本文主要是介绍结构体中的内存对齐是什么?一起搞懂它,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

c语言中的小小白-CSDN博客c语言中的小小白关注算法,c++,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm=1001.2014.3001.5343

给大家分享一句我很喜欢我话:
知不足而奋进,望远山而前行!!!
铁铁们,成功的路上必然是孤独且艰难的,但是我们不可以放弃,远山就在前方,但我们能力仍然不足,所有我们更要奋进前行!!!
今天我们更新了结构体内存对齐的内容,
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
一、结构体
1.1结构体内存对齐:
首先我们来看一下结构体内存对齐的规则:
1、第一个成员在与结构体变量偏移量为0的地址处;
2、其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处(对齐数=编译器默认的一个对齐数 与 该成员大小的较小值)( vs中默认的值为8);
3、结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍;
4、如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构的对齐数)的整数倍。
1.2结构体内存对齐的计算:
先给你一段代码:
struct S1 {
char a;//(1,8)->1 //char的大小为1,vs默认对齐数为8,选择较小的1为对齐数
int b;//(4,8)->4//int的大小为4,vs默认对齐数为8,选择较小的4为对齐数
int c;//(4,8)->4//同上
}; int main()
{printf("%zd",sizeof(struct S1));return 0;
}你认为这串代码的结果是什么,是不是和我刚开始一样,认为结果是6,但其实结果是12,下面我们来说一下为什么?
如下图所示:

其实大致过程就是:第一个元素先放在0处,然后第二个是int类型的,占四个字节,然后要找的对齐数就必须是4的倍数,所以要找到四,然后往下走四个,到达8这个位置,然后有一个char类型的,然后找到9,但是我们还有一点就是结构体的总大小必须为最大对齐数的整数倍,最大对齐数位4,但是9不符合,因此我们需要找到12,所以就会输出12了。
1.3修改默认对齐数:
#include<stdio.h>
#pragma pack(1)//改变最大对齐数,此时的最大对齐数为1,所以结果就是6了
struct stu
{char c1;int n;char c2;
};
#pragma pack()
int main()
{printf("%zd", sizeof(struct stu));return 0;
}
这个就是将最大对齐数改为11,然后结果就和刚才我们预测的一样了,是6,因为后面所有的数都是1的倍数,所以不需要1跳过什么,直接计算就可以。
那为什么我们要对齐呢,这样不会浪费空间吗,下面我们来看一张图片吧:
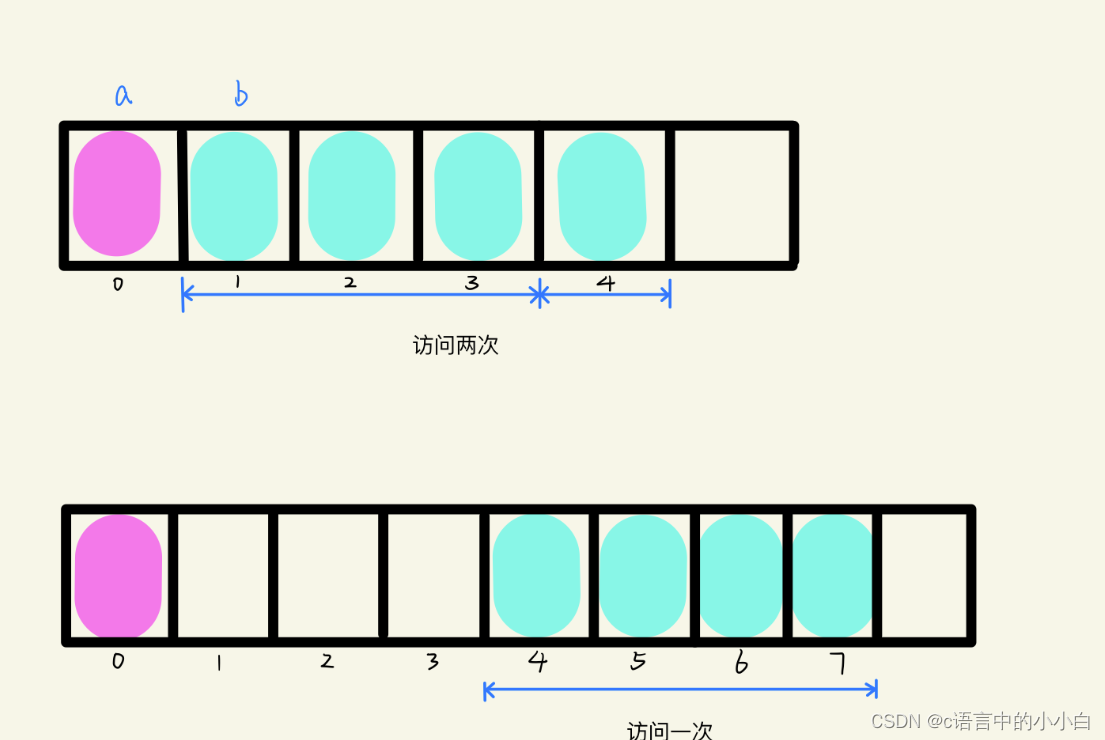
看完这张图片是不是恍然大悟了,因为一个字节是四个比特位嘛,所以如果按上面的方式,就会需要访问两次,所以我们对齐,这样会节省很多时间,但是同时会浪费一些空间。
二、结构体传参
结构体传参是怎样进行的呢,下面我们先来看一下这段代码:
//struct stu {
// int arr[100];
// int n;
// double b;
//};
//
//void print1(struct stu tmp)
//{
// int i = 0;
// for (i = 0; i < 5; i++)
// {
// printf("%d ", tmp.arr[i]);
// }
// printf("\n%d\n", tmp.n);
// printf("%.2lf", tmp.b);这段代码其实也可以实现结构体的传参,但是我们可以发现,传参时会复制一份原来的结构体,供给函数使用,但是这样会占用更多的内存,下面我们来试一下一级指针传参:
void print2(struct stu* ps)
{for (int i = 0; i < 5; i++){printf("%d ", ps->arr[i]);}printf("\n%d\n", ps->n);printf("%.2lf", ps->b);
}int main()
{struct stu s = { {1,2,3,4,5},10,3.14 };//print1(s);print2(&s);//这样传递效率会更高一点。return 0;
}看一下这串代码,这串代码便利用了一级指针进行传参,节省了不少空间。
三、结构体位段:
3.1格式:
(1)位段的成员必须是int、unsigned int 或 signed int;
(2)位段的成员名后边有一个冒号和一个数字。
下面看一下这串代码:
struct S {int _a : 2;//_a只占2bitint _b : 5;//-b只占5bitint _c : 10;//_c只占10bitint _d : 30;//_d只占30bit
}s;//8B
这便是一个位段,我们提前就规定了他们各占几个字节,那样便可以节省许多内存。
同样在内存分配时,也会受这方面的影响。
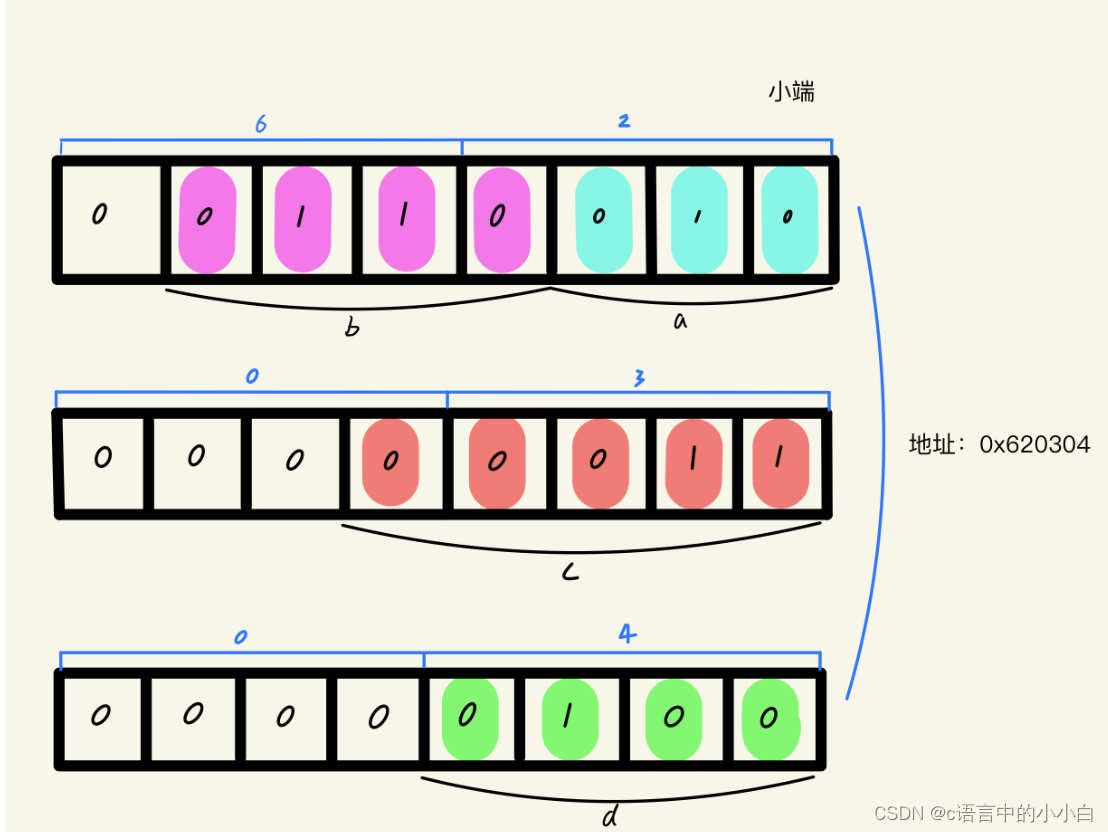
struct SS {char a : 3;//a只占3bitchar b : 4;char c : 5;char d : 4;
}ss;
int main() {printf("%d\n", sizeof(struct SS));//3;ss.a = 10;//1010->010-> 010ss.b = 12;//1100->1100-> 0110 0110ss.c = 3;//11->00011-> 0000 0011ss.d = 4;//100->0100-> 0000 0100//&ss -> 0x 62 03 04return 0;
}
从这串代码的注释即可看出。
内存分配演示图:
总结:
这篇文章我们讲了关于结构体的一些内容,比较重要的就是结构体的内存对齐部分,这方面一定要搞懂才可以。
这篇关于结构体中的内存对齐是什么?一起搞懂它的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



