本文主要是介绍为什么Erlang比C慢那么多倍?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Erlang 一直以慢“著称”,本文就来看看 Erlang 慢在什么地方,为什么比实现同样功能的 C 语言程序慢那么多倍。Erlang 作为一种虚拟机解释的语言,慢是当然的。不过本文从细节上分析为什么 Erlang 这种虚拟机语言会慢。
本文从 shootout benchmark[注1]中选择了一个 Erlang 和 C 语言单核性能差距最大的例子——reverse complement[注2]。根据 shootout 网站上给出的使用某款 64 位处理器单个核心的 benchmark 数据,Erlang 实现消耗的 CPU 时间为 19.20 秒,而 C 语言实现消耗的时间为 0.71 秒。也就是说,Erlang 实现同样的功能慢了 27 倍。本文暂不关心 Erlang 的多进程并行化的加速性能,只关心 Erlang 虚拟机单个线程执行机构的性能。
我们先来看一下这个程序要实现的功能是什么。刚好这个例子实现的功能是 shootout benchmark 目前 13 个测试中最好理解的,不需要任何数学背景和复杂的数据结构或算法,只涉及到非常简单的高中生物学知识。这个程序的功能是计算给定 DNA 序列的反向互补链。根据高中生物学,DNA 序列就是碱基对序列,碱基对是由两个互补的碱基构成的。碱基的互补关系如下所示:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
中间那一列不用管了,也就是说左边那一列的互补碱基就是右边那一列。假设有一个序列为 ACG,那么互补序列就是 TGC,而我们要求的反向互补序列就是 CGT,要求反向的原因和 DNA 的反向转录有关。程序的输入采用 FASTA 格式,这个格式很简单,例如这个页面上的示例输入文件。FASTA 文件分为多个段落,每个段落有一个 ">" 表示的开头,这一行后面是 DNA 序列的一些信息,具体意义我们不管。接下来的行就是具体的 DNA 序列,每一行显示 60 个碱基。在具体的 FASTA 文件中碱基既可以用大写表示,也可以使用小写。要求程序输出 FASTA 格式的反向互补序列,其中“>”行照抄。比如下面这个输入文件
| 1 2 3 |
|
得到的输出文件是
| 1 2 3 |
|
