本文主要是介绍2022.06.30机器学习-数据科学库(HM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01pandas的Series的了解
Series 一维,带标签数组
DataFrame 二维,Series容器
pandas之Series创建
import sring
t = pd.Series(np.arange(10),index=list(string.ascii_uppercase[:10]))pandas之Series切片和索引

切片:直接传入start end 即可
索引:一个的时候直接传入序号或index,多个的时候传入序号或者index列表
pandas之Series索引和值

02pandas读取外部数据
pd.read_csv
pd.read_sql(sql_sentence,connection) 读取mysql数据库的数据
03pandas的dataFrame的创建
t=pd.DataFrame(np.arange(12).reshape((3,4)))
04Dataframe的描述信息
 pandas之取行或取列
pandas之取行或取列

pandas之loc


pandas之iloc

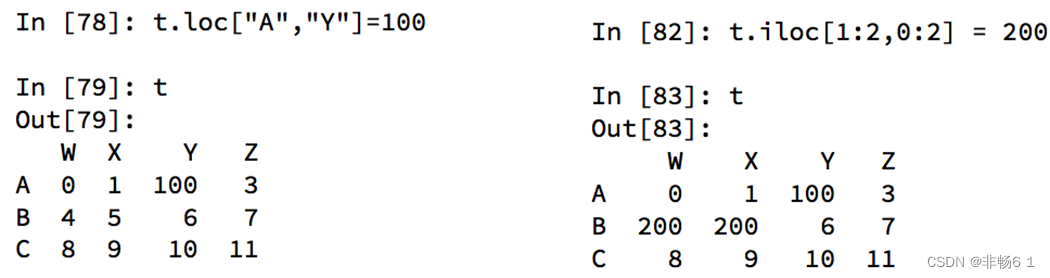
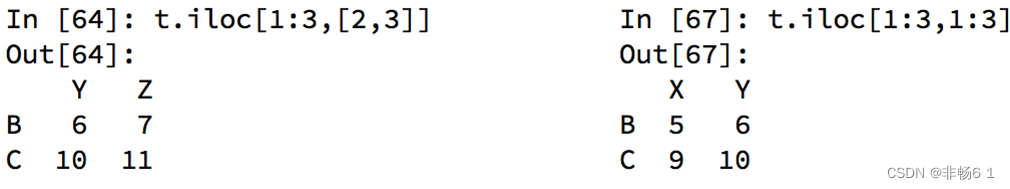 赋值更改数据的过程
赋值更改数据的过程
pandas之bool索引
这篇关于2022.06.30机器学习-数据科学库(HM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





