本文主要是介绍接到需求,我正大光明的写了个 Bug !,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
公众号后台回复“学习”,获取作者独家秘制精品资料

多年好友心血力作,阿里资深技术专家十余年JVM生产实践经验
《从零开始带你成为JVM实战高手》
限时优惠:88元(正在进行ing)
专栏目录参见文末
扫下方海报进行试读

通过我的海报购买,再返你24元
领取方式:加微信号:Giotto1245,暗号:返现
本文来源:crossoverJie
前言
标题没有看错,真的是让我写个 bug!
刚接到这个需求时我内心没有丝毫波澜,甚至还有点激动。这可是我特长啊;终于可以光明正大的写 bug 了?。
先来看看具体是要干啥吧,其实主要就是要让一些负载很低的服务器额外消耗一些内存、CPU 等资源(至于背景就不多说了),让它的负载可以提高一些。
JVM 内存分配回顾
于是我刷刷一把梭的就把代码写好了,大概如下:
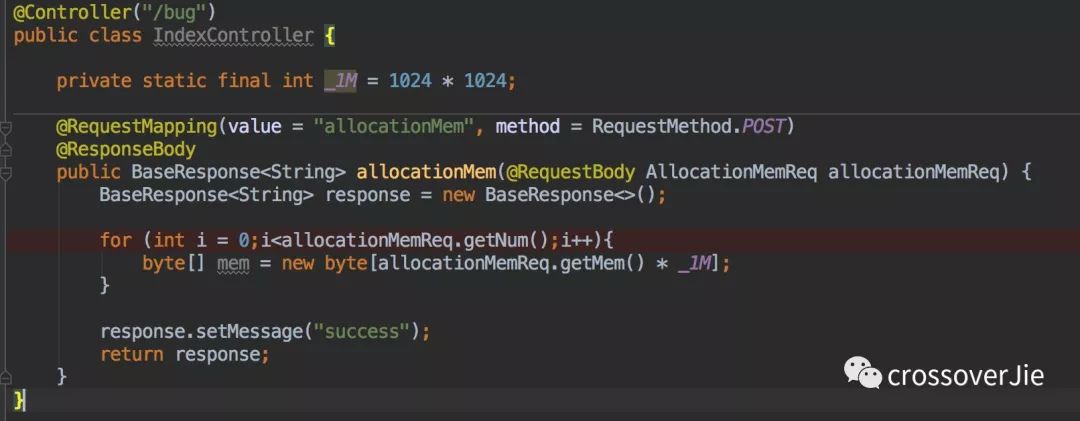
