本文主要是介绍大模型来了,你的“存力”攒够了吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者 | 曾响铃
文 | 响铃说
提到AI、大模型,很多人脑海里最先想到的是算力、算法、数据这“三驾马车”。
而要论谁最重要,恐怕多数人都会觉得是算力。
毕竟,“算力紧缺”的气氛常常被渲染起来。
然而,随着大模型进一步演进,不同要素的资源配置情况逐步发生了改变。
其中,数据的重要性正提到了前所未有的高度,由此也正在带来对存储越来越严苛的要求。
在一个全新的视角下,数据与其背后的“存力”,正在成为影响大模型创新整体过程的关键因素。
大模型创新从“片面追求”走向“全局视角”,“存力”价值凸显
在某种“算力不足恐惧症”下,前几年,各个省市都在大力建设AI算力中心。
参数模型有多大、多少卡、每秒多少次运算能力……是大家的主要关心点。
中国强大的基础设施建设能力与优势,在新基建这里又继续发光发热。
这无疑对AI、大模型的发展带来了很多好处,尤其是让算力问题得到纾解。
但是,当一个“急事”快要落定后,我们的目光,就不免要落到全局层面,思考大模型创新在整体上应该如何才能做出优势?
很明显,算力,只是补了急切的短板,而大模型创新从来都必须是端到端完成,才能最终展现出场景变革的价值。
我们知道,大模型训练大体上可以分为数据归集、数据预处理(匿名、打标签等工作)、模型训练、应用推理几个流程阶段。
一个朴素的逻辑是,要想端到端效率高,一方面要保证每个阶段效率高,另一方面还要让不同阶段的接驳更顺畅。
然而,目前这两个方面都存在问题。
在“接驳”这件事上,在数据归集后,由数据预处理阶段迈入模型训练阶段,因为分离部署、存在数据烟囱,跨设备、跨中心拷贝到数据训练场景中去,训练准备耗时冗长——一个20亿数据集,拷贝都要准备整整30天。
要知道,现在大模型的发展进度几乎是按周刷新。
而这也导致模型训练阶段的效率不佳。很多企业图省事采用本地盘做存储,数据在跨算力服务器间同步时读取效率低(加载1TB数据往往需4~6小时),GPU长时间处于等待状态造成资源闲置。
这背后,除了跨设备同步,还叠加有另一重原因,即大模型训练往往存在海量的小文件读取,小文件的读写性能较差,极其耗费时间。
而训练阶段的效率问题还没完。
一旦出现故障,或者要优化算法,就需要让GPU停下来,调整好了再启动,这种往往持续数小时的百GB,甚至TB级的Checkpoint断点续训的存在,与海量数据同步一起,致使GPU资源利用率普遍不高,昂贵的投资被白白浪费。
好不容易“熬”到了应用推理阶段,要想推理效果更好,尤其是规避“大模型幻觉”等问题,还需要不断调取特定的知识数据。
在“全局视角”,大模型创新要解决的问题还很多,但从各种问题不难看出,它们都与数据及其背后的存储相关。
所谓AI全流程“全局视角”,其实可以归集到“数据”视角进行整体规划。
事实上,这本身就是数据对大模型越来越重要的一种端到端流程上体现。
当前人工智能大模型的快速发展依赖大规模、高质量的数据养料,已经是普遍的共识。

在算法都是基于公开大模型微调、走向收敛,算力主要依靠英伟达、昇腾等提供资源(意味着与企业的预算能力挂钩,企业能主动做的并不多)的情况下,数据已经成为AI大模型的差异化变量,优质数据越多,模型效果越好,数据规模和质量决定AI智能的高度。
与此同时,AI大模型迭代加速,从单模态到多模态对数据的要求并非简单的“多加一份模态的”,而是在参数规模和数据量上都进行着PB到EB的万倍增长。
可以说,“缺数据,无AI”。
更进一步看,在数据获取完成后,大部分有关数据的症结问题,最终又都可以归结到存储是否能够跟上的问题。
因为,AI数据存力是人工智能大模型的数据载体,与大模型的数据归集、预处理、训练、推理等全生命周期的流程紧密相关,存力建设对人工智能发展非常重要。
此外,在数据安全性、可靠性等方面,“存力”也发挥着直接的作用。
在全局视角下,要提升端到端的效率,“算力”跑的快,“存力”也要跟上,算力与数据存力一起系统化地构成了AI算力基础设施。
如果说“缺数据,无AI”,那么毫无疑问先进数据存力将会是构建AI差异化优势的关键。
“全局视角”下,外置高性能共享存储正在推动优势“存力”的形成
既然存力如此重要,那么企业要如何构建优势“存力”?