分析程序的需求,可以看出这个程序数据处理方面的工作在于输入文件的解析、断行拼接、计算互补序列、计算反向序列以及结果的断行输出。shootout 网站上最快的 C 语言程序在这里。这个 C 语言程序采用的方法是首先将整个文件读到一个缓冲区中,然后解析文件,找“>”行,那么这一行到下一个 “>” 行之间就是一个完整的 DNA 序列,创建新的工作线程,把这个 DNA 序列在整个缓冲区中的位置信息传递给工作线程,工作线程负责计算互补的碱基并且写入缓冲区。工作线程的主体部分很简单,维护两个指针,一头一尾,每一轮迭代都向中间挪一个位置。每一轮迭代中,计算一头一尾的互补碱基,然后交换,当头尾相遇的时候结束。当然,如果 DNA 序列最后一行不能填满 60 个字节,工作线程还要先挪动每一行的位置,使得交换之后换行符的位置正确。这个 C 语言程序计算互补碱基采用了查表法,由于输入值就是大小写字母和换行符,所以只需要一个不大的查找表(128字节)。
这个 C 语言程序的效率相当高,只需要一次扫描和一次写入。在最坏情况下,如果最后一行不满 60 个字符,则还需要一趟拷贝调整换行符的位置。
然后我们来看一看 shootout 网站上提供的 Erlang 程序。
这个 Erlang 程序的大致工作流程为:主进程(命名为 reader,运行 loop 函数)从 stdin 中一行一行地读取,凑齐一段完整的 DNA 序列之后,就创建一个新的进程(命名为 collector 进程)处理并打印(至 stdout)这个序列。reader 进程等待 collector 进程完成了打印之后,再继续从 stdin 中一行一行地读。collector 进程之所以叫 collector,是因为这个进程将计算反向互补序列的工作分割为几个大小均等并且带有编号的“块”,并创建若干工作进程(对应 revcomp_chunk 函数),让每个进程处理一个块,等所有工作进程都干完了之后,collector 进程对所有的块按照编号进行排序,得到正确顺序的结果,然后再将“>”行和结果都输出到 stdout。
下面简单地对 shootout 网站上提供的那个 Erlang 程序做了一些注释,我们可以看到这个程序慢在哪里:
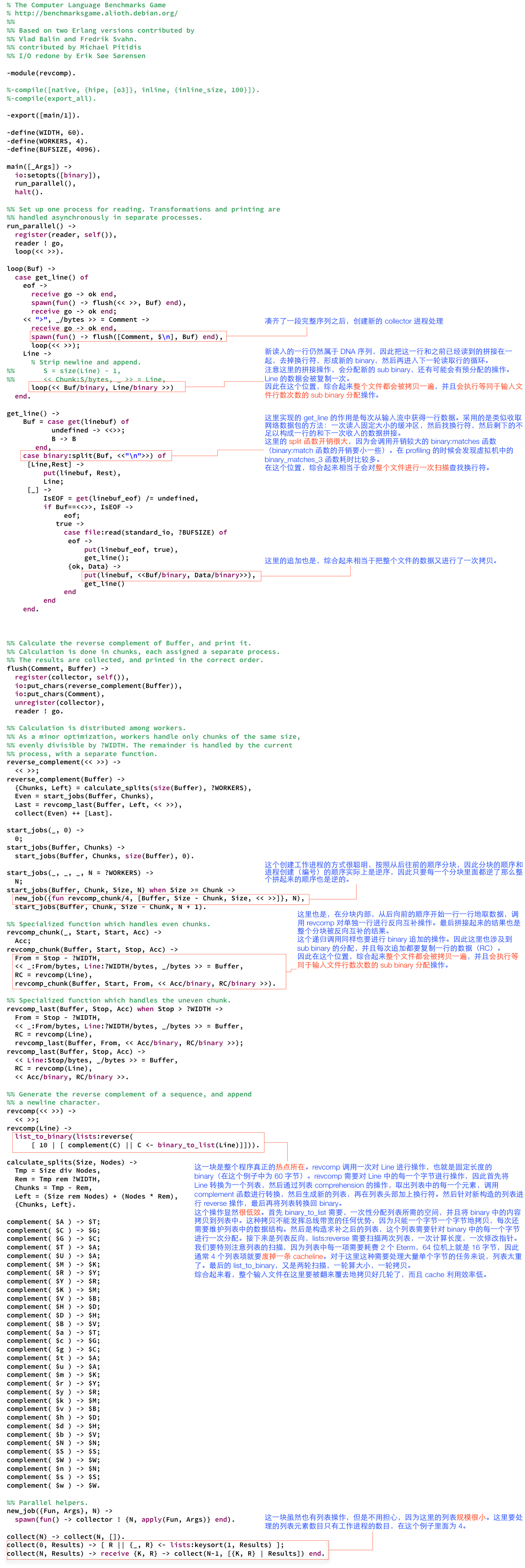
然后我就按照之前说的那个 C 语言程序的思路,另外写了一个 Erlang 程序,对 binary 的操作做了一些优化,主要使用了 binary comprehension 来缓解上述程序中的热点,不过运行时间提升并不大,大概快了 10% 吧。为啥还是慢呢?下面来细细分析。先看代码吧:
-module(revcomp_opt).-export([main/1]).-define(WIDTH, 60).
-define(BUFSIZE, 1024*1024).
