本文主要是介绍Pytorch搭建全连接网络,CNN(MNIST),LeNet-5(CIFAR10),ResNet(CIFAR10), RNN,自编码器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、一个简单的全连接网络,只用到了Tensor的数据类型,没有用torch搭建模型和touch.optim的优化方法:
# coding:utf-8
import torchbatch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10x = torch.randn(batch_n, input_data)
y = torch.randn(batch_n, output_data)w1 = torch.randn(input_data, hidden_layer)
w2 = torch.randn(hidden_layer, output_data)epoch_n = 20
learning_rate = 1e-6for epoch in range(epoch_n):h1 = x.mm(w1) # 100*1000h1 = h1.clamp(min=0)y_pred = h1.mm(w2) # 100*10# print(y_pred)loss = (y_pred - y).pow(2).sum()print("Epoch:{} , Loss:{:.4f}".format(epoch, loss))gray_y_pred = 2 * (y_pred - y)gray_w2 = h1.t().mm(gray_y_pred)grad_h = gray_y_pred.clone()grad_h = grad_h.mm(w2.t())# grad_h = w2.t().mm(grad_h)grad_h.clamp_(min=0)grad_w1 = x.t().mm(grad_h)w1 -= learning_rate * grad_w1w2 -= learning_rate * gray_w2Epoch:0 , Loss:66668176.0000
Epoch:1 , Loss:197306592.0000
Epoch:2 , Loss:653368128.0000
Epoch:3 , Loss:370768256.0000
Epoch:4 , Loss:8697184.0000
Epoch:5 , Loss:6176685.5000
Epoch:6 , Loss:4637133.5000
Epoch:7 , Loss:3629787.0000
Epoch:8 , Loss:2938053.0000
Epoch:9 , Loss:2444795.0000
Epoch:10 , Loss:2082051.8750
Epoch:11 , Loss:1808700.2500
Epoch:12 , Loss:1597402.8750
Epoch:13 , Loss:1430398.7500
Epoch:14 , Loss:1295701.2500
Epoch:15 , Loss:1185050.2500
Epoch:16 , Loss:1092727.7500
Epoch:17 , Loss:1014481.0000
Epoch:18 , Loss:947148.8750
Epoch:19 , Loss:888368.1875
可以看到loss随着epoch(训练数据反复输入训练的次数)的增加在不断减小
要看懂这个网络,看下面这个笔记就好了:
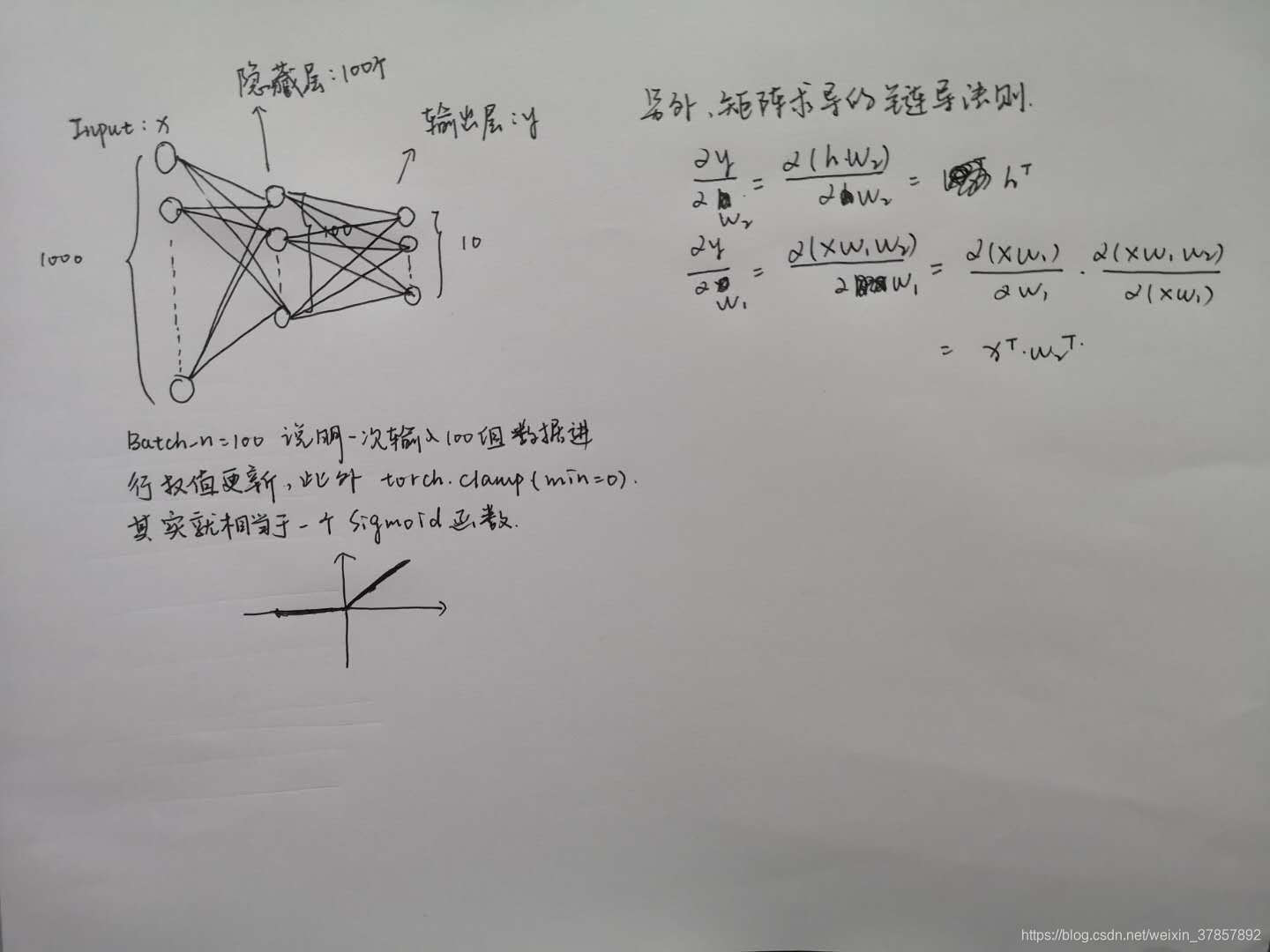
然后就是把输入输出和权值包装成Variable,就可以使用torch.autograd自动反向更新权值
import torch
from torch.autograd import Variablebatch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10x = Variable(torch.randn(batch_n,input_data),requires_grad = False)
y = Variable(torch.randn(batch_n,output_data),requires_grad = False)w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad = True)
w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad = True)epoch_n = 20
learning_rate = 1e-6for Epoch in range(epoch_n):y_pred = x.mm(w1).clamp(min=0).mm(w2)loss = (y_pred - y).pow(2).sum()print("Epoch:{},loss:{:.4f}".format(Epoch,loss))loss.backward()w1.data -= learning_rate*w1.grad.dataw2.data -= learning_rate*w2.grad.dataw1.grad.data.zero_()w2.grad.data.zero_()
需要注意的是loss.backward()会更新网络所有权值,但是此时我们任然没有搭建模型,接下来我们用torch.nn搭建一个全连接网络:
import torch