写完之后我就在想一个问题,代码中的 mem 对象在方法执行完之后会不会被立即回收呢?我想肯定会有一部分人认为就是在方法执行完之后回收。
我也正儿八经的去调研了下,问了一些朋友;果不其然确实有一部分认为是在方法执行完毕之后回收。
那事实情况如何呢?我做了一个试验。
我用以下的启动参数将刚才这个应用启动起来
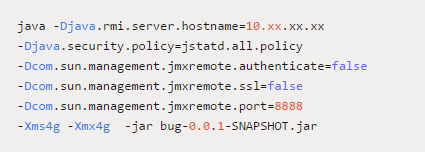
如果是方法执行完毕就回收 mem 对象,当我分配 250M 内存时;内存就会有一个明显的曲线,同时 GC 也会执行。
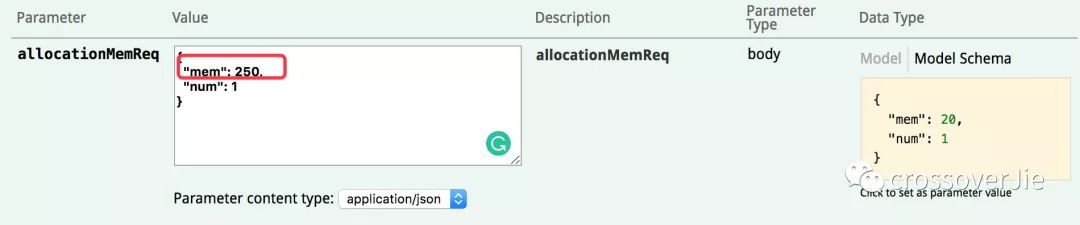
这时观察内存曲线。
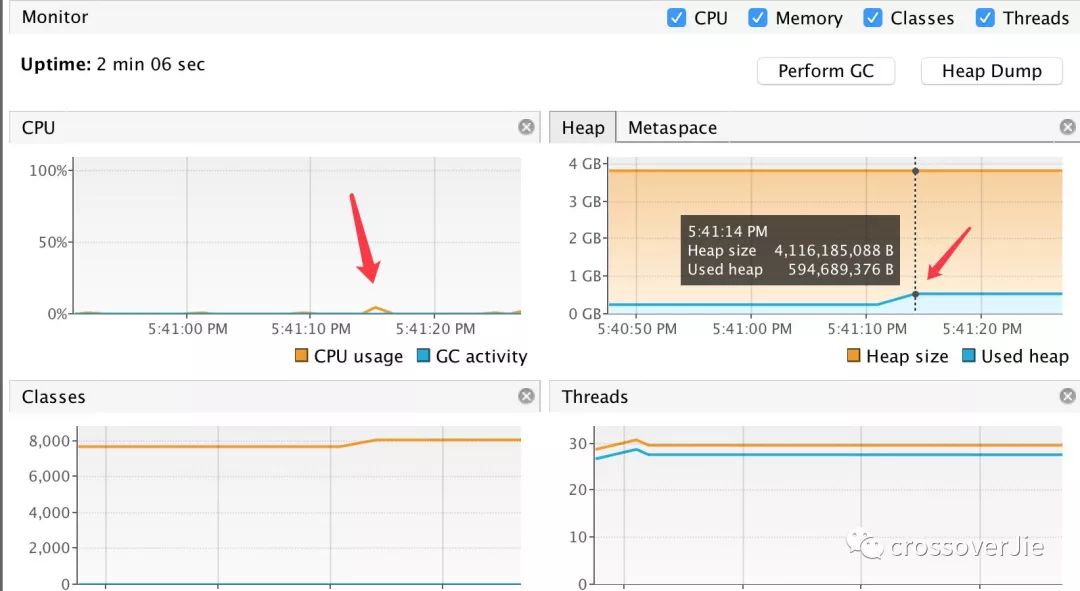
会发现确实有明显的涨幅,但是之后并没有立即回收,而是一直保持在这个水位。同时左边的 GC 也没有任何的反应。
用 jstat 查看内存布局也是同样的情况。
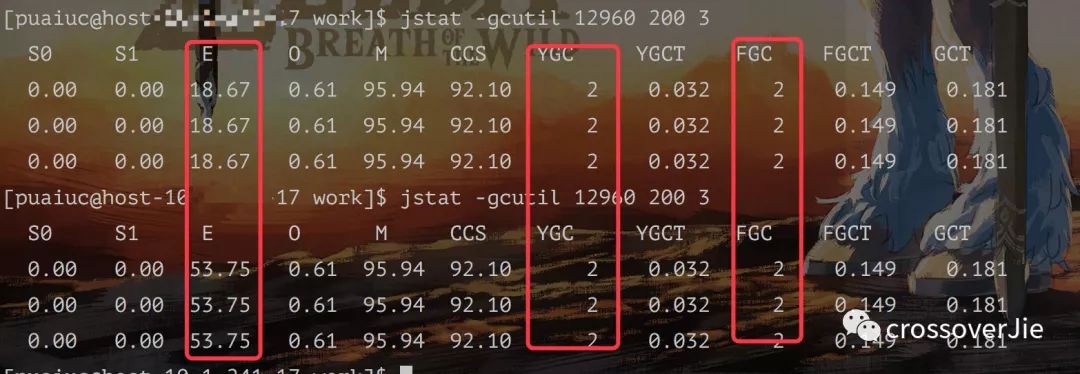
不管是 YGC,FGC 都没有,只是 Eden 区的使用占比有所增加,毕竟分配了 250M 内存嘛。
那怎样才会回收呢?