-define(NEWLINECHAR, 10).-record(scan_state,{current_state = search_header_begin, % search_header_end,search_is_overcurrent_header = <<>>,current_body = [<<>>]}).main([_Args]) ->io:setopts([binary]),InitState = #scan_state{current_state = search_header_begin,current_header = <<>>,current_body = []},% fprof:trace(start, "revcomp_opt_small.trace"),read_and_process_file(<<>>, InitState, []),% fprof:trace(stop),halt().read_and_process_file(Buf, State, JobList) ->case State#scan_state.current_state ofsearch_header_begin -> % 寻找">"case binary:match(Buf, <<">">>) ofnomatch ->% 继续搜索,新添加的内容应该放在 body 中NState = State#scan_state{current_body=[Buf | State#scan_state.current_body]},get_new_chunk(NState, JobList);{HeaderStartPos, _Length} ->% 找到了">", 说明要开启新的行,并且结束之前的 body% 创建新的进程处理 header/body {PreviousBody, BufLeft} = split_binary(Buf, HeaderStartPos),NState = State#scan_state{current_state = search_header_end,current_header = <<>>,current_body = []},case State#scan_state.current_header of<<>> ->% 表示是第一次进来,继续找 header 的结尾“\n”read_and_process_file(BufLeft, NState, JobList);_ ->% 形成了新的完整 body,创建新的进程处理NewJob = start_revcomp_job(State#scan_state.current_header,[PreviousBody | State#scan_state.current_body],self()),read_and_process_file(BufLeft, NState, [NewJob | JobList])endend;search_header_end -> % 寻找 ">" 行结尾的 "\n"case binary:match(Buf, <<"\n">>) ofnomatch ->% 继续搜索,如果没找到,则把整个 Buf 追加到 current_header 中NState = State#scan_state{current_header = <<(State#scan_state.current_header)/binary, Buf/binary>>},get_new_chunk(NState, JobList);{HeaderEndPos, _Length} ->% 