from torch.autograd import Variablebatch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10x = Variable(torch.randn(batch_n,input_data),requires_grad = False)
y = Variable(torch.randn(batch_n,output_data),requires_grad = False)models = torch.nn.Sequential(torch.nn.Linear(input_data,hidden_layer),torch.nn.ReLU(),torch.nn.Linear(hidden_layer,output_data),
)epoch_n = 10000
learning_rate = 1e-4
loss_fn = torch.nn.MSELoss()for epoch in range(epoch_n):y_pred = models(x)loss = loss_fn(y_pred,y)if epoch%1000 ==0:print("Epoch:{},loss:{:.4f}".format(epoch,loss.data))models.zero_grad()loss.backward()for param in models.parameters():param.data -= learning_rate*param.grad.data
注意到我们虽然搭建了准确模型,但是对于权值更新部分我们还是要迭代更新,显然,当网络层数加深时,这种方法过于麻烦,我们选择建立一个优化器:
import torch
from torch.autograd import Variablebatch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10x = Variable(torch.randn(batch_n,input_data),requires_grad = False)
y = Variable(torch.randn(batch_n,output_data),requires_grad = False)models = torch.nn.Sequential(torch.nn.Linear(input_data,hidden_layer),torch.nn.ReLU(),torch.nn.Linear(hidden_layer,output_data),
)epoch_n = 200
learning_rate = 1e-4
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(models.parameters(),lr=learning_rate)for epoch in range(epoch_n):y_pred = models(x)loss = loss_fn(y_pred,y)print("Epoch:{},loss:{:.4f}".format(epoch,loss.data))models.zero_grad()loss.backward()optimizer.step()
到这里,基本的torch框架已经出来了,模型,优化器,数据类型~
二、接下来我们做一个普通的卷积神经网络:
import torch
import torchvision
import numpy
import matplotlib.pyplot as plt
# torchvision包主要功能是实现数据的处理,导入和预览
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable# torchvision.datasets 可以轻松下载数据集,例如MNIST,COCO,ImageNet,CIFCAR
# 首先获取手写数字的训练集和测试集
# root 用于指定数据集在下载后的存放路径
# transform 用于指定导入数据集需要对数据进行的变换操作
# train 是指定数据集下载完成之后需要载入的那部分数据
# 如果设置为True 则说明载入的是该数据集的训练集部分
# 如果设置为False 则说明载入的是该数据集的测试集部分
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5],std=[0.5])])
data_train = datasets.MNIST(root="./data/",transform=transform,train=True,download=True)
data_test = datasets.MNIST(root="./data/",transform=transform,train=False)# 在数据下载完成后并且载入后,我们还需要对数据进行装载。
# 我们可以将数据的载入理解为对图片的处理,在处理完成后,
# 我们就需要将这些图片打包好送给我们的模型进行训练了,
# 而装载就是这个打包的过程。在装载时通过batch_size的值来确认每个包的大小,
# 通过shuffle的值来确认是否在装载的过程中打乱图片的顺序。装载的代码如下# 数据预览和数据装载
# 下面对数据进行装载,我们可以将数据的载入理解为对图片的处理,
# 在处理完成后,我们就需要将这些图片打包好送给我们的模型进行训练了 而装载就是这个打包的过程
# dataset 参数用于指定我们载入的数据集名称
# batch_size参数设置了每个包中的图片数据个数
# 在装载的过程会将数据随机打乱顺序并进打包data_loader_train = torch.utils.data.DataLoader(dataset=data_train,batch_size=64,shuffle=True)
print(data_loader_train)data_loader_test = torch.utils.data.DataLoader(dataset=data_test,batch_size=64,shuffle=True)
