本文主要是介绍Nebula Graph-01-Nebula Graph简介和安装以及客户端连接,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
NoSQL 数据库
图数据库并不是可以克服关系型数据库缺点的唯一替代方案。现在市面上还有很多非关系型数据库的产品,这些产品都可以叫做 NoSQL。NoSQL 一词最早于上世纪 90 年代末提出,可以解释为“非 SQL” 或“不仅是 SQL”,具体解释要根据语境判断。为便于理解,这里 NoSQL 可以解释成 “非关系型数据库”。不同于关系型数据库,NoSQL 数据库提供的数据存储、检索机制并不是基于表关系建模的。 NoSQL 数据库可以分为四类:
- 键值存储(key-value stores)
- 列式存储(column-family stores)
- 文件存储(document stores)
- 图数据库(graph databases)
下面将分别介绍这四类数据库。
-
键值存储
键值存储,顾名思义,就是使用键值对存储数据的数据库。不同于关系型数据库,键值存储是没有表和列的。如果一定要做类比,键值数据库本身就像一张有很多列(也就是键)的大表。在键值存储数据库中,数据(即键值对中的值)都是通过键来存储和查询的,通常用哈希列表来实现。这比传统的 SQL 数据库要简单得多,而且对于某些 web 应用来说,这就足够了。键值模型对于 IT 系统来说优势在于简单、易部署。多数情况下,这种存储方式对非关联的数据很适用。如是只是存储数据而无需查询的话,使用这种存储方法就没有问题。但是如果 DBA 只对部分值进行查询或更新的时候,键值模型就显得效率低下了。常见的键值存储数据库有:Redis、Voldemort、Oracle BDB。
-
列式存储
NoSQL 数据库的列式存储与 NoSQL 数据库的键值存储有许多相似之处,因为列式存储仍然在使用键进行存储和检索。区别在于列式存储数据库中,列是最小的存储单元,每一列均由键、值以及用于版本控制和冲突解决的时间戳组成。这在分布式扩展时特别有用,因为在数据库更新时,可以使用时间戳定位过期数据。由于列式存储良好的扩展性,因此适用于非常大的数据集。常见的列式存储数据库有:HBase、Cassandra、HadoopDB 等。 -
文档存储
准确来说,NoSQL 数据库文档存储实际上也是基于键值的数据库,只不过对功能做了增强。数据仍然以键值的形式存储,但是文档存储中的值是结构化的文档,而不仅仅是一个字符串或单个值。也就是说,由于信息结构的增加,文档存储能够执行更优化的查询,并且使数据检索更加容易。因此,文档存储特别适合存储、索引并管理面向文档的数据或者类似的半结构化数据。从技术上讲,作为一个半结构化的信息单元,文档存储中的文档可以是任何形式可用的文档,包括 XML、JOSN、YAML 等,这取决于数据库供应商的设计。 比如,JSON 就是一种常见的选择。虽然 JSON 不是结构化数据的最佳选择,但是 JSON 型的数据在前端和后端应用中都可以使用。常见的文档存储数据库有:MongoDB、CouchDB、Terrastore 等。
-
图存储
最后一类 NoSQL 数据库是图数据库。本书重点讨论的 NebulaGraph 也是一种图数据库。虽然同为 NoSQL 型数据库,但是图数据库与上述 NoSQL 数据库有本质上的差异。图数据库以点、边、属性的形式存储数据。其优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。我们将在随后的章节中详细讨论图数据库。不过在本章中,你只要知道图数据库是一种 NoSQL 类型的数据库就可以了。常见的图数据库有:NebulaGraph、Neo4j、OrientDB 等。
为什么要有图数据库
虽然关系型数据库(MySQL)与 XML/JSON 等半结构类型的数据库,都可以用来描述图结构的数据模型。
但是,图(数据库)不仅可以描述图结构与存储数据本身,更着眼于处理数据之间的关联(拓扑)关系。具体来说,图(数据库)有这么几个优点:
- 图是一种更直观、更符合人脑思考直觉的知识表示方式。这使得我们在抽象业务问题时,可以着眼于“业务问题本身”,而不是“如何将问题描述为数据库的某种特定结构(例如表格结构)”。
- 图更容易展现数据的特征,例如转账的路径、近邻的社区。
- 图查询语言是针对图结构访问设计的,可以更加直观。
- 由于存储引擎和查询引擎可以针对图的结构专门设计,图的遍历(对应 SQL 中的 join)要高效得多。
- 图数据库具有广泛的适用场景。例如数据集成(知识图谱)、个性化推荐、欺诈与威胁检测、风险分析与合规、身份(与控制权)验证、IT 基础设施管理、供应链与物流、社交网络研究等。
- 根据文献的统计,使用图技术最多的领域,依次是:信息技术(IT)、学术界研究、金融、工业界实验室、政府、医疗健康、国防、制药业、零售与电子商务、交通运输、电信、保险。
图数据库是基于图论实现的一种NoSQL数据库,其数据存储结构和数据查询方式都是以图论为基础的,
图数据库主要用于存储更多的连接数据.