找到了header行的"\n",说明header已经全了,要开始构建 body{PreviousHeader, BufLeft} = split_binary(Buf, HeaderEndPos),NState = State#scan_state{current_state = search_header_begin,current_header = <<(State#scan_state.current_header)/binary, PreviousHeader/binary>>},read_and_process_file(BufLeft, NState, JobList)end;search_is_over ->% 文件已经扫描完了case State#scan_state.current_header of<<>> ->AllJobs = JobList;_ ->NewJob = start_revcomp_job(State#scan_state.current_header,State#scan_state.current_body,self()),AllJobs = [NewJob | JobList]end,% 收集进程的处理结果collect_revcomp_jobs(lists:reverse(AllJobs))end.get_new_chunk(State, JobList) ->case file:read(standard_io, ?BUFSIZE) ofeof -> NState = State#scan_state{current_state = search_is_over},read_and_process_file(<<>>, NState, JobList);{ok, Chunk} ->read_and_process_file(Chunk, State, JobList)end.collect_revcomp_jobs([]) ->ok;
collect_revcomp_jobs([Job | Rest]) ->receive{Job, HeaderBuf, RevCompBodyPrint} -> erlang:display(Job),file:write(standard_io, [HeaderBuf, ?NEWLINECHAR, RevCompBodyPrint])end,collect_revcomp_jobs(Rest).start_revcomp_job(HeaderBuf, BodyBufList, Master) ->spawn(fun() -> revcomp_job(HeaderBuf, BodyBufList, Master) end).revcomp_job(HeaderBuf, BodyBufList, Master) ->RevCompBody = << <<(revcomp_a_chunk(ABuf))/binary>> || ABuf <- BodyBufList >>,RevCompBodyPrint = revcomp_chunk_printable(<<>>, RevCompBody),Master ! {self(), HeaderBuf, RevCompBodyPrint}.revcomp_a_chunk(Chunk) ->Complement = << <<(complement(Byte))>> || <<Byte>> <= Chunk, Byte =/= ?NEWLINECHAR >>, % 翻转ComplementBitSize = bit_size(Complement),<<X:ComplementBitSize/integer-little>> = Complement,ReversedComplement = <<X:ComplementBitSize/integer-big>>,ReversedComplement.