本文主要是介绍社区AIOps Live Benchmark工作启动,欢迎加入!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CCF OpenAIOps社区(https://open.aiops.cn)在线评测基准(AIOps Live Benchmark)工作已经在春节后正式启动。特别感谢来自清华大学、中国科学院计算机网络信息中心、南开大学、必示科技、乐维、蓝鲸、云杉网络、听云、纵目科技、阿里云、蚂蚁金服等单位的专家们提供的设备资源和技术支持。目前乐维、蓝鲸、DeepFlow、ChaosMeta等工具在社区各参与单位的帮助下,已完成系统上线。
首批在线评测基准工作组成员由来自发起单位及各高校、企业的社区报名志愿参与的专家团队组成,目前已组建可观测性、数据、混沌工程等各小组,工作陆续启动、井然有序、稳步推进。后续我们会持续同步工作组的工作进展,以及面向全社区组织交流和经验分享。
AIOps Live Benchmark工作介绍
在线评测基准(AIOps Live Benchmark)是在真实的IT系统上,通过混沌工程工具模拟真实的运维场景,通过可观测工具获取实时数据,在线评测AIOps应用,最终提供权威的评测基准和真实数据。下面Benchmark中一些常见组件举例:
IT系统:TrainTicket 、Online Boutique、DeathStartBench等
混沌工程工具:ChaosMeta、ChaosBlade等
可观测工具:Promethues、Skywalking、Zabbix等
AIOps应用:异常检测、告警分析、根因定位等应用等
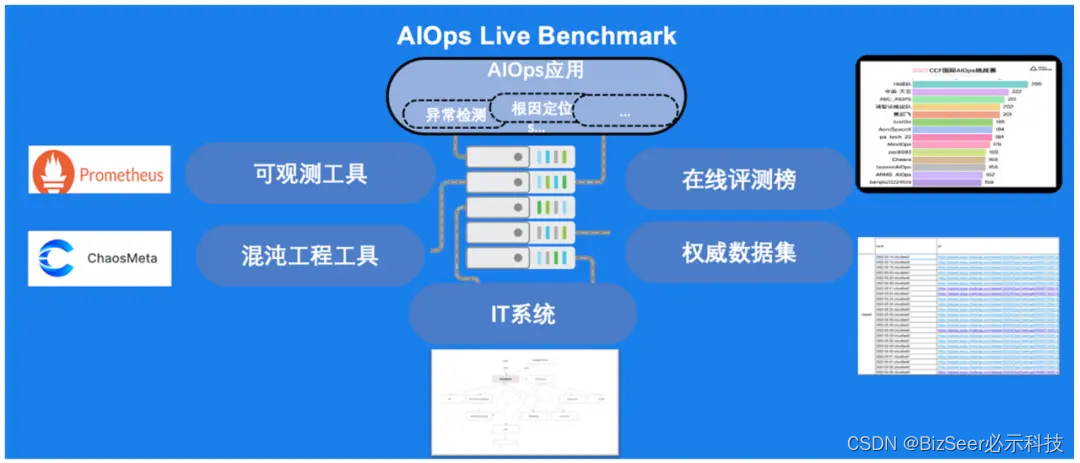
在线评测基准系统将是在AIOps领域中的一个重要创新,其价值主要体现在以下几个方面:
真实的IT运维场景
在真实的IT系统上,利用流量模拟和混沌工程工具,模拟多种运维场景,测试AIOps解决方案有效性和鲁棒性。
前沿的可观测性技术
集成了听云、乐维、蓝鲸、DeepFlow、SkyWalking等前沿的可观测技术工具,实现丰富的指标、日志、Trace数据收集。
标准化评估指标
为AIOps应用提供一套标准化的评估指标和排行榜。促进技术的发展和创新,同时也为用户选择合适的工具提供了参考。
权威AIOps数据集
为运维应用开发人员和科研人员提供真实的运维数据和场景,用于学术研究、产品测试和评测打榜。
目标和收益
建设目标
构建真实的运维平台
建设并评测现有异常检测、告警分析、故障定位等AIOps应用的实际效果
发布运维应用的权威数据集和评测基准
预期收益
运维人员能够快速了解一些常见的运维问题、运维工具和对应AIOps解决方案
运维专家能够发布自己关注的运维难题,利用社区力量去解决
科研人员和运维应用开发人员可以获取真实运维数据,用于学术研究、产品测试、评测打榜
系统概要
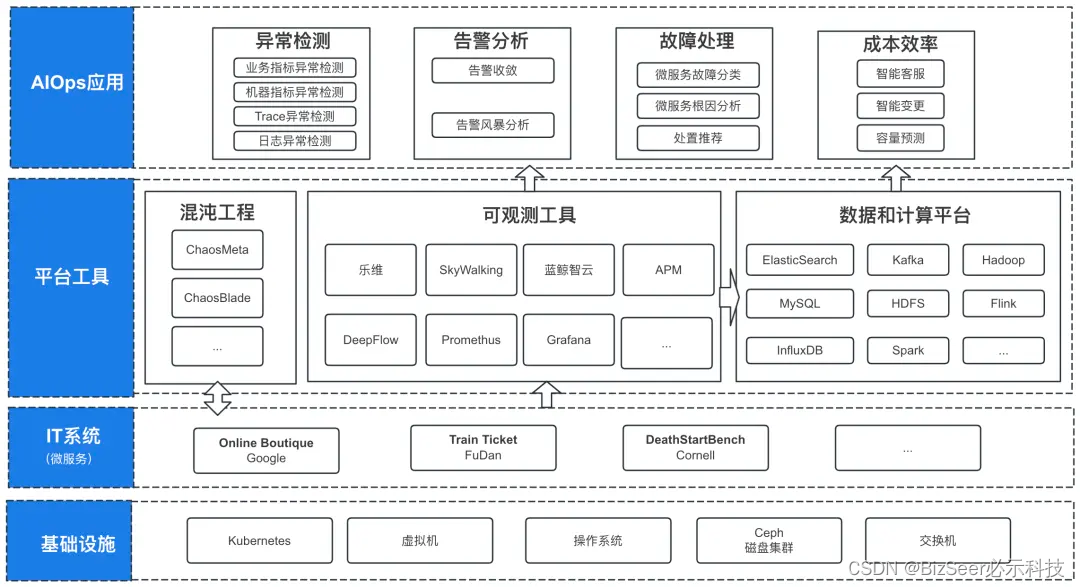
目前在线评测基准的业务架构,主要分为四层:
1、基础设施层:目前IT系统部署在中科院的中国科技云上,基础设施包括虚拟机、Kubernetes、Ceph磁盘集群等,支撑IT系统部署。
2、IT系统层:
当前被运维的IT系统为Online Boutique等开源的微服务系统;
后续如果有新的运维场景,可以部署其他类型IT系统。
3、平台工具层:
混沌工程工具:模拟真实运维问题,通过模拟服务流量并对IT系统注入真实的故障,驱动整个在线评测基准工作;
可观测工具:采集IT服务的指标、拓扑、日志等运维数据,同时配置监控产生告警,供AIOps应用和数据平台使用;
数据和计算平台:统一收集、存储告警、指标、日志等运维数据,供AIOps应用分析。此外提供Flink或者Spark计算集群,支撑AIOps应用的运行。