图论〔Graph Theory〕是数学的一个分支。它以图为研究对象图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
分析市面上主流图数据库
https://blog.csdn.net/Castlehe/article/details/121602870
Nebula Graph 介绍
1:Nebula Graph 简介
官网:https://docs.nebula-graph.com.cn/3.6.0/
NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
NebulaGraph 的优势
- 开源
- 高性能
- 易扩展
- 易开发
- 高可靠访问控制
- 生态多样化
- 兼容 openCypher 查询语言
- 面向未来硬件,读写平衡
- 灵活数据建模
- 广受欢迎(我觉得就是因为开源-免费的)
适用场景
- 欺诈检测
- 实时推荐
- 知识图谱
- 社交网络
2:Nebula Graph 数据类型
NebulaGraph 数据模型使用 6 种基本的数据模型:
图空间(Space)
图空间用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
点(Vertex)
点用来保存实体对象,特点如下:
- 点是用点标识符(VID)标识的。VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)。
- 点可以有 0 到多个 Tag。(ebulaGraph 2.x 及以下版本中的点必须包含至少一个 Tag。)
边(Edge)
边是用来连接点的,表示两个点之间的关系或行为,特点如下:
- 两点之间可以有多条边。
- 边是有方向的,不存在无向边。
- 四元组 <起点 VID、Edge type、边排序值 (rank)、终点 VID> 用于唯一标识一条边。边没有 EID。
- 一条边有且仅有一个 Edge type。
- 一条边有且仅有一个 Rank,类型为 int64,默认值为 0。Rank 可以用来区分 Edge type、起始点、目的点都相同的边。该值完全由用户自己指定。
标签(Tag)
Tag 由一组事先预定义的属性构成。
边类型(Edge type)
Edge type 由一组事先预定义的属性构成。
属性(Property)
属性是指以键值对(Key-value pair)形式表示的信息。
3:路径
图论中一个非常重要的概念是路径,路径是指一个有限或无限的边序列,这些边连接着一系列的点。
既连接图论中点和边的任意连接方式
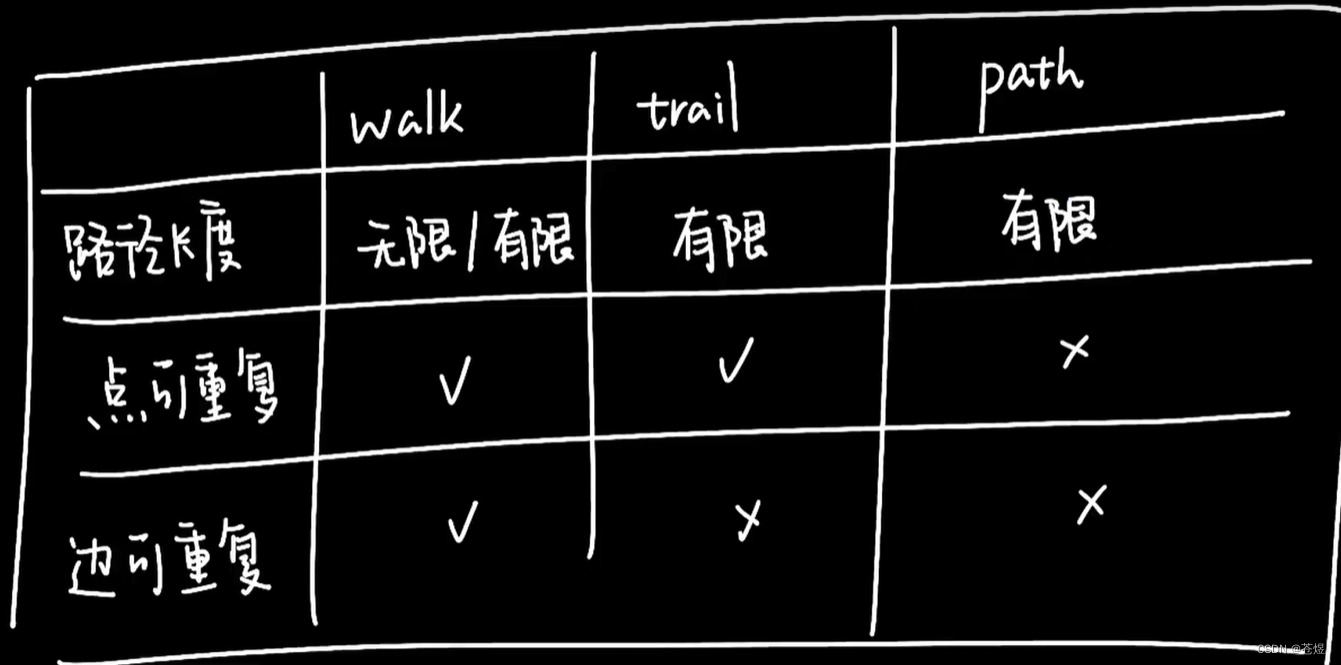
路径的类型分为三种:walk、trail、path
walk
walk类型的路径由有限或无限的边序列构成。遍历时点和边可以重复。
trail
trail类型的路径由有限的边序列构成。遍历时只有点可以重复,边不可以重复。
在 trail 类型中,还有cycle和circuit两种特殊的路径类型,以下图为例对这两种特殊的路径类型进行介绍。
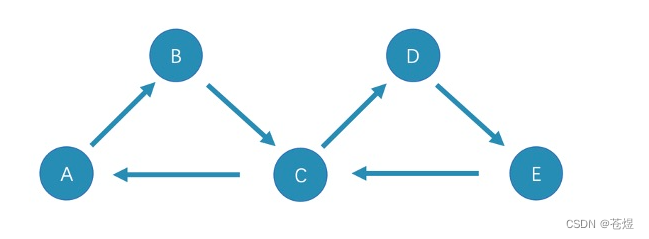
- cycle