%list_to_binary(lists:reverse([complement(C) || C <- binary_to_list(Chunk), C=/= ?NEWLINECHAR])).revcomp_chunk_printable(Acc, Rest) when byte_size(Rest) >= ?WIDTH -><<Line:?WIDTH/binary, Rest0/binary>> = Rest,revcomp_chunk_printable(<<Acc/binary, Line/binary, ?NEWLINECHAR>>, Rest0);
revcomp_chunk_printable(Acc, Rest) -><<Acc/binary, Rest/binary, ?NEWLINECHAR>>.complement( $A ) -> $T;
% 同前一个 Erlang 程序,以下省略 complement 的其他子句。这个程序每次从输入文件中读取一块数据,这里设置为 1M 字节。读文件的循环实际上是一个简单的状态机,通过搜索“>”字符和换行符变换状态。初始状态搜索“>”,搜索成功要么说明刚开始处理文件,要么说明已经凑齐了完整的 DNA 序列,于是进入找换行符的状态。因此这个搜索的过程综合起来看只会对输入文件进行一次扫描,而且使用了效率较高的 binary:match/2 函数,几乎相当于线性搜索。此外,由于搜索是针对缓冲块进行的,而不是针对每一行进行的,因此调用这个函数的频率也很低,降低了 binary:match 系列函数的启动开销(binar:match 函数每一次调用的时候都会对 pattern 做一次编译解析,这个启动开销在调用频繁的时候不可忽略)。读文件进程在扫描过程中的状态数据存放在 scan_state 记录中。其中 current_body 部分是一个列表。使用列表的目的是为了避免拼接 binary 产生的额外拷贝开销。
凑齐一段完整的 DNA 序列之后,创建一个工作进程(revcomp_job)处理这个完整的序列。以上读文件的循环传递给工作进程的 DNA 序列中是带换行符的,因此这个程序把换行符的处理从读文件的进程挪到了工作进程。工作进程需要对 current_body 列表中每一项表示的 binary 做反向互补操作。这个反向互补操作就是通过 revcomp_a_chunk 函数进行的。这个函数通过 binary comprehension 操作,从 binary 中逐个取出字节,然后调用 complement 函数计算互补碱基,并填入结果 binary。这个 comprehension 操作会预估好最终 binary 的大小,一次性做好分配,然后直接写入。针对原始数据只会进行一次扫描。计算完互补碱基之后,接下来是一个快速的 binary 翻转操作。这个翻转是从网上找到的[注3],非常巧妙高效,首先将要翻转的 binary 以一个巨大的小尾顺序大整数读入,然后再将其以大尾顺序的方式写入一个新的 binary,那么得到的这个 binary 就是原 binary 翻转后的结果。整个翻转操作是在 ERTS 内部通过 C 语言实现的,效率非常高。