4、AIOps应用层:根据发布的评测基准,建设对应的AIOps应用,目前可以分为四部分:
异常检测:主要为故障发现的应用,包括业务指标异常检测、机器指标异常检测、调用链异常检测、日志异常检测等场景;
告警分析:包括智能告警收敛、告警风暴分析定界等场景;
故障处理:包括微服务故障分类、根因分析、处置推荐等场景;
成本效率:包括智能客户(基于大模型)、智能变更检测、容量预测等场景。
近期任务
近期计划完成微服务的异常检测根因分析的评测基准的制定,同时构建在线评测平台。欢迎各位专家参与贡献,具体包括但不限于以下这些任务:
1、搭建并维护微服务Google Online Boutique
任务说明:在中国科技云上搭建5台机器规模的微服务,并且持续维护,保证系统的可用性,用于后续监测和分析。
2、搭建并维护乐维监控工具
任务说明:在云上安装和配置乐维工具,以确保其在环境中顺利运行。预期该工具能够做指标、拓扑等数据采集,同时提供监控告警,支持后续业务指标、机器指标、告警分析等AIOps应用。
3、搭建并维护APM工具
任务说明:部署听云等APM工具并完成配置,以实现应用性能管理(APM)功能。该工具提供业务性能追踪,配置智能监控告警,采集拓扑、指标等运维数据,将相关的运维数据做对应的输出,支持后续异常检测、故障定位等AIOps应用。
4、搭建并维护蓝鲸可观测工具
任务说明:部署蓝鲸工具并完成配置。该工具提供业务性能追踪,配置智能监控告警,采集拓扑、指标等运维数据,将相关的运维数据做对应的输出,支持后续异常检测、故障定位等AIOps应用。
5、搭建并维护DeepFlow搭建
任务说明:部署DeepFlow并完成配置,实现基于eBPF的全套产品功能,能够输出相关的数据,支持后续异常检测、故障定位等AIOps应用。
6、搭建并维护Skywalking工具
任务说明:部署并配置SkyWalking,一个观测性分析平台和应用性能管理系统。通过这项任务,预期能够实现对应用程序的性能监控、追踪分析以及依赖关系的探索,支持后续调用链检测、故障定位等AIOps应用。
7、搭建并维护ChaosMeta
任务说明:部署ChaosMeta工具,以支持混沌工程流量模拟、故障注入等功能。故障具体涉及微服务POD、Node、Service中常见的CPU、内存、磁盘、网络等异常,尽可能模拟真实的各种故障情况。
8、搭建并维护ChaosBlade
任务说明:部署ChaosMeta工具,以支持混沌工程流量模拟、故障注入等功能。故障具体涉及微服务POD、Node、Service中常见的CPU、内存、磁盘、网络等异常,尽可能模拟真实的各种故障情况。
9、数据和计算平台搭建
任务说明:设计并部署运维数据平台。在数据存储方面,涉及指标、日志、告警、拓扑的存储方案,供AIOps应用评测使用,同时定期发布相应的评测数据集;在计算方面,按AIOps应用需求部署Flink 或者Spark计算集群。
10、制定微服务异常检测评测基准
任务说明: 根据真实的运维需求,设计异常检测的评测基准。具体可以先以业务指标、机器指标异常检测的评测基准为基础,参考历届AIOps挑战赛方案,给出具体的标注规则和评分机制。最终确保评测基准能够在现有搭建的平台上进行测试评估。
11、制定微服务根因定位评测基准
任务说明: 根据真实的运维需求,设计根因定位的评测基准。可参考历届AIOps挑战赛方案,并给出具体的标注规则和评分机制。最终确保评测基准能够在现有搭建的平台上进行测试评估。
参考资料
历届挑战赛AIOps应用场景
http://aiops-challenge.com
欢迎感兴趣的社区成员加入在线评测工作组中,可扫码填写问卷并具体描述希望参与的工作内容和相关经验,感谢对社区工作的支持!

这篇关于社区AIOps Live Benchmark工作启动,欢迎加入!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