# 装载完成后,我们可以选取其中一个批次的数据进行预览#images, labels = next(iter(data_loader_train))
#img = torchvision.utils.make_grid(images)#img = img.numpy().transpose(1,2,0)
#std = [0.5]
#mean = [0.5]
#img = img*std+mean
#print([labels[i] for i in range(64)])
#plt.imshow(img)
#plt.show()class Model(torch.nn.Module):def __init__(self):super(Model,self).__init__()self.conv1=torch.nn.Sequential(torch.nn.Conv2d(1,25,kernel_size=3,stride=1,padding=1),torch.nn.BatchNorm2d(25),torch.nn.ReLU(),torch.nn.MaxPool2d(stride=2,kernel_size=2),torch.nn.Conv2d(25,50,kernel_size=3,stride=1,padding=1),torch.nn.BatchNorm2d(50),torch.nn.ReLU(),torch.nn.MaxPool2d(stride=2,kernel_size=2))self.dense=torch.nn.Sequential(torch.nn.Linear(7*7*50,1024),torch.nn.ReLU(),torch.nn.Linear(1024,128),torch.nn.ReLU(),torch.nn.Linear(128,10))def forward(self,x):out = self.conv1(x)out = out.view(-1,7*7*50)out = self.dense(out)return outmodel = Model()
print(model)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())epoch_n = 5
for epoch in range(epoch_n):training_loss = 0.0training_accuracy = 0testing_accuracy = 0batch = 0for data in data_loader_train:x_train, y_train =datax_train, y_train = Variable(x_train),Variable(y_train)outputs = model(x_train)_,pred = torch.max(outputs.data,1)optimizer.zero_grad()loss = cost(outputs, y_train)loss.backward()optimizer.step()training_loss +=losstraining_accuracy += (pred==y_train.data).sum().item()batch += 1print("{} batches have been input!".format(batch))for data in data_loader_test:x_test, y_test = datax_test, y_test = Variable(x_test), Variable(y_test)outputs = model(x_test)_,pred = torch.max(outputs.data,1)testing_accuracy += (pred == y_test.data).sum().item()#print("Loss:{:.4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}".format(running_loss/len(data_train),#100*running_correct/len(data_train),100*testing_correct/len(data_test)))print("Epoch:{}/{}:".format(epoch,epoch_n))print("-"*20)print("Loss:{:.4f},Train Accuracy:{:.4f}%,Test Accuracy:{:.4f}%".format(training_loss/len(data_train),training_accuracy/len(data_train),testing_accuracy/len(data_test)))print("-"*20)
下面这张图片对模型进行一下解释:
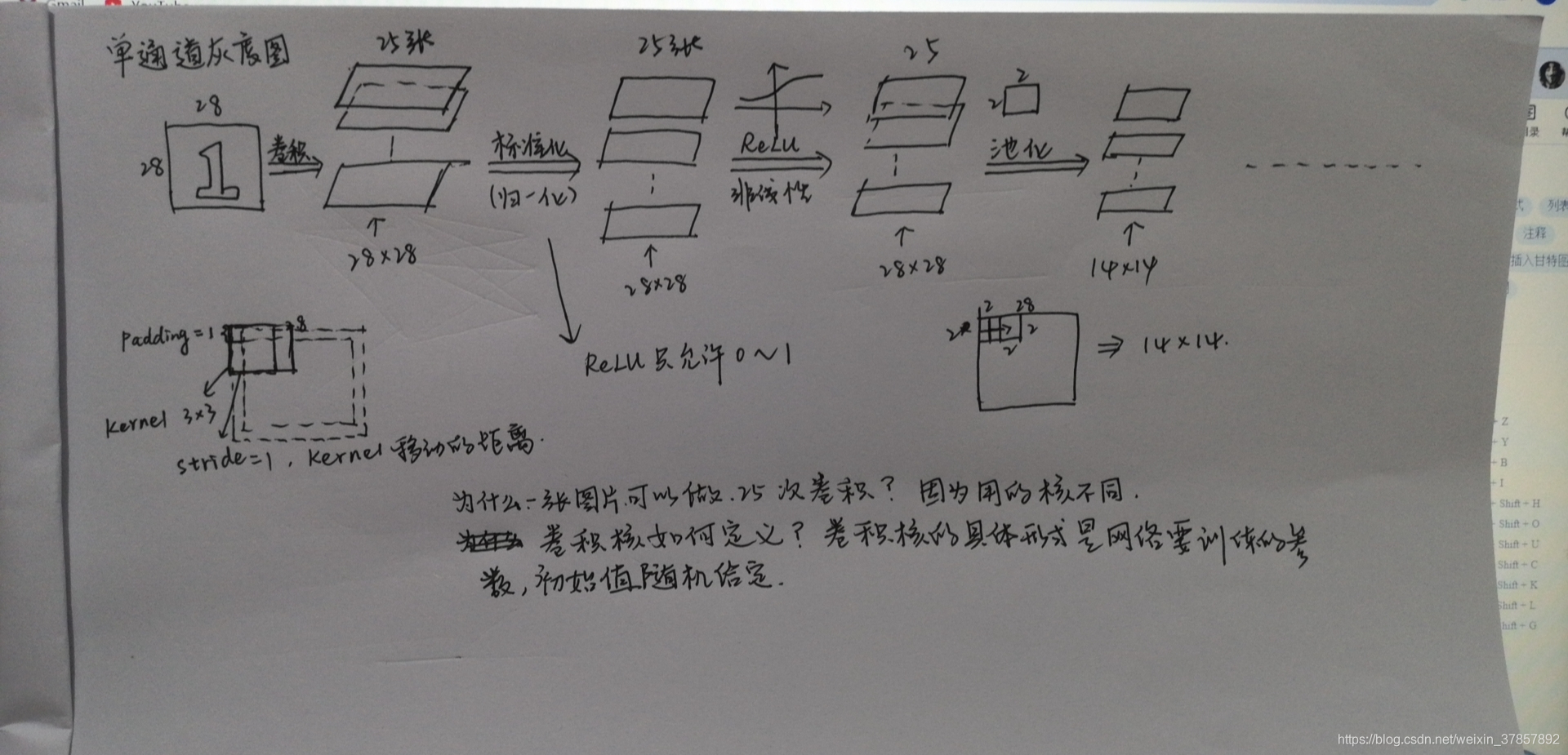
看下结果:
Epoch:0/5:
--------------------
Loss:0.0019,Train Accuracy:0.9624%,Test Accuracy:0.9763%
