingData('data/test/', transform_test,test=True)
print(len(dataset_test))
# 对应文件夹的labelfor index in range(len(dataset_test)):item = dataset_test[index]img, label = itemimg.unsqueeze_(0)data = Variable(img).to(DEVICE)output = model(data)_, pred = torch.max(output.data, 1)print('Image Name:{},predict:{}'.format(dataset_test.imgs[index], classes[pred.data.item()]))index += 1
运行结果:
完整代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/79292167
这篇关于MPViT实战:植物幼苗分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