cycle 是封闭的 trail 类型的路径,遍历时边不可以重复,起点和终点重复,并且没有其他点重复。在此示例图中,最长路径由三条边组成:A->B->C->A或C->D->E->C - circuit
circuit 也是封闭的 trail 类型的路径,遍历时边不可以重复,除起点和终点重复外,可能存在其他点重复。在此示例图中,最长路径为:A->B->C->D->E->C->A。
path
path类型的路径由有限的边序列构成。遍历时点和边都不可以重复。
walk、trail、path 总结对比
NebulaGraph 服务架构
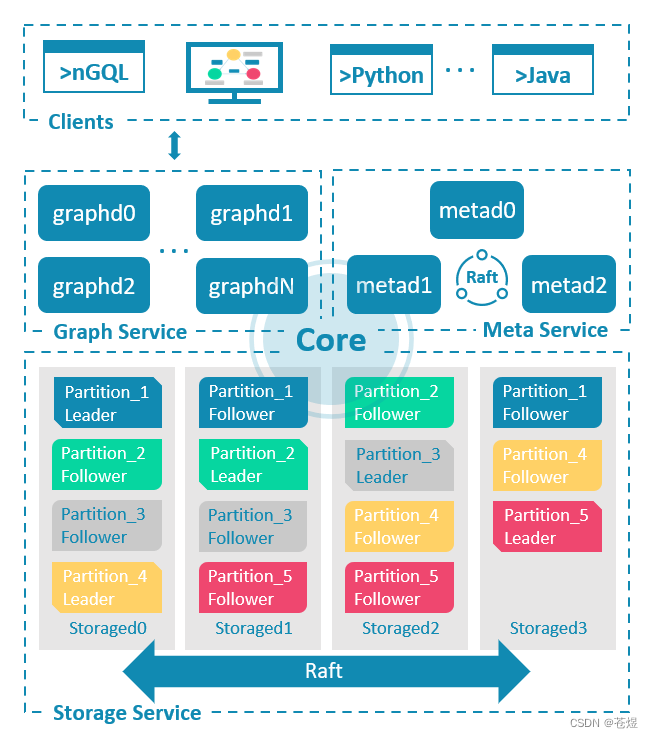
NebulaGraph 架构总览
NebulaGraph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署 NebulaGraph 集群。
下图展示了 NebulaGraph 集群的经典架构。
如果这个看着比较乱,可以看这个:
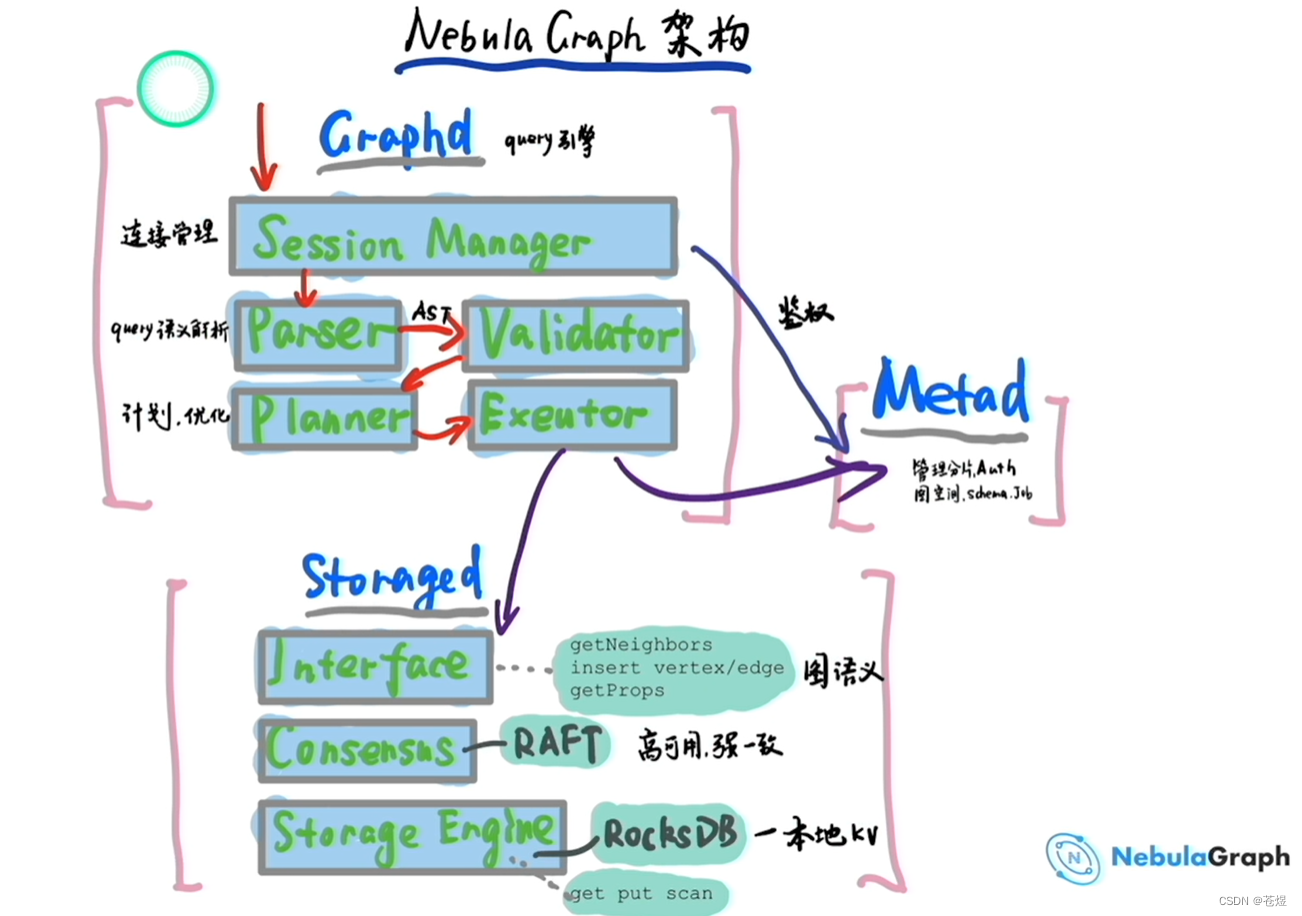
简单来说:
- Meta 服务是由 nebula-metad 进程提供的,负责元数据管理,例如 Schema 操作、集群管理和用户权限管理等。默认启动端口为:9559
- Graph 服务是由 nebula-graphd 进程提供,Graph 服务负责处理计算请求,既用户的query引擎,默认启动端口为:9669
- Storage 服务是由 nebula-storaged 进程提供,Storage 服务负责存储数据,默认启动端口为:9779
Meta 服务架构:默认启动端口为:9559
官网介绍:https://docs.nebula-graph.com.cn/3.6.0/1.introduction/3.nebula-graph-architecture/2.meta-service/
Meta 服务是由 nebula-metad 进程提供的,用户可以根据场景配置 nebula-metad 进程数量,
所有 nebula-metad 进程构成了基于 Raft 协议的集群,其中一个进程是 leader,其他进程都是 follower,leader 是由多数派选举出来,只有 leader 能够对客户端或其他组件提供服务,其他 follower 作为候补,如果 leader 出现故障,会在所有 follower 中选举出新的 leader。
Meta 服务功能:
- 管理用户账号
- 管理分片
- 管理图空间
- 管理 Schema 信息
- 管理 TTL 信息(服务存储 TTL(Time To Live))
- 管理作业
Graph 服务:默认启动端口为:9669
官网介绍:https://docs.nebula-graph.com.cn/3.6.0/1.introduction/3.nebula-graph-architecture/3.graph-service/
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤,
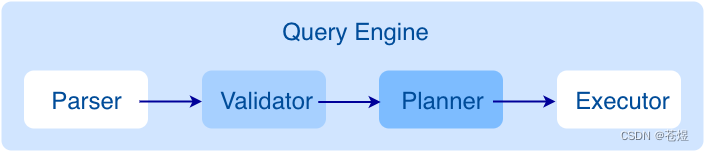
查询请求发送到 Graph 服务后,会由如下模块依次处理:
- Parser:词法语法解析模块。