我再次分配了两个 250M 之后观察内存曲线。
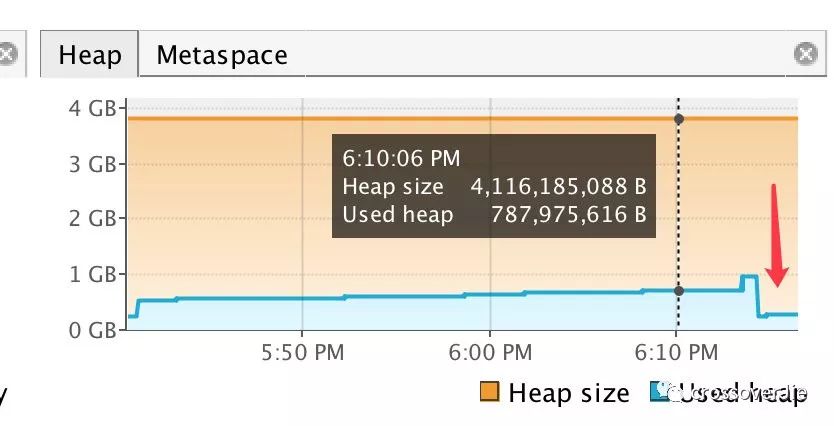
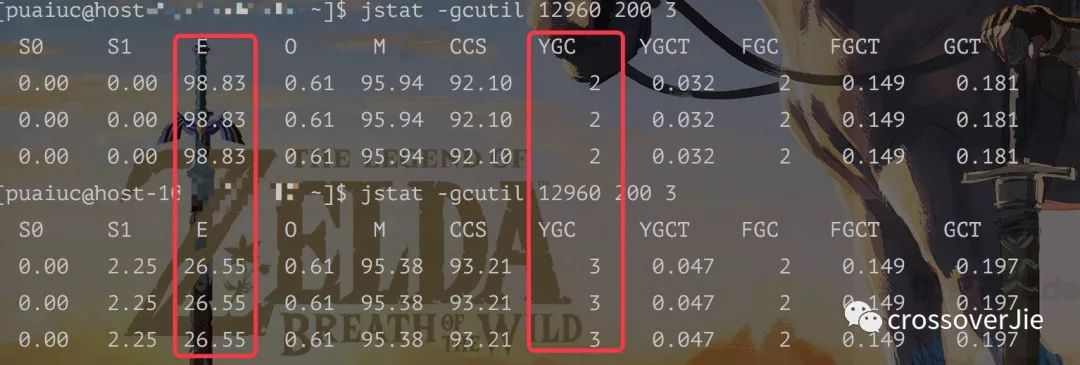
发现第三个 250M 的时候 Eden 区达到了 98.83% 于是再次分配时就需要回收 Eden 区产生了 YGC。
同时内存曲线也得到了下降。
整个的换算过程如图:

由于初始化的堆内存为 4G,所以算出来的 Eden 区大概为 1092M 内存。
加上应用启动 Spring 之类消耗的大约 20% 内存,所以分配 3 次 250M 内存就会导致 YGC。
再来回顾下刚才的问题:
mem 对象既然在方法执行完毕后不会回收,那什么时候回收呢。
其实只要记住一点即可:对象都需要垃圾回收器发生 GC 时才能回收;不管这个对象是局部变量还是全局变量。
通过刚才的实验也发现了,当 Eden 区空间不足产生 YGC 时才会回收掉我们创建的 mem 对象。
但这里其实还有一个隐藏条件:那就是这个对象是局部变量。如果该对象是全局变量那依然不能被回收。
也就是我们常说的对象不可达,这样不可达的对象在 GC 发生时就会被认为是需要回收的对象从而进行回收。
在多考虑下,为什么有些人会认为方法执行完毕后局部变量会被回收呢?