总结前文,只有能够解决数据归集、数据预处理、数据训练、模型推理等环节的低效问题,推动数据价值的实现,实现大模型创新端到端效率提升,才能算得上优势“存力”,而这涉及海量数据的复杂读写,必须要有高性能共享存储才能解决。
具体而言,可以得出包括存力在内的AI算力基础设施面临着三大挑战。
集群GPU利用率普遍低于50%;
数据加载时间长,小时级断点续训时间;
语料数据规模大,从单模态到Sora等多模态大模型,语料从PB级到EB级增加,EB级的数据规模扩张。
这些挑战,都导向大规模数据集群的可用度上。
换句话说,能够解决大规模数据集群的可用度的存力,就是好存力。
业界已经有一些领头羊企业行动起来了。
例如,英伟达的SuperPOD参考架构,采用了外置高性能共享存储来解决AI大模型三大挑战:
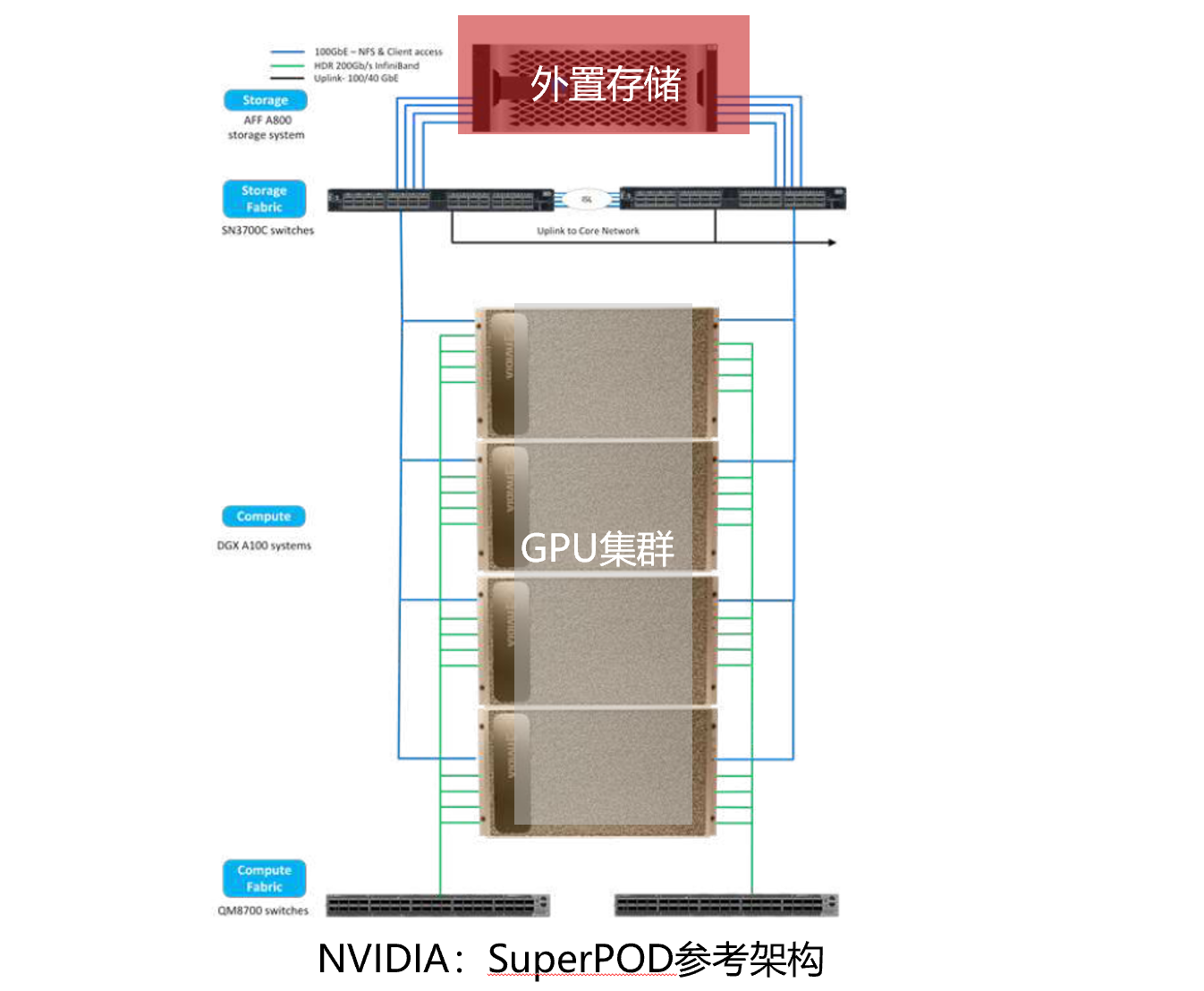
其主要背景,就是数据集越来越大,采用GDS(GPU直通存储)可以更高效地从存储中读取数据,提供更高性能和更低时延。
类似做法的不只有英伟达一家,Meta采用外置共享存储,支持了数千个 GPU以同步方式保存和加载Checkpoint,实现了灵活、高吞吐量的EB级存储。
此外,还有DDN(美国高性能计算和云存储厂商)利用外置共享存储消除在不同存储之间移动数据的开销和风险、Net APP利用高性能全闪存存储提升GPU利用率等。
三大挑战都被针对性解决,一种共识已经客观上形成——采用外置高性能共享存储,是优势“存力”的重要可行解。
而在国内,也同样有这样的产品和服务可以选择。
华为同样提供外置高性能AI存储,其AI数据湖解决方案,能够实现全局文件系统(统一数据管理、无论在何处)、上千节点EB级系统扩展、数据智能冷热分级、多协议互通等能力,从而做到提升GPU利用率、大大降低断点续训唤醒时间、满足EB级语料存储要求,最终提升大规模数据集群的可用度,一次性解决AI算力基础设施面临的三大挑战。
外置高性能共享AI存储同样得到了国内广大政企客户的认可。
目前,华为高性能共享AI存储已经在智算中心、超算中心、国家实验室、高教科研、大中型银行、运营商、企业 AI 助手等场景下应用,服务科大讯飞、建设银行、天翼云智算中心、昌平实验室、上海交大、中原银行(智能客服)等客户。