- Validator:语义校验模块。
- Planner:执行计划与优化器模块。
- Executor:执行引擎模块。
注:不论是nebula 的客户端连接服务还是java等代码连接服务,都要连接9669端口
Storage 服务:默认启动端口为:9779
官网介绍:https://docs.nebula-graph.com.cn/3.6.0/1.introduction/3.nebula-graph-architecture/4.storage-service/
NebulaGraph 的存储包含两个部分,一个是 Meta 相关的存储,称为 Meta 服务,在前文已有介绍。
另一个是具体数据相关的存储,称为 Storage 服务。其运行在 nebula-storaged 进程中。
优势
- 高性能(自研 KVStore)
- 易水平扩展(Shared-nothing 架构,不依赖 NAS 等硬件设备)
- 强一致性(Raft)
- 高可用性(Raft)
- 支持向第三方系统进行同步(例如全文索引)
Nebula Graph 本地化安装部署
部署选择参考:
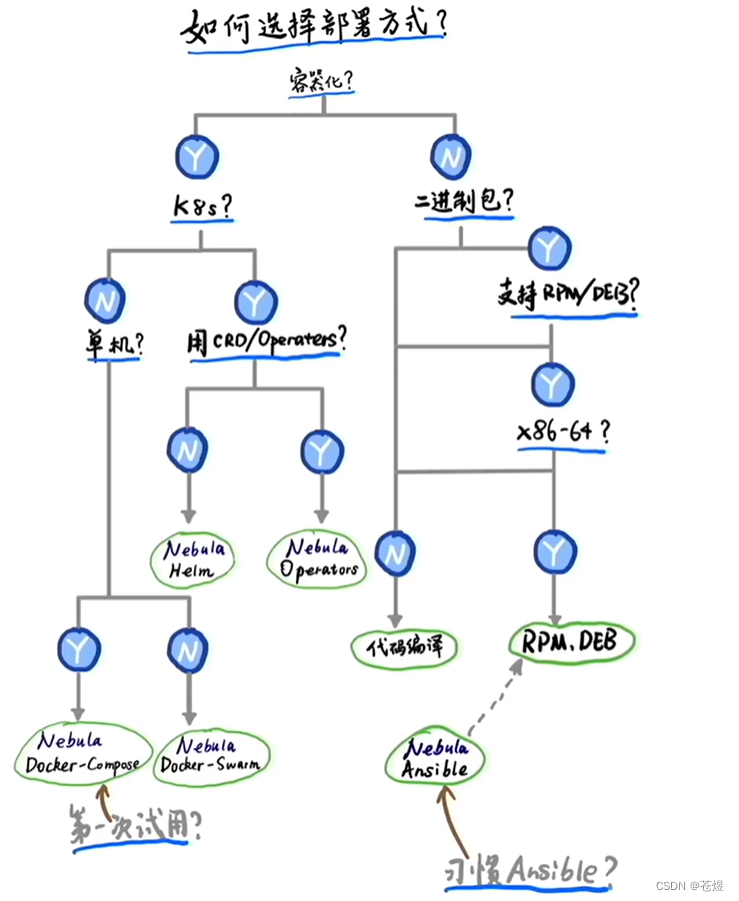
官方说明:https://docs.nebula-graph.com.cn/3.6.0/2.quick-start/3.quick-start-on-premise/2.install-nebula-graph/
部署Nebula Graph 的方法有太多种,目前只在此演示本地部署安装。其他Docker Desktop或者Docker Compose的方式,请大家参考官网基于 Docker 快速部署
1:安装 NebulaGraph
RPM 和 DEB 是 Linux 系统下常见的两种安装包格式;
1:利用weget下载安装包
当前仅支持在 Linux 系统下安装 NebulaGraph,且仅支持 CentOS 7.x、CentOS 8.x、Ubuntu 16.04、Ubuntu 18.04、Ubuntu 20.04 操作系统。
URL 格式如下:
//Centos 7
https://oss-cdn.nebula-graph.com.cn/package/<release_version>/nebula-graph-<release_version>.el7.x86_64.rpm//Centos 8
https://oss-cdn.nebula-graph.com.cn/package/<release_version>/nebula-graph-<release_version>.el8.x86_64.rpm//Ubuntu 1604
https://oss-cdn.nebula-graph.com.cn/package/<release_version>/nebula-graph-<release_version>.ubuntu1604.amd64.deb//Ubuntu 1804
https://oss-cdn.nebula-graph.com.cn/package/<release_version>/nebula-graph-<release_version>.ubuntu1804.amd64.deb//Ubuntu 2004