--------------------
Epoch:1/5:
--------------------
Loss:0.0008,Train Accuracy:0.9843%,Test Accuracy:0.9897%
--------------------
Epoch:2/5:
--------------------
Loss:0.0005,Train Accuracy:0.9898%,Test Accuracy:0.9850%
--------------------
Epoch:3/5:
--------------------
Loss:0.0004,Train Accuracy:0.9912%,Test Accuracy:0.9901%
--------------------
Epoch:4/5:
--------------------
Loss:0.0003,Train Accuracy:0.9933%,Test Accuracy:0.9863%
--------------------
可以看到训练了4个Epoch之后,准确度最高达到99.01%,这个时候应该根据任务复杂程度和网络复杂程度以及泛化精度选择合适的Epoch
因为训练时间有20多分钟,所以改成了GPU版本扔到了AI MAX上训练:
import torch
import torchvision
import numpy
import matplotlib.pyplot as plt
# torchvision包主要功能是实现数据的处理,导入和预览
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable# torchvision.datasets 可以轻松下载数据集,例如MNIST,COCO,ImageNet,CIFCAR
# 首先获取手写数字的训练集和测试集
# root 用于指定数据集在下载后的存放路径
# transform 用于指定导入数据集需要对数据进行的变换操作
# train 是指定数据集下载完成之后需要载入的那部分数据
# 如果设置为True 则说明载入的是该数据集的训练集部分
# 如果设置为False 则说明载入的是该数据集的测试集部分
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5],std=[0.5])])
data_train = datasets.MNIST(root="./data/",transform=transform,train=True,download=True)
data_test = datasets.MNIST(root="./data/",transform=transform,train=False)# 在数据下载完成后并且载入后,我们还需要对数据进行装载。
# 我们可以将数据的载入理解为对图片的处理,在处理完成后,
# 我们就需要将这些图片打包好送给我们的模型进行训练了,
# 而装载就是这个打包的过程。在装载时通过batch_size的值来确认每个包的大小,
# 通过shuffle的值来确认是否在装载的过程中打乱图片的顺序。装载的代码如下# 数据预览和数据装载
# 下面对数据进行装载,我们可以将数据的载入理解为对图片的处理,
# 在处理完成后,我们就需要将这些图片打包好送给我们的模型进行训练了 而装载就是这个打包的过程
# dataset 参数用于指定我们载入的数据集名称
# batch_size参数设置了每个包中的图片数据个数
# 在装载的过程会将数据随机打乱顺序并进打包data_loader_train = torch.utils.data.DataLoader(dataset=data_train,batch_size=64,shuffle=True)
print(data_loader_train)data_loader_test = torch.utils.data.DataLoader(dataset=data_test,batch_size=64,shuffle=True)
# 装载完成后,我们可以选取其中一个批次的数据进行预览#images, labels = next(iter(data_loader_train))
#img = torchvision.utils.make_grid(images)#img = img.numpy().transpose(1,2,0)
#std = [0.5]
#mean = [0.5]
#img = img*std+mean
#print([labels[i] for i in range(64)])
#plt.imshow(img)
#plt.show()class Model(torch.nn.Module):def __init__(self):super(Model,self).__init__()self.conv1=torch.nn.Sequential(torch.nn.Conv2d(1,25,kernel_size=3,stride=1,padding=1),torch.nn.BatchNorm2d(25),torch.nn.ReLU(),torch.nn.MaxPool2d(stride=2,kernel_size=2),torch.nn.Conv2d(25,50,kernel_size=3,stride=1,padding=1),torch.nn.BatchNorm2d(50),torch.nn.ReLU(),torch.nn.MaxPool2d(stride=2,kernel_size=2))self.dense=torch.nn.Sequential(torch.nn.Linear(7*7*50,1024),torch.nn.ReLU(),torch.nn.Linear(1024,128),torch.nn.ReLU(),torch.nn.Linear(128,10))def forward(self,x):out = self.conv1(x)out = out.view(-1,7*7*50)out = self.dense(out)return outmodel = Model()