很明显,revcomp_a_chunk 函数就是整个程序的热点所在,通过 profiling 也可以看出这一点。下图展示的是针对一个较小的输入文件的 profiling 结果。在虚拟机中,主要耗时的显然是 process_main 函数了,因为这是虚拟机的引擎函数,整个虚拟机的逻辑都在这里,说明在执行这段程序的时候,有 2.21 秒的 CPU 时间都在运行 Erlang 虚拟机指令。图的右下角的截图是 revcomp_a_chunk 函数中 binary comprehension 部分的虚拟机指令。这些指令是虚拟机加载之后实际执行的指令。可以看出,process_main 的 stack trace 中耗时最多的两个函数分别对应了其中的两条指令。也就是说,在 process_main 函数耗费的 2.210 秒中,有 0.303 秒中耗费在实现 i_bs_private_append_jId 指令的 erts_bs_private_append 函数,还有 0.280 秒的 CPU 时间用在实现 i_new_bs_put_integer_imm_jIIs 指令的 erts_new_bs_put_integer 函数。根据这篇博文的介绍,这两条指令中的前一条的作用是维护可写 binary 数据结构,后一条的作用是填入数据。
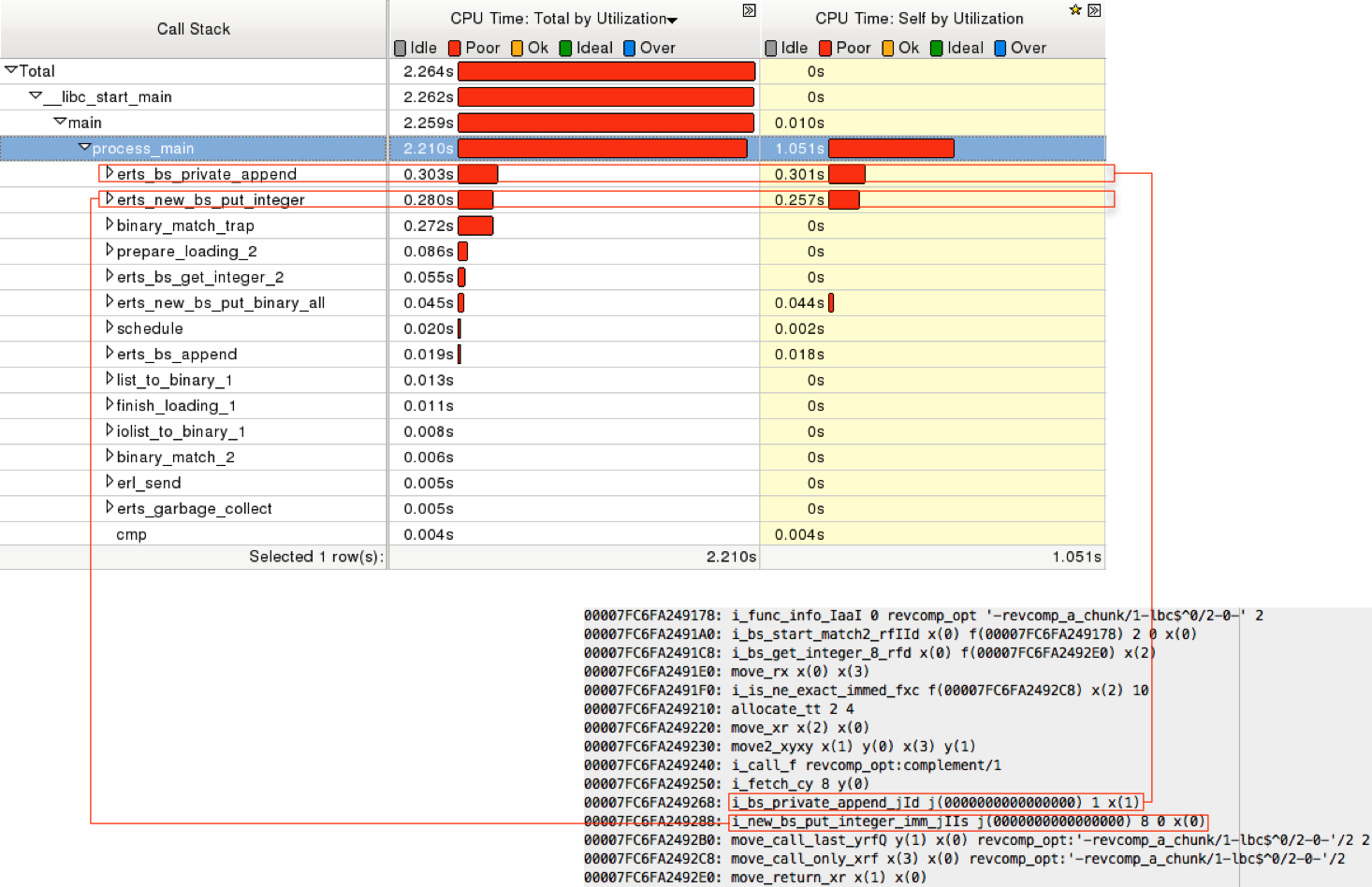
从图中还可以看出,有 1.051 秒的 CPU 时间耗在 process_main() 函数本身的语句,所以我们深入 process_main() 看一下里面耗时的语句有哪些。下图根据语句的耗时对语句进行了排序。明显可以看出,那些耗时很多的语句都和 binary comprehension 生成的这个大循环中的指令有关系。

从上面的两张图可以看出,这些开销都是省不掉的了。因为 Erlang 作为一种通用的语言,其提供的数据结构具有一定的通用性,所以很难做到针对某一个任务特别优化。比如说我们这个例子中循环操纵一个缓冲区中每一个字节并写入另外一个缓冲区的操作,就需要通过上面这些虚拟机指令来实现:读取一个字节,需要通过 i_bs_get_integer_8_rfd 指令,写入一个字节需要 i_bs_private_append_jId 和 i_new_bs_put_integer_imm_jIIs 两条指令来实现,而这些指令实现的是通用的取值和写值的操作,因此指令本身的实现涉及到很多函数调用、参数检查和数据结构维护的操作,这必然比纯 C 语言的字节拷贝要慢多了。而且虚拟机指令跳转本身也是有很大开销的,从上图中的 Goto 语句和一些 NextPF 语句就可以看出来。
那么碰到这种任务应该怎么办呢?解决方法就是,我们不要被语言所束缚,该用 C 语言的地方还是用 C 语言吧,发挥各种语言自身的优势,而不要用一种语言的弱点去和另一种语言的强项作比较,有得必有失。Erlang 也是很体贴地提供了诸如 NIF 机制让我们可以用 C 语言实现一些只有 C 语言才能高效完成的任务。比如说在这个程序中,用 C 语言来实现 revcomp_a_chunk 函数就是很好的选择。
本文到这里应该结束了,不过下面我还要啰嗦一些关于 Erlang 有意思的地方。我们刚才提到,虚拟机指令分发本身也是高开销的操作,因为指令分发意味着跳转,而 CPU 最擅长的是顺序执行,跳转会破坏 CPU 分支预测的优化,因此很多语言虚拟机的一大优化就是尽量减少指令的分发,也就是尽可能地在一条指令中执行更多的任务。比如说下面的图还是以 binary comprehension 的那一段为例,左侧是 beam 汇编码,这是编译器从原始码直接生成的,右侧是虚拟机加载优化之后实际运行的指令:
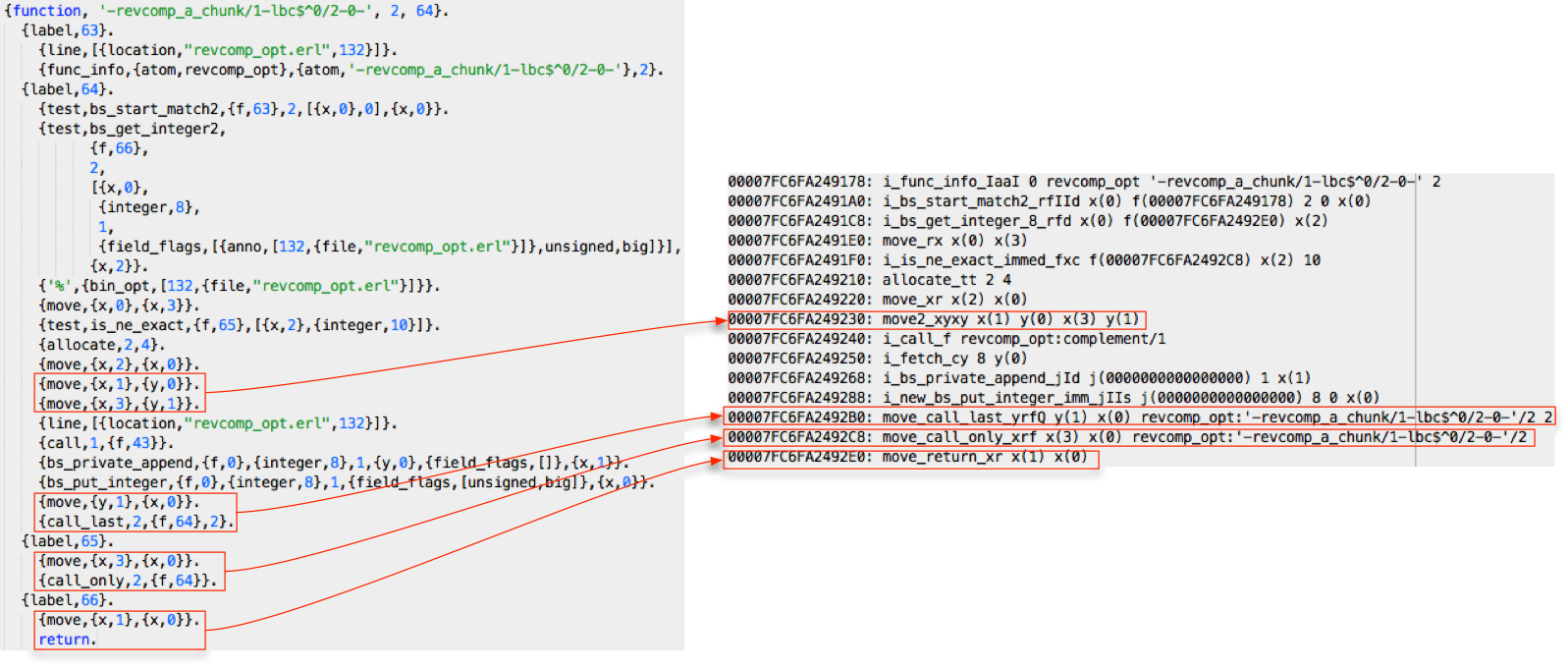
从图中可以看出,左侧有一些常见的指令组合在右侧被优化为一条指令了,可以在一定程度上减少指令分发。