我想这应当是记混了,其实方法执行完毕后回收的是栈帧
它最直接的结果就是导致 mem 这个对象没有被引用了。但没有引用并不代表会被马上回收,也就是上面说到的需要产生 GC 才会回收。
所以使用的是上面提到的对象不可达所采用的可达性分析算法来表明哪些对象需要被回收。
当对象没有被引用后也就认为不可达了。
这里有一张动图比较清晰:
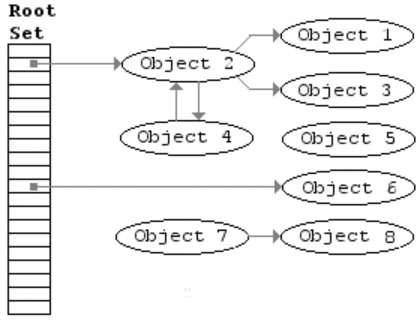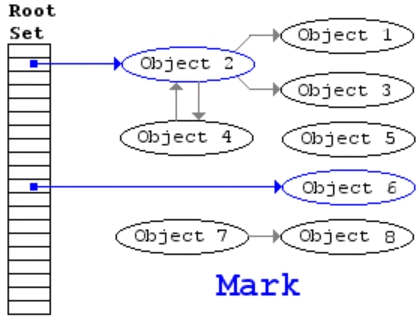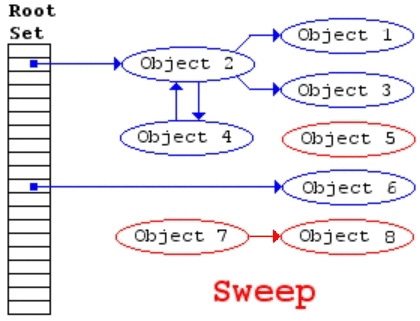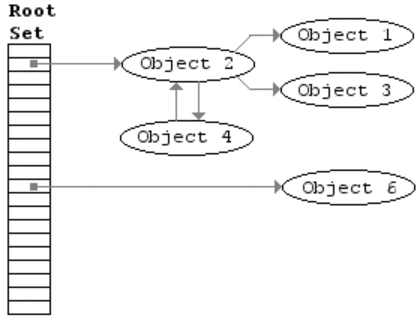
当方法执行完之后其中的 mem 对象就相当于图中的 Object5,所以在 GC 时候就会回收掉。
优先在 Eden 区分配对象
其实从上面的例子中可以看出对象是优先分配在新生代中 Eden 区的,但有个前提就是对象不能太大。
如下图:

大对象直接进入老年代
而大对象则是直接分配到老年代中(至于多大算大,可以通过参数配置)。
当我直接分配 1000M 内存时,由于 Eden 区不能直接装下,所以改为分配在老年代中。
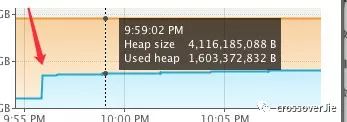
可以看到 Eden 区几乎没有变动,但是老年代却涨了 37% ,根据之前计算的老年代内存 2730M 算出来也差不多是 1000M 的内存。
Linux 内存查看
回到这次我需要完成的需求:增加服务器内存和 CPU 的消耗。
CPU 还好,本身就有一定的使用,同时每创建一个对象也会消耗一些 CPU。
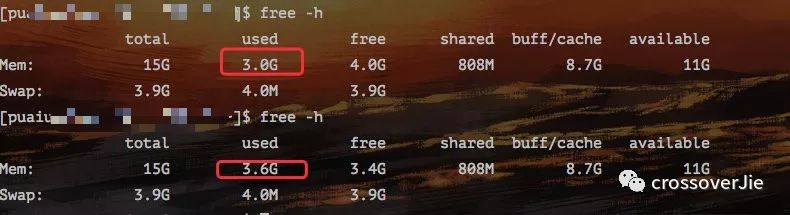
主要是内存,先来看下没启动这个应用之前的内存情况。

