本文主要是介绍segformer多分类语义分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言
本期将分享「Segformer」,论文地址https://arxiv.org/abs/2105.15203。
Segformer简介
-
全局上下文信息: 由于Transformer的自注意力机制,Segformer可以在整个图像范围内捕获上下文信息,而不受局部感受野的限制,这有助于提高分割的准确性。 -
可扩展性: Transformer架构的并行计算能力使得Segformer在处理大尺度图像时表现更好,因为它可以更轻松地处理长距离的依赖关系。 -
位置编码机制: Segformer使用了一种新的位置编码机制,有助于模型更好地理解像素之间的空间关系,从而提高分割的精度。 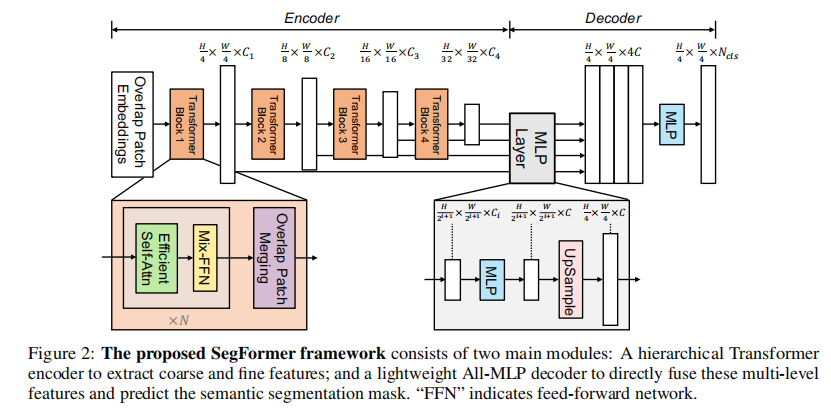
数据集介绍
ISPRS提供了城市分类和三维建筑重建测试项目的两个最先进的机载图像数据集。该数据集采用了由高分辨率正交照片和相应的密集图像匹配技术产生的数字地表模型(DSM)。这两个数据集区域都涵盖了城市场景。其中Vaihingen是一个相对较小的村庄,有许多独立的建筑和小的多层建筑。
-
不透水面 (RGB: 255, 255, 255)
-
建筑物(RGB: 0, 0, 255)
-
低矮植被 (RGB: 0, 255, 255)
-
树木 (RGB: 0, 255, 0)
-
汽车(RGB: 255, 255, 0)
-
背景 (RGB: 255, 0, 0)
数据集处理
需要对原始数据集进行切分,并将原始值变成标签。这里我们使用gdal库,按256*256的滑窗进行裁切,并根据颜色映射进行赋值。
from osgeo import gdal, gdalconst
import os
import numpy as np
def color_to_value(rgb):
color_mapping = {
(255, 255, 255): 1, # Impervious surfaces
(0, 0, 255): 2, # Building
(0, 255, 255): 3, # Low vegetation
(0, 255, 0): 4, # Tree
(255, 255, 0): 5, # Car
(255, 0, 0): 0 # Clutter/background
}
return color_mapping.get(tuple(rgb), 6)
def crop_images(image_folder1,label_folder, output_image_folder1,output_label_folder, size=256,window=256):
# 获取文件夹中的文件名列表
image_files1 = os.listdir(image_folder1)
label_files = os.listdir(label_folder)
# 遍历每个文件
for image_file in image_files1:
if image_file in label_files:
# 读取图像和标签
image_path1 = os.path.join(image_folder1, image_file)
label_path = os.path.join(label_folder, image_file)
# 打开遥感影像文件
image_dataset1 = gdal.Open(image_path1, gdalconst.GA_ReadOnly)
label_dataset = gdal.Open(label_path, gdalconst.GA_ReadOnly)
if image_dataset1 is None or label_dataset is None:
print(f"Failed to open {image_file} ")
continue
image_width1 = image_dataset1.RasterXSize
image_height1 = image_dataset1.RasterYSize
label_width = label_dataset.RasterXSize
label_height = label_dataset.RasterYSize
# 创建单通道数组
single_channel_array = np.zeros((label_height, label_width), dtype=np.uint8)
label_array = label_dataset.ReadAsArray()
# 遍历图像像素,并根据颜色映射进行赋值
for y in range(label_height):
for x in range(label_width):