https://oss-cdn.nebula-graph.com.cn/package/<release_version>/nebula-graph-<release_version>.ubuntu2004.amd64.deb
例如要下载适用于Centos 7.5的3.6.0安装包:
wget https://oss-cdn.nebula-graph.com.cn/package/3.6.0/nebula-graph-3.6.0.el7.x86_64.rpm
wget https://oss-cdn.nebula-graph.com.cn/package/3.6.0/nebula-graph-3.6.0.el7.x86_64.rpm.sha256sum.txt
下载适用于ubuntu 1804的3.6.0安装包:
wget https://oss-cdn.nebula-graph.com.cn/package/3.6.0/nebula-graph-3.6.0.ubuntu1804.amd64.deb
wget https://oss-cdn.nebula-graph.com.cn/package/3.6.0/nebula-graph-3.6.0.ubuntu1804.amd64.deb.sha256sum.txt
我这里下载Centos 7.5的3.6.0安装包

2:安装 NebulaGraph
安装 RPM 包
$ sudo rpm -ivh --prefix=<installation_path> <package_name>
–prefix为可选项,用于指定安装路径。如不设置,系统会将 NebulaGraph 安装到默认路径/usr/local/nebula/。
例如,要在默认路径下安装3.6.0版本的 RPM 包,运行如下命令:
sudo rpm -ivh nebula-graph-3.6.0.el7.x86_64.rpm
安装 DEB 包
$ sudo dpkg -i <package_name>
使用 DEB 包安装 NebulaGraph 时不支持自定义安装路径。默认安装路径为/usr/local/nebula/。
例如安装3.6.0版本的 DEB 包:
sudo dpkg -i nebula-graph-3.6.0.ubuntu1804.amd64.deb
2:启动 NebulaGraph 服务
使用脚本nebula.service管理服务,包括启动、停止、重启、中止和查看。
$ sudo /usr/local/nebula/scripts/nebula.service
[-v] [-c <config_file_path>]
<start | stop | restart | kill | status>
<metad | graphd | storaged | all>
例如:

* 启动服务:
sudo /usr/local/nebula/scripts/nebula.service start all
* 停止服务:
sudo /usr/local/nebula/scripts/nebula.service stop all
* 查看服务:
sudo /usr/local/nebula/scripts/nebula.service status all