model = model.cuda()
print(model)
cost = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters())epoch_n = 5
for epoch in range(epoch_n):training_loss = 0.0training_accuracy = 0testing_accuracy = 0batch = 0for data in data_loader_train:x_train, y_train =datax_train, y_train = x_train.cuda(), y_train.cuda()#x_train, y_train = Variable(x_train),Variable(y_train)outputs = model(x_train)_,pred = torch.max(outputs.data,1)optimizer.zero_grad()loss = cost(outputs, y_train)loss.backward()optimizer.step()training_loss +=losstraining_accuracy += (pred==y_train.data).sum().item()batch += 1print("{} batches have been input!".format(batch))for data in data_loader_test:x_test, y_test = datax_test, y_test = x_test.cuda(), y_test.cuda()outputs = model(x_test)_,pred = torch.max(outputs.data,1)testing_accuracy += (pred == y_test.data).sum().item()#print("Loss:{:.4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}".format(running_loss/len(data_train),#100*running_correct/len(data_train),100*testing_correct/len(data_test)))print("Epoch:{}/{}:".format(epoch,epoch_n))print("-"*20)print("Loss:{:.4f},Train Accuracy:{:.4f}%,Test Accuracy:{:.4f}%".format(training_loss/len(data_train),training_accuracy/len(data_train),testing_accuracy/len(data_test)))print("-"*20)
把模型和输入输出用cuda包装就好了
比较一下运行时间:


CPU:12min多一点 GPU:1min多一点,深度学习拼的是硬件。。。。。
三、 接着,尝试搭建LeNet-5,用来对CIFAR10数据集进行分类:
CIFAR10数据集百度云链接:
CIFAR10 提取码:511f
LeNet-5 网络结构:
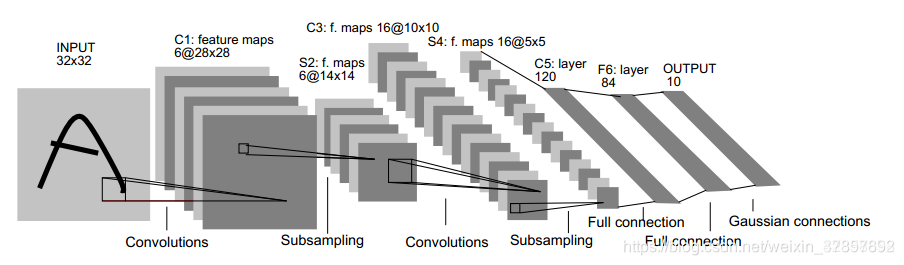
首先我们用一个文件(LeNet_5.py)实现该类:
import torch
from torch import nnclass Flatten(nn.Module):def __init__(self):super(Flatten,self).__init__()def forward(self,input):return input.view(input.size(0),-1)class LeNet(nn.Module):def __init__(self):super(LeNet,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,6,kernel_size=5,stride=1,padding=0),nn.BatchNorm2d(6),nn.ReLU(inplace=True),nn.MaxPool2d(2,stride=2),nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0),nn.BatchNorm2d(16),nn.ReLU(inplace=True),nn.MaxPool2d(2,stride=2),Flatten(),nn.Linear(16*5*5,120),nn.ReLU(inplace=True),nn.Linear(120,84),nn.ReLU(inplace=True),nn.Linear(84,10))def forward(self,x):return self.model(x)# net = LeNet()
