本文主要是介绍[论文阅读71]SELF-INSTRUCT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions | Yizhong Wang等University of Washington | 2022.12 |
7 Citations
论文链接:https://arxiv.org/pdf/2212.10560.pdf
论文代码:https://github.com/yizhongw/self-instruct
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| LLM的指令的生成 | 解决人工写prompting的问题 | 提出了Self-instruct框架。使用普通的预训练语言模型本身生成任务与的流程, | 方法简单,效果很好。 | 1.对最初模型有30%的提升; | instruction-tuned,LLM |
3. 模型(核心内容)
3.1 模型框架
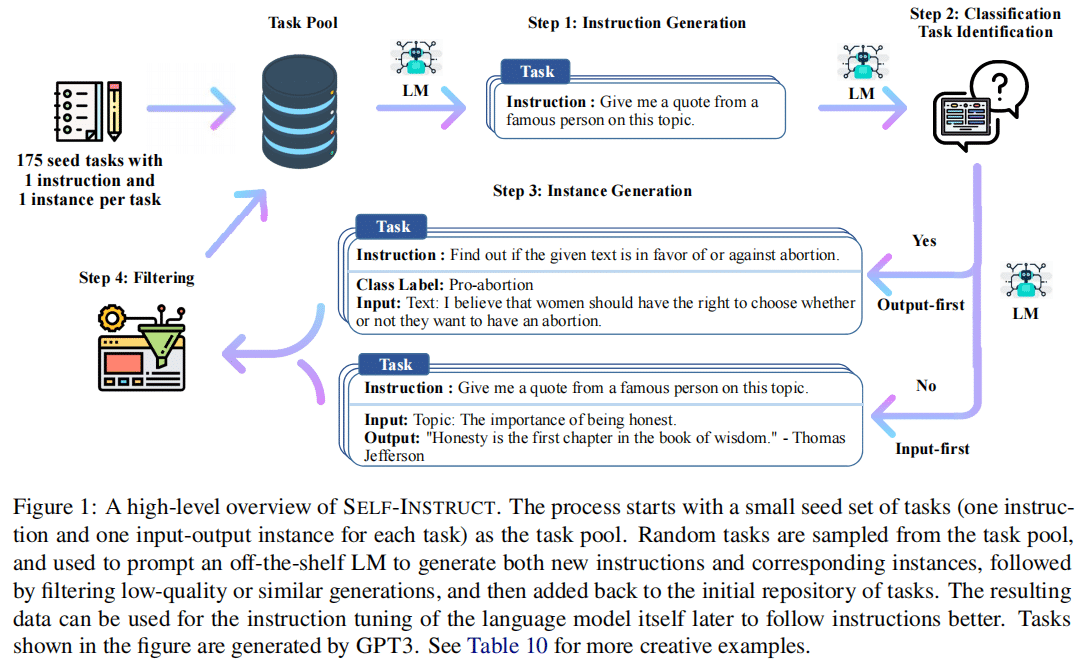
3.1.1 数据定义
定义指定集为 { I t } \{I_t\} {It}
每个指令定义成一个NLP任务t。
对于每个任务又有数据实例
( X t , Y t ) (X_t,Y_t) (Xt,Yt)
对于模型M,用来预测结果y,给定一个指令与输入的实例x:
M ( { I t } , x ) = y , f o r ( x , y ) ∈ ( X t , Y t ) M(\{I_t\},x) = y, for (x,y) \isin(X_t,Y_t) M({It},x)=y,for(x,y)∈(Xt,Yt)
举例:
instruction: “write an essay about the following topic”
instance input x:“school safety”
instance output y: 采用模型M业计算
为了让模型生成多样性,x可设置为空的。
或者instruction与input合起来写成一个条instruction:“write an essay about school safety”
没有太明确的边界。
3.1.2 自动生成指令数据
第一步:指令生成;
从手工初始化175条数据(1 instruction and 1 instance for each task)任务池,让模型去生成指令。每步采样8条任务指令作为上下文的样本,其中6条是手工的,2条是基于模型生成的。
第二步:标记指令是分类任务与否;
通过对GPT-3进行few-shot来判断是否是分类任务,这里从任务池中取出12条分类指令与19条非分类指令。
第三步:输入优先或输出优先的方法来生成实例;
给出指令与任务类型,对每个指令独立地直接生成实例。
Input-first Approach:首先让模型根据指令生成输入的数据,然后用输入的数据去生成对应的输出数据。
Output-first Approach:多于分类任务。首先生成可能的类标签,然后对每个类标签的输入生成进行条件处理。
第四步:过滤底质量数据;过滤掉ROUGE-L<0.7的数据;
3.1.3根据指令微调模型
instruction+instance作为输入,模型生成的数据作为输出,这个一个典型的监督学习
4. 数据分析
4.1 数据来自GPT3
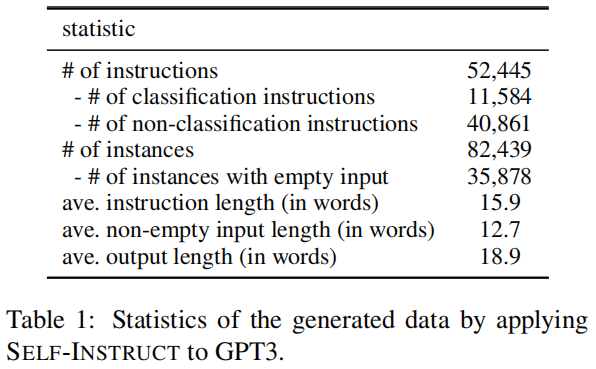
生成数据评估:
Berkeley Neural Parser:
https://parser.kitaev.io/
数据多样性情况:
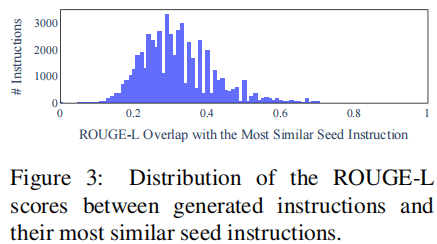
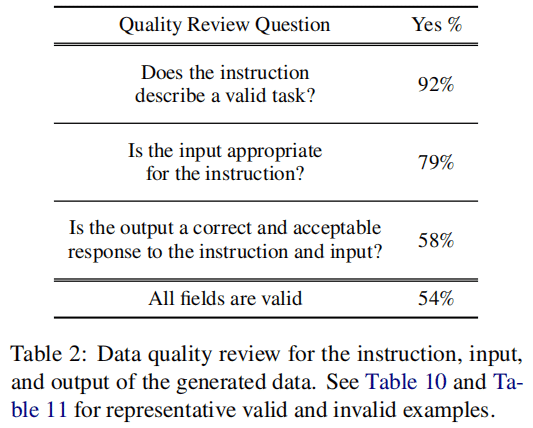
数据质量:
5. 代码
6. 总结
6.1 优
6.4 不足
7. 知识整理(知识点,要读的文献,摘取原文)
8. 参考文献
made by happyprince
这篇关于[论文阅读71]SELF-INSTRUCT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