如果返回类似如下结果,表示 NebulaGraph 服务异常,可以根据异常服务信息进一步排查
[INFO] nebula-metad: Running as 25600, Listening on 9559
[INFO] nebula-graphd: Exited
[INFO] nebula-storaged: Running as 25646, Listening on 9779
我这里进行查看,发现:

这是因为:
从 3.0.0 版本开始,在配置文件中添加的 Storage 主机无法直接读写,配置文件的作用仅仅是将 Storage 主机注册至 Meta 服务中。必须使用ADD HOSTS命令后,才能正常读写 Storage 主机。而我这里是最新的3.6.0,这个问题放在第4步【4:注册 Storage 服务】解决
3:连接 NebulaGraph 服务-原生命令行客户端 NebulaGraph Console 连接
本文介绍如何使用原生命令行客户端 NebulaGraph Console 连接 NebulaGraph 。
因为:首次连接到 NebulaGraph 后,必须先注册 Storage 服务,才能正常查询数据。
NebulaGraph 支持多种类型的客户端,包括命令行客户端、可视化界面客户端和流行编程语言客户端。
- NebulaGraph Console:原生 CLI 客户端
- NebulaGraph CPP:C++ 客户端
- NebulaGraph Java:Java 客户端
- NebulaGraph Python:Python 客户端
- NebulaGraph Go:Go 客户端
前提条件 - NebulaGraph 服务已启动。
- 运行 Nebula Console 的机器和运行 NebulaGraph 的服务器网络互通。
- Nebula Console 的版本兼容 NebulaGraph 的版本。
1:在 Nebula Console 下载页面,确认需要的版本,单击 Assets。【建议选择最新版本】
2:(可选)为方便使用,重命名文件为nebula-console。【在 Windows 系统中,请重命名为nebula-console.exe。】
3:在运行 Nebula Console 的机器上执行如下命令,为用户授予 nebula-console 文件的执行权限。【Windows 系统请跳过此步骤。】
chmod 111 nebula-console
4:在命令行界面中,切换工作目录至 nebula-console 文件所在目录。
5:执行如下命令连接 NebulaGraph。
#Linux 或 macOS
./nebula-console -addr -port -u -p
[-t 120] [-e “nGQL_statement” | -f filename.nGQL]
#Windows
nebula-console.exe -addr -port -u -p
[-t 120] [-e “nGQL_statement” | -f filename.nGQL]
示例:
nebula-console.exe -addr 192.168.13.10 -port 9669 -u root -p 12345
连接成功的标识:

