本文主要是介绍图表征模型研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图表征对于知识图谱是很重要的,如何将图进行embedding,并输入到深度学习模型中,是一个热点问题。
1. GraphSage模型
主要应用于同构图中,是一种归纳式的图表征模型,首先从一个图中训练出embedding方法,在图更新频率高,出现未知的节点时,能够基于邻居节点快速对未知节点进行embedding,而不必对全图进行重新训练。
源码:pytorch版:https://gitcode.com/mirrors/twjiang/graphsage-pytorch/tree/master
tensorflow版:https://github.com/williamleif/GraphSAGE
模型原理:1)先随机采样1层或2层邻居节点,通常k=2;2)从采样的最外层(一般是第2层)向内聚合,可以采用mean、max、lstm等聚合函数将邻居节点进行聚合,再将聚合后的邻局embedding与下一层的节点进行拼接concat,再通过激活函数得到下一层节点的embedding;3)重复步骤2,直到得到目标节点的embedding。
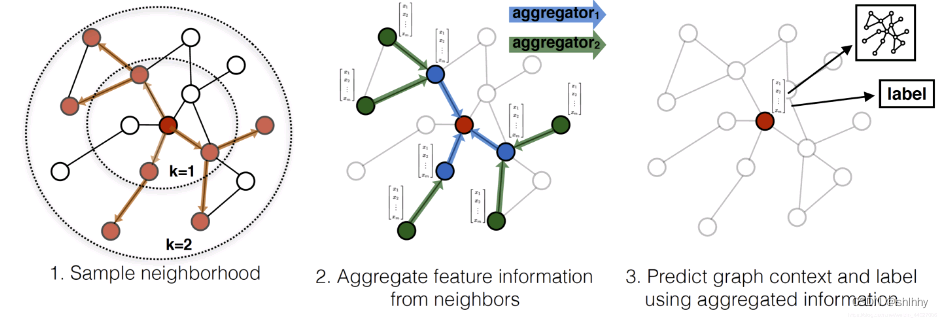
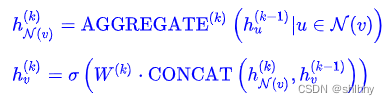
模型训练:
- 无监督:假设节点的相似性与其距离呈正相关,邻近节点应当相似,不相邻节点应当不相似
- 有监督:更换损失函数,例如交叉熵损失函数。
2. metapath2vec模型
可以用于异构图网络,先人为设计一些metapath(元路径),例如一个金融诈骗图中有人员person、手机号Tel、邮箱email,人为设计元路径:PTP,即2人共用一个号码,采样时从一个person出发,只会walk到邻接的tel上,再从tel走到下一个person上,不会随机乱走到其它类型的节点上。
得到节点的游走序列,再将序列输入到skip-gram中以得到每个节点的嵌入表示。
源码:https://github.com/PaddlePaddle/PGL/tree/main/examples/metapath2vec
3. 实践
此处以torch版graphsage为例,下载并解压源码。
模型的输入是:paper–>paper,关系是:引用,对于每个paper节点,采用其关键词的词袋(出现为1,不出现为0)生成每个paper的特征向量。(对于自己的数据集,需要考虑采用节点的什么属性生成每个节点的特征向量,这是很重要的一步。其中类型属性列可以采用one-hot编码)
模型训练过程源码的说明,此处为有监督训练。
# 模型参数,w和bias矩阵
model.parameters()
# 模型参数是否冻结,不更新w和bias矩阵
param.requires_grad
# 优化器,常用的有SGD、ADAM等
torch.optim.SGD(params, lr=0.7)
# 梯度置0,因为训练的过程通常使用mini-batch方法,所以如果不将梯度清零的话,梯度会与上一个batch的数据相关
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 梯度裁剪,缓解梯度爆炸的问题
nn.utils.clip_grad_norm_(model.parameters(), 5)
# 执行一次优化步骤,通过梯度下降法来更新w和bias矩阵
optimizer.step()
# 有监督训练时采用分类模型计算loss
logists = classification(embs_batch)
loss_sup = -torch.sum(logists[range(logists.size(0)), labels_batch], 0)
loss_sup /= len(nodes_batch)
loss = loss_sup
# 计算f1、acc、recall
vali_f1 = f1_score(labels_val, predicts.cpu().data)
vali_acc = accuracy_score(labels_val, predicts.cpu().data)
vali_recall = recall_score(labels_val, predicts.cpu().data)
执行main.py,开始训练,控制台会打印每个epoch的的训练过程,最后保存一个f1最高的torch模型结果在本地。
查看节点embedding。
# 加载模型,包含一个graphsage,一个classification
model = torch.load(model_file)
# 输入2个节点,获取其embedding
nodes = np.asarray([1, 3])
nodes_emb = model[0](nodes)
# 将embedding输入分类模型,获取分类结果
logists = model[1](embs_batch)
label_prob, label_predict = torch.max(logists , 1)
这篇关于图表征模型研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