pixel_value = color_to_value(label_array[:, y, x])
single_channel_array[y, x] = pixel_value
# 循环裁剪图像和标签
for y in range(0, image_height1 - size, window):
for x in range(0, image_width1 - size, window):
# 读取图像数据
image_data1 = image_dataset1.ReadAsArray(x, y, size, size)
label_data = single_channel_array[y:y+size,x:x+size]
# 保存裁剪后的图像和标签
output_image_path1 = os.path.join(output_image_folder1, f"{image_file[:-4]}_{x}_{y}.tif")
output_label_path = os.path.join(output_label_folder, f"{image_file[:-4]}_{x}_{y}.tif")
driver = gdal.GetDriverByName("GTiff")
new_image1 = driver.Create(output_image_path1, size, size, 3, gdal.GDT_Byte)
new_label = driver.Create(output_label_path, size, size, 1, gdal.GDT_Byte)
new_image1.SetProjection(image_dataset1.GetProjection())
new_image1.SetGeoTransform(
(x, image_dataset1.GetGeoTransform()[1], 0, y, 0, image_dataset1.GetGeoTransform()[5]))
new_label.SetProjection(label_dataset.GetProjection())
new_label.SetGeoTransform(
(x, label_dataset.GetGeoTransform()[1], 0, y, 0, label_dataset.GetGeoTransform()[5]))
new_image1.GetRasterBand(1).WriteArray(image_data1[0])
new_image1.GetRasterBand(2).WriteArray(image_data1[1])
new_image1.GetRasterBand(3).WriteArray(image_data1[2])
new_label.GetRasterBand(1).WriteArray(label_data)
new_image1.FlushCache()
new_label.FlushCache()
del new_image1, new_label
image_dataset1 = None
label_dataset = None
# 使用示例
crop_images(r"G:\download\ISPRS_semantic_labeling_Vaihingen\top",r"G:\download\ISPRS_semantic_labeling_Vaihingen\gts_for_participants" ,r"G:\download\ISPRS_semantic_labeling_Vaihingen\images",r"G:\download\ISPRS_semantic_labeling_Vaihingen\labels",size=256)
裁剪完成后对数据集进行划分,划分完成后的数据集包含679对训练集、156对验证集以及211对测试集。原始数据集与切分后数据集获取链接见文末。
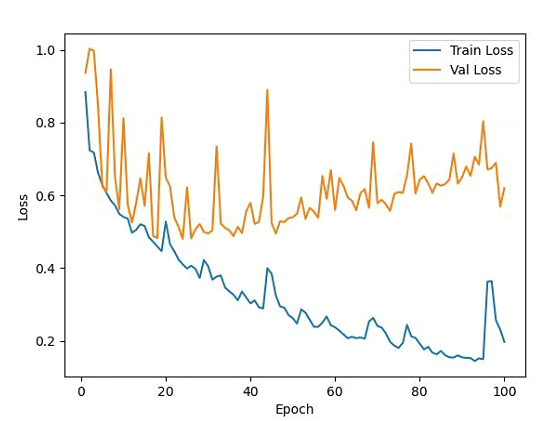
loss变化
测试精度
这里的iou0~iou5分别代表背景、建筑物等iou值。 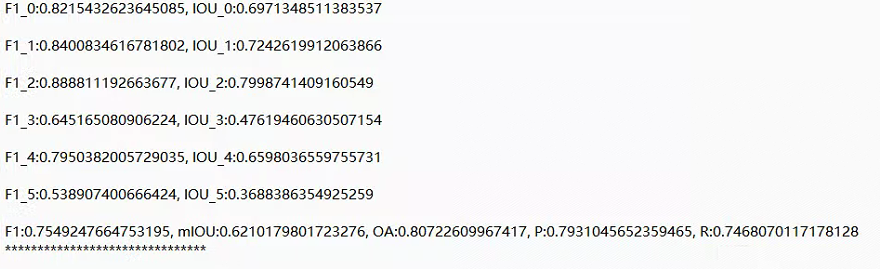
总结
按以下方式获取文中数据集。完整代码与训练结果请加入我们的星球。
如有需要,请关注微信公众号「DataAssassin」后,后台回复「030」领取。
「感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的」。
 加入前不要忘了领取优惠券哦!
加入前不要忘了领取优惠券哦! 
往期精彩



本文由 mdnice 多平台发布
这篇关于segformer多分类语义分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