4:注册 Storage 服务
首次连接到 NebulaGraph 后,需要先添加 Storage 主机,并确认主机都处于在线状态。
前提条件
已连接 NebulaGraph 服务。
1:添加 Storage 主机。
执行如下命令添加主机:ADD HOSTS : [,: …];
示例:
ADD HOSTS 127.0.0.1:9779;

2:检查主机状态,确认全部在线。
SHOW HOSTS;
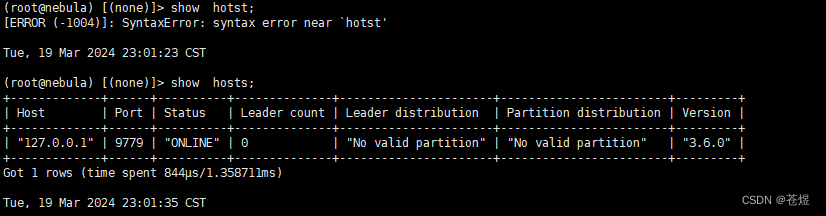
3:检查Nebula Graph 都已经启动了

NebulaGraph Studio-可视化web工具安装
1:什么是 NebulaGraph Studio
NebulaGraph Studio(简称 Studio)是一款可以通过 Web 访问的开源图数据库可视化工具,搭配 NebulaGraph 内核使用,提供构图、数据导入、编写 nGQL 查询等一站式服务。
产品功能¶
Studio 可以方便管理 NebulaGraph 数据,具备以下功能:
- 使用 Schema 管理功能,用户可以使用图形界面完成图空间、Tag(标签)、Edge Type(边类型)、索引的创建,查看图空间的统计数据,快速上手 NebulaGraph 。
- 使用导入功能,通过简单的配置,用户即能批量导入点和边数据,并能实时查看数据导入日志。
- 使用控制台功能,用户可以使用 nGQL 语句创建 Schema,并对数据执行增删改查操作。
适用场景¶
如果有以下任一需求,都可以使用 Studio:
- 已经安装部署了 NebulaGraph,想使用 GUI 工具创建 Schema、导入数据、执行 nGQL 语句查询。
- 刚开始学习 nGQL(NebulaGraph Query Language),但是不习惯用命令行工具,更希望使用 GUI 工具查看语句输出的结果。
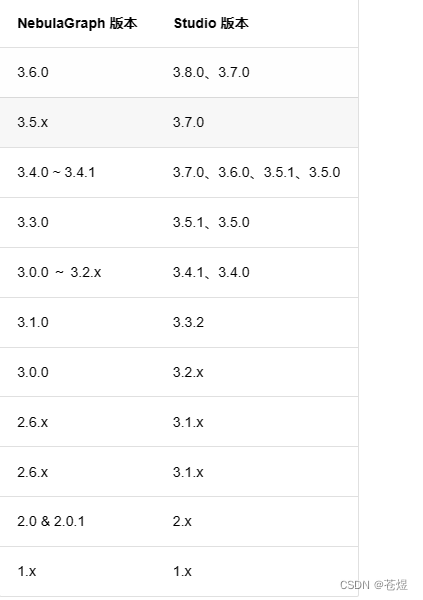
版本兼容性
Studio 版本发布节奏独立于 NebulaGraph 内核,其命名方式也不参照内核命名规则,两者兼容对应关系如下表。
2:部署 Studio
官网说明:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/deploy-connect/st-ug-deploy/
1:前提条件¶
在部署 RPM 版 Studio 之前,用户需要确认以下信息:
- NebulaGraph 服务已经部署并启动。详细信息,参考 NebulaGraph 安装部署。
- 使用的 Linux 发行版为 CentOS ,已安装 lsof。
- 确保以下端口未被占用。
端口号 说明
7001 Studio 提供 web 服务使用。
Studio 下载链接:https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.8.0/nebula-graph-studio-3.8.0.x86_64.rpm?_gl=1ihkswg_gaODA1MTU2MTYzLjE3MTA4NDc5OTY._ga_BGGB2REDGM*MTcxMDg1NTcyNy4yLjEuMTcxMDg2MTQ1MC40NC4wLjA.