# def main():
# net = LeNet()
# tmp = torch.randn(2,3,32,32)
# out = net(tmp)
# print("LeNet Out:{}".format(out.shape))# if __name__=="__main__":
# main()
除了kernel_size可能与原文不同,其他按照原文结构,Flatten类表示把tensor打扁成一维序列
主函数:
import torch
import torchvision
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import LeNet_5
batch_size = 500
# cpu训练的话把batch_size改成100,cpu达不到训练一个500的batch的速度
def main():cifar_train = DataLoader(datasets.CIFAR10('cifar',train=True,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)cifar_test = DataLoader(datasets.CIFAR10('cifar',train=False,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)x,label = next(iter(cifar_train))print(x.shape,label.shape)device = torch.device('cuda')# 如果使用 CPU ,把cuda改成cpumodel = LeNet_5.LeNet().to(device)criterion = torch.nn.CrossEntropyLoss().to(device)optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)print(model)for epoch in range(50):# model.train()total_loss = 0for batch_idx,(x,label) in enumerate(cifar_train):x,label = x.to(device),label.to(device)logits = model(x)loss = criterion(logits,label)total_loss += lossmodel.zero_grad()loss.backward()optimizer.step()print("epoch:{},loss:{:.4f}".format(epoch,total_loss.item()))# model.eval()total_correct = 0total = 0for x,label in cifar_test:x,label = x.to(device),label.to(device)logits = model(x)pred = logits.argmax(dim=1)total_correct += torch.eq(pred,label).float().sum().item()total += x.size(0)print("epoch:{},acc:{:.4f}".format(epoch,total_correct/total))if __name__=='__main__':main()
第一次训练了50个epoch,发现accuracy。。。63.8%
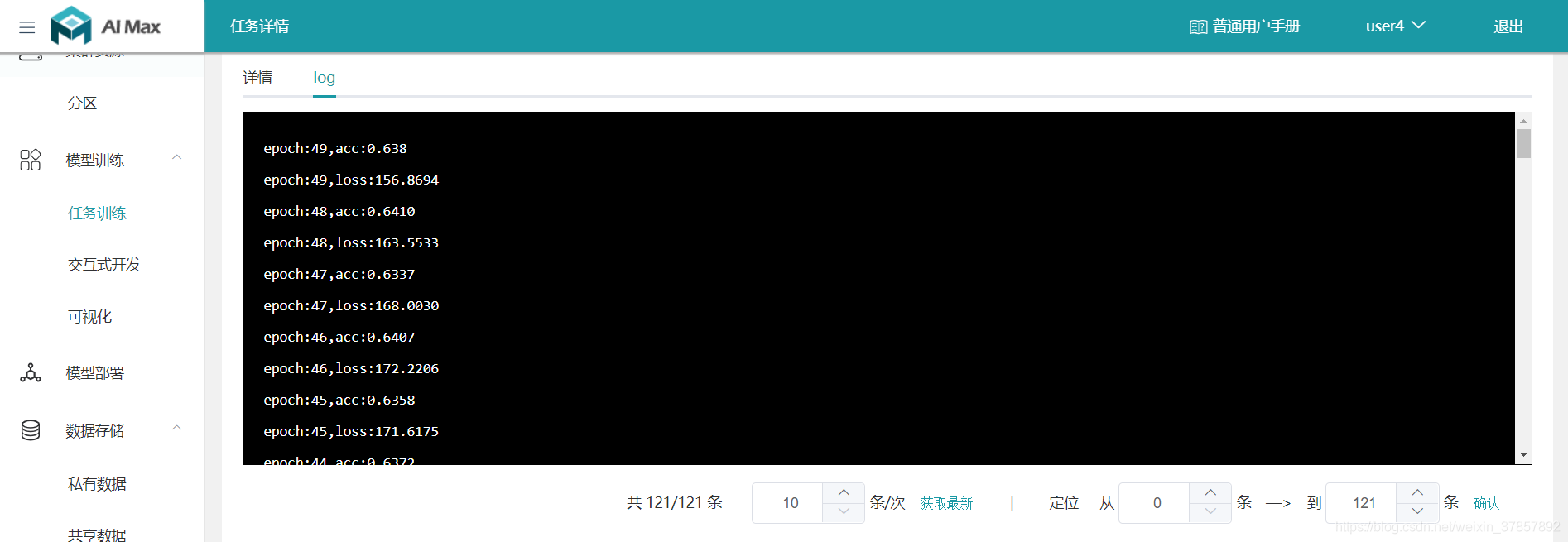
于是默默把epoch改成了200.。。。。结果。。。61.2%
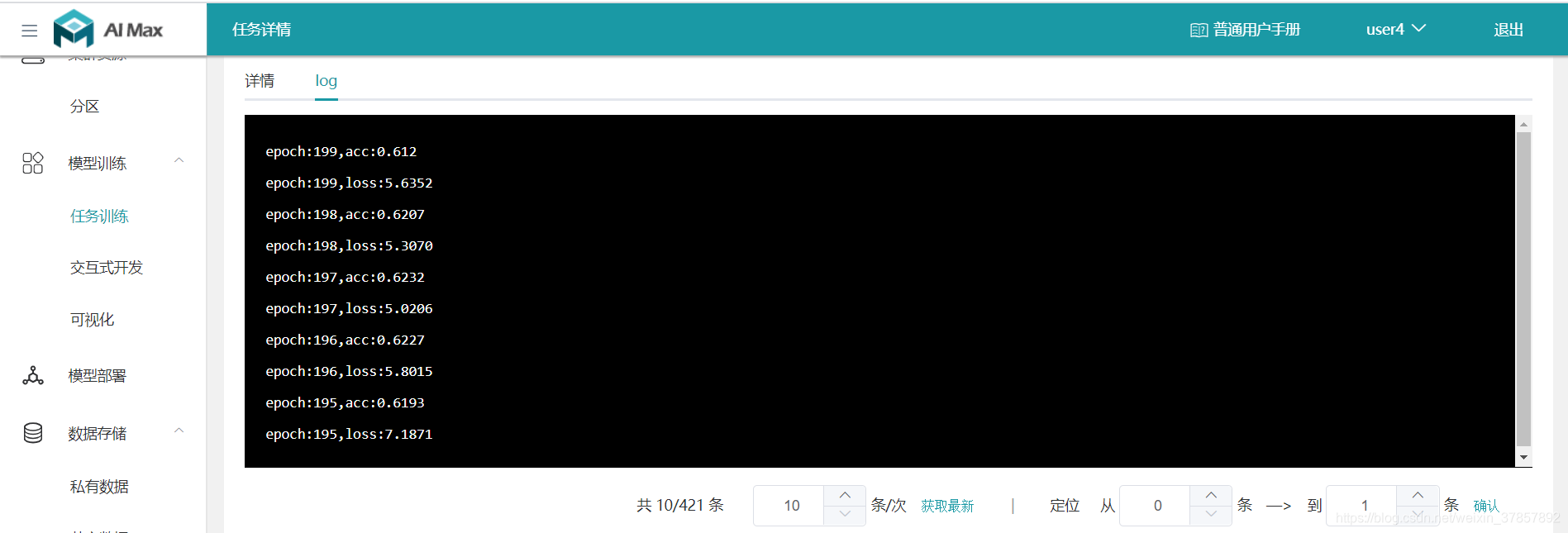
最后发现30个epoch左右准确度已经达到了最高:

准确率大概在66.9%,所以这说明我们的Model-LeNet-5对CIFAR10数据集的分类准确率最多就是70左右
四、使用ResNet对CIFAR10数据集进行分类
模型类函数(ResNet.py):
import torch
from torch import nn
from torch.nn import functional as Fclass Flatten(nn.Module):def __init__(self):super(Flatten,self).__init__()def forward(self,x):return x.view(x.size(0),-1)class BasicBlk(nn.Module):def __init__(self,ch_in,ch_out):super(BasicBlk,self).__init__()self.basic_conv = nn.Sequential(nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(ch_out),nn.ReLU(inplace=True),nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(ch_out),)self.extra_link = nn.Sequential()if ch_in != ch_out:self.extra_link = nn.Sequential(nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=1,padding=0),)def forward(self,x):out = F.relu(self.basic_conv(x) + self.extra_link(x))return outclass ResNet18(nn.Module):def __init__(self):super(ResNet18,self).