大概只使用了 3G 的内存。
启动应用之后大概只消耗了 600M 左右的内存。
为了满足需求我需要分配一些内存,但这里有点需要讲究。
不能一直分配内存,这样会导致 CPU 负载太高了,同时内存也会由于 GC 回收导致占用也不是特别多。
所以我需要少量的分配,让大多数对象在新生代中,为了不被回收需要保持在百分之八九十。
同时也需要分配一些大对象到老年代中,也要保持老年代的使用在百分之八九十。
这样才能最大限度的利用这 4G 的堆内存。
于是我做了以下操作:
先分配一些小对象在新生代中(800M)保持新生代在90%
接着又分配了
老年代内*(100%-已使用的28%);也就是2730*60%=1638M让老年代也在 90% 左右。
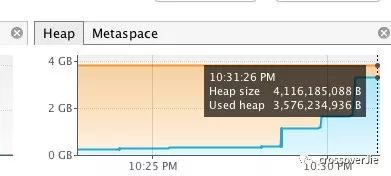
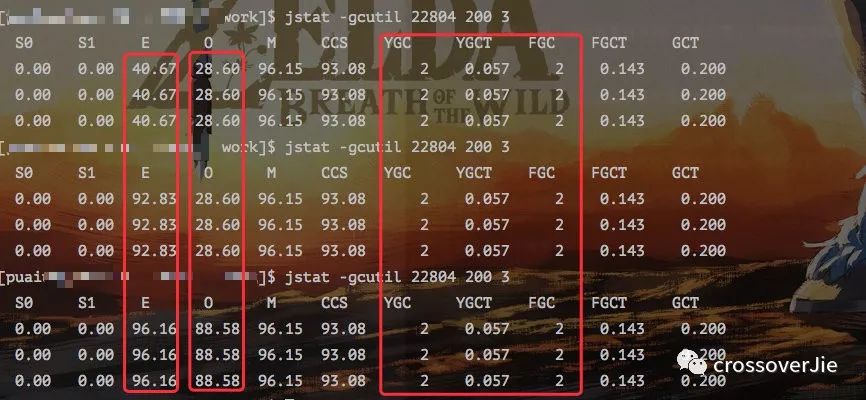
效果如上。
最主要的是一次 GC 都没有发生这样也就达到了我的目的。
最终内存消耗了 3.5G 左右。
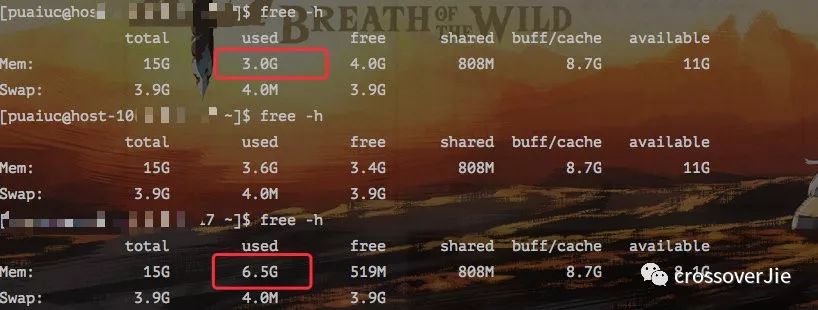
总结
虽说这次的需求是比较奇葩,但想要精确的控制 JVM 的内存分配还是没那么容易。
需要对它的内存布局,回收都要有一定的了解,写这个 Bug 的过程确实也加深了印象
END
如有收获,请划至底部,点击“在看”,谢谢!
《从零开始带你成为JVM实战高手》
专栏详细目录




欢迎长按下图关注公众号石杉的架构笔记,后台回复“学习”
获取作者独家秘制精品资料

BAT架构经验倾囊相授
这篇关于接到需求,我正大光明的写了个 Bug !的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