另外,关于 complement 函数,这个函数有 32 个子句,实际上实现了一个映射关系,那么 Erlang 会怎么处理这个函数呢?显然也是有大大的优化滴。放心,我们聪明的 Erlang 不会笨笨地每一次调用的时候都顺序查找这 32 条子句。先看一下编译器生成的 complement 汇编码:
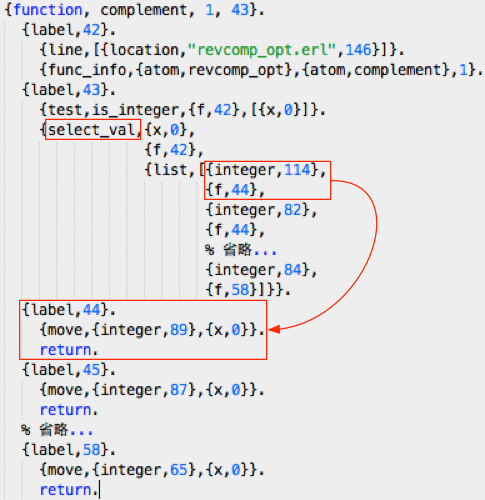
可以看出,调用这个函数的时候,主要起作用的是 select_val 指令,这条指令根据输入值,选择一个跳转标签,比如输入 114(即“r”的 ASCII码),跳转到标签 44 的位置,可以看到在标签 44 处返回了整数 89,即“Y”对应的 ASCII 码。
如果我们查看 process_main() 函数对 select_val 的实现,会发现这条指令的实现采用了二分搜索,因此比线性搜索要快。但是 Erlang 就满足于此了吗?再看看虚拟机加载之后生成的实际指令:
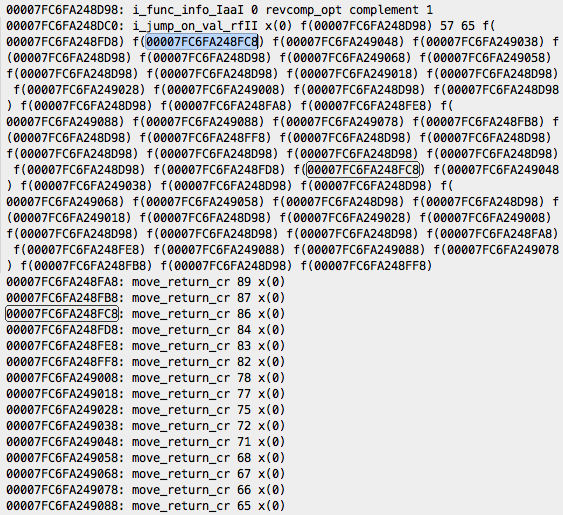
怎么样?厉害吧!加载器把 select_val 给替换掉了,生成了一条更快速的指令 i_jump_on_val_rfII,这条指令的参数是一个跳转表,通过输入参数可以直接得到跳转表中的索引,从而得到跳转地址。这一下我们再也不用担心 complement 的效率了,这种函数会被优化为常量时间,实际上已经可以匹配本文开头提到的 C 语言程序采用的查找表的算法了。
当然,熟悉编译的同学可能会觉得这些都是编译领域中常用的优化技术,不过作为编译领域的外行,我还是觉得 Erlang 在编译器和虚拟机的配合优化上下了很大的功夫。
[注1] The Computer Language Benchmarks Game http://benchmarksgame.alioth.debian.org/
[注2] http://benchmarksgame.alioth.debian.org/u64/benchmark.php?test=revcomp&lang=all&data=u64
[注3] http://sifumoraga.blogspot.com/2010/12/reversing-binary-object-in-erlang.html
分类: Erlang,Erlang运行时代码分析
标签: Erlang, binary, optimization
好文要顶 关注我 收藏该文 ![]()


siyao
关注 - 0
粉丝 - 82
+加关注
5
0
« 上一篇:Profile 分析 Erlang 虚拟机源码时要注意的一个问题
» 下一篇:Erlang 程序引发共享内存 bug 的一个例子
posted @ 2013-12-22 16:51 siyao 阅读(6637) 评论(4) 编辑 收藏
评论列表
#1楼 2014-02-16 00:19 BigDataForFuture
这语言的应用层面是?
支持(0)反对(0)
@ gunnima
它现在是一个强大的软实时“应用系统”,是个系统
支持(0)反对(0)
请问那个CPU图形工具是什么啊
支持(0)反对(0)
#4楼[楼主] 2014-08-20 14:56 siyao
@ Mark_H
Intel VTune
支持(0)反对(0)
这篇关于为什么Erlang比C慢那么多倍?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![Erlang程序设计[Part1-Part2 chapter4]](https://img-blog.csdnimg.cn/direct/2603216fb88b4b808fa7766a56d4d5da.png)