__init__()self.core = nn.Sequential(nn.Conv2d(3,16,kernel_size=3,stride=1,padding=1),nn.AvgPool2d(kernel_size=2,stride=2),BasicBlk(16,64),BasicBlk(64,128),BasicBlk(128,256),BasicBlk(256,512),nn.AvgPool2d(kernel_size=2,stride=2),Flatten(),nn.Linear(32768,1000),nn.ReLU(inplace=True),nn.Linear(1000,10)) def forward(self, x):return self.core(x)def main():tmp = torch.randn(2,3,32,32) model_blk = BasicBlk(3,10) model = ResNet18()out_blk = model_blk(tmp)out = model(tmp)print(out)if __name__=='__main__':main()
程序入口函数:
import torch
import torchvision
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
# import LeNet_5
import ResNet
batch_size = 500
def main():cifar_train = DataLoader(datasets.CIFAR10('cifar',train=True,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)cifar_test = DataLoader(datasets.CIFAR10('cifar',train=False,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)x,label = next(iter(cifar_train))print(x.shape,label.shape)device = torch.device('cuda')model = ResNet.ResNet18().to(device)criterion = torch.nn.CrossEntropyLoss().to(device)optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)print(model)for epoch in range(240):# model.train()total_loss = 0for batch_idx,(x,label) in enumerate(cifar_train):x,label = x.to(device),label.to(device)logits = model(x)loss = criterion(logits,label)total_loss += lossmodel.zero_grad()loss.backward()optimizer.step()print("epoch:{},loss:{:.4f}".format(epoch,total_loss.item()))# model.eval()total_correct = 0total = 0for x,label in cifar_test:x,label = x.to(device),label.to(device)logits = model(x)pred = logits.argmax(dim=1)total_correct += torch.eq(pred,label).float().sum().item()total += x.size(0)print("epoch:{},acc:{:.4f}".format(epoch,total_correct/total))if __name__=='__main__':main()
训练了240个epoch之后感觉陷入了局部极小值:

看了下历史accuracy,最高达到80%,显然并不理想,下面尝试改进
import torch
from torch import nn
from torch.nn import functional as Fclass Flatten(nn.Module):def __init__(self):super(Flatten,self).__init__()def forward(self,x):return x.view(x.size(0),-1)class BasicBlk(nn.Module):def __init__(self,ch_in,ch_out,stride=1):super(BasicBlk,self).__init__()self.basic_conv = nn.Sequential(nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride,padding=1),nn.BatchNorm2d(ch_out),nn.ReLU(inplace=True),nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(ch_out),)self.extra_link = nn.Sequential()if ch_in != ch_out or stride!