2:使用sudo rpm -i <rpm_name>命令安装 RPM 包。
例如,安装 Studio 3.8.0 版本需要运行以下命令,默认安装路径为/usr/local/nebula-graph-studio
$ sudo rpm -i nebula-graph-studio-3.8.0.x86_64.rpm
也可以使用以下命令安装到指定路径:
$ sudo rpm -i nebula-graph-studio-3.8.0.x86_64.rpm --prefix=
当屏幕返回以下信息时,表示 PRM 版 Studio 已经成功启动。

3:启动成功后,在浏览器地址栏输入 http://:7001。
如果在浏览器窗口中能看到以下登录界面,表示已经成功部署并启动 Studio。
卸载¶
用户可以使用以下的命令卸载 Studio。
$ sudo rpm -e nebula-graph-studio-3.8.0.x86_64
当屏幕返回以下信息时,表示 PRM 版 Studio 已经卸载。
NebulaGraph Studio removed, bye~
注:如果启动服务时遇到报错 ERROR: bind EADDRINUSE 0.0.0.0:7001,用户可以通过以下命令查看端口 7001 是否被占用。
$ lsof -i:7001
如果端口被占用,且无法结束该端口上进程,用户可以修改 studio 配置内的启动端口,并重新启动服务。
//修改 studio 服务配置。配置文件默认路径为
/usr/local/nebula-graph-studio。
$ vi etc/studio-api.yaml
//修改端口号,改成任意一个当前可用的即可。
Port: 7001
//重启服务
$ systemctl restart nebula-graph-studio.service
4:Studio 连接数据库
在成功启动 Studio 后,用户需要配置连接 NebulaGraph 。
前提条件¶
在连接 NebulaGraph 数据库前,用户需要确认以下信息:
- Studio 已经启动。详细信息参考部署 Studio。
- NebulaGraph 的 Graph 服务本机 IP 地址以及服务所用端口。默认端口为 9669。
- NebulaGraph 登录账号信息,包括用户名和密码。
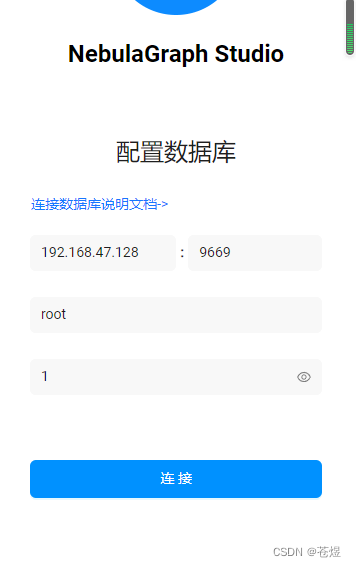
1:在 Studio 的 配置数据库 页面上,输入以下信息:
- Graphd IP 地址:填写 NebulaGraph 的 Graph 服务本机 IP 地址。例如192.168.10.100
即使 NebulaGraph 与 Studio 部署在同一台机器上,用户也必须填写这台机器的本机 IP 地址,而不是 127.0.0.1 或者 localhost。 - Port:Graphd 服务的端口。默认为9669
- 用户名 和 密码:根据 NebulaGraph 的身份验证设置填写登录账号和密码。
如果未启用身份验证,可以填写默认用户名 root 和任意密码。
如果已启用身份验证,但是未创建账号信息,用户只能以 GOD 角色登录,必须填写 root 及对应的密码 nebula。
如果已启用身份验证,同时又创建了不同的用户并分配了角色,不同角色的用户使用自己的账号和密码登录。
3:点击连接
这篇关于Nebula Graph-01-Nebula Graph简介和安装以及客户端连接的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