以科大讯飞为例,早期其数据中心采用“开源分布式存储软件+服务器硬件”搭建,存在读写性能不佳(十亿小文件数据量时读写性能陡降)、可靠性不够充分(故障域小、冗余保护不足)等掣肘,使得其只能将50PB 数据量需要分成多个存储集群(为了系统安全性的考虑),出现前文提到的问题——AI训练时需要频繁地将数据在存储集群间进行搬迁,GPU 利用率不足 50%。
采用华为AI数据湖方案后,科大讯飞实现了一个集群一个文件系统即可轻松应对多模态大模型时千亿~十万亿参数规模,同时基于高性能存储层+大容量存储层的自动数据分级实现了TCO 最优。
高性能,高容量,高密度,高可靠性,高安全性……在科大讯飞激烈竞逐大模型赛道时,“存力”不再成为瓶颈,而是带来了极大的助力。
这也说明,企业不能因为暂时没有AI平台的计划就不需要提前准备“存力”,需要提前规划和建设“Al Ready 的数据湖”,否则后续可能面临数据资产归集困难、架构无法平滑演进而造成重复投资建设等重大问题。
而一旦优势“存力”形成,其给企业带来的四重成本优化的价值也显现出来:
1、时间成本
在全局视角下,外置高性能共享AI存储解决大规模数据集群的可用度问题,实现端到端效率的提升,就是在以加速模型迭代的方式帮助政企抢抓大模型机遇。
2、财务成本
本地盘虽然采购时架构较为低廉,然而优质存储方案从长期可扩展性、架构平滑演进来看综合成本却更低;而且,企业提前规划建设“AI Ready ”的数据湖存力底座,也能够加速数据资产价值的激活,盘活温冷数据,从而完成数据到“数据资产”的转化。
3、情绪成本
这是针对大模型最终用户而言,更高效的大模型应用迭代,以存储内置的知识库建设帮助推理应用,流畅、丝滑、准确,都能大大提升用户的体验,减少不信任感,从而更好地实现价值转化。
4、社会责任成本
马斯克曾说,AI的尽头是电力,大模型规模更大,无论是算力还是数据存储最终都依赖大量电力供应。‘’
而华为外置高性能共享AI存储除了提升GPU利用率、保证EB级大规模数据高效访问,其业界性能最高、容量密度最大的设计,还能够直接帮助客户减少数据中心物理空间、节省功耗,与绿色低碳的时代目标共振。

总之,外置高性能共享AI存储在国内外都已经有了最佳实践,是实现优势“存力”的关键选择。在大模型洪流下,在数智化转型升级浪潮中,有需求的政企组织可以尽快行动起来了。
*本文图片均来源于网络
这篇关于大模型来了,你的“存力”攒够了吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