=1:self.extra_link = nn.Sequential(nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),nn.BatchNorm2d(ch_out))def forward(self,x):out = F.relu(self.basic_conv(x) + self.extra_link(x))return outclass ResNet(nn.Module):def __init__(self,BasicBlk):super(ResNet,self).__init__()self.core = nn.Sequential(nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),BasicBlk(64,64,1),BasicBlk(64,128,2),BasicBlk(128,256,2),BasicBlk(256,512,2),nn.AvgPool2d(kernel_size=4),Flatten(),nn.Linear(512,10),) def forward(self, x):return self.core(x)def ResNet18():return ResNet(BasicBlk)if __name__=='__main__':ResNet18() import torch
import torchvision
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
# import LeNet_5
from ResNet import ResNet18
batch_size = 128
def main():cifar_train = DataLoader(datasets.CIFAR10('cifar',train=True,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.RandomHorizontalFlip(),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)cifar_test = DataLoader(datasets.CIFAR10('cifar',train=False,download=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])),batch_size=batch_size,shuffle=True)x,label = next(iter(cifar_train))print(x.shape,label.shape)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = ResNet18().to(device)criterion = torch.nn.CrossEntropyLoss().to(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)print(model)switch_second = Falseswitch_third = Falsefor epoch in range(240):# model.train()if epoch>130 and epoch < 180 and switch_second==False:optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)switch_second = Trueif epoch>=180 and switch_third==False:optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4)switch_third = Truetotal_loss = 0for batch_idx,(x,label) in enumerate(cifar_train):x,label = x.to(device),label.to(device)logits = model(x)loss = criterion(logits,label)total_loss += lossmodel.zero_grad()loss.backward()optimizer.step()print("epoch:{},loss:{:.4f}".format(epoch,total_loss.item()))# model.eval()total_correct = 0total = 0for x,label in cifar_test:x,label = x.to(device),label.to(device)logits = model(x)pred = logits.argmax(dim=1)total_correct += torch.eq(pred,label).float().sum().item()total += x.size(0)print("epoch:{},acc:{:.4f}".format(epoch,total_correct/total))if __name__=='__main__':main()
训练了240个epoch之后达到了90%,结果还不错

这篇关于Pytorch搭建全连接网络,CNN(MNIST),LeNet-5(CIFAR10),ResNet(CIFAR10), RNN,自编码器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






