本文主要是介绍MINIST数据集测试不同参数对网络的影响,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一.介绍
- 1.实验环境
- 2.网络结构
- 二.网络效果
- 1.初始状态
- 2.有BN层
- 3.激活函数
- tanh
- sigmoid
- relu
- 4. 正则化
- L2正则化
- Dropout
- 5.优化器
- 6. 学习率衰减
- 三.最优测试
- 附: 完整代码
一.介绍
本实验使用两个不同的神经网络,通过MINIST数据集进行训练,查看不同情况下最后的效果。
1.实验环境
- Python 3.8
- Pytorch 1.8
- Pycharm
2.网络结构
单层卷积:一层卷积+一层池化+两层全连接
class Net_1(nn.Module):def __init__(self):super(Net_1, self).__init__()self.model = nn.Sequential(nn.Conv2d(1,10,kernel_size=3,stride=1),#nn.BatchNorm2d(10),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),nn.Flatten(),nn.Linear(10*13*13, 120),nn.ReLU(),#nn.Dropout(p=0.5),nn.Linear(120, 10),)def forward(self,x):return self.model(x)多层网络:三层卷积+三层池化+两层全连接
class Net_2(nn.Module):def __init__(self):super(Net_2, self).__init__()self.model = nn.Sequential(# out-> [40,28,28]nn.Conv2d(1, 40, kernel_size=3, stride=1,padding=1),#nn.BatchNorm2d(40),nn.ReLU(),# out->[40,14,14]nn.MaxPool2d(kernel_size=2, stride=2),# out->[20,12,12]nn.Conv2d(40, 20, kernel_size=3, stride=1),#nn.BatchNorm2d(20),nn.ReLU(),# out->[20,6,6]nn.MaxPool2d(kernel_size=2, stride=2),# out->[20,4,4]nn.Conv2d(20, 20, kernel_size=3, stride=1),#nn.BatchNorm2d(20),nn.ReLU(),# out->[20,2,2]nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(2 * 2 * 20, 100),nn.ReLU(),#nn.Dropout(p=0.5),nn.Linear(100, 10),)def forward(self, x):return self.model(x)二.网络效果
1.初始状态
Batchsize :200
Learning_rate:0.001
Epochs:15
优化器:torch.optim.SGD
损失函数:nn.CrossEntropyLoss()
激活函数:Relu
以下变更均建立在此基础之上
单层网络效果:
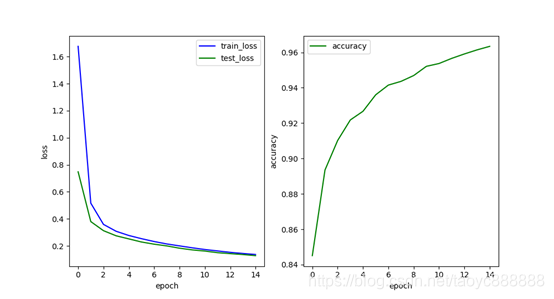
多层网络效果:
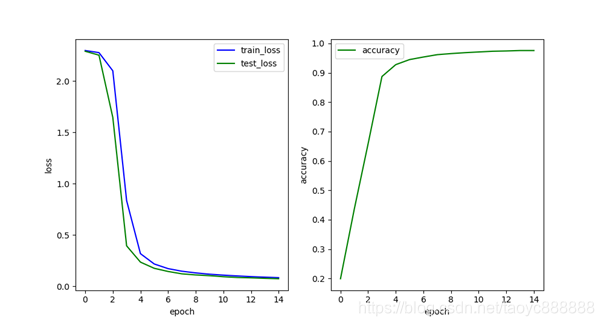
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.136 | 0.128 | 0.9634 |
| 多层网络 | 0.090 | 0.080 | 0.9734 |
2.有BN层
单层网络效果:
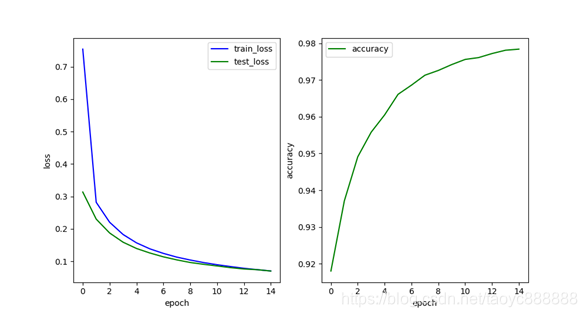
多层网络效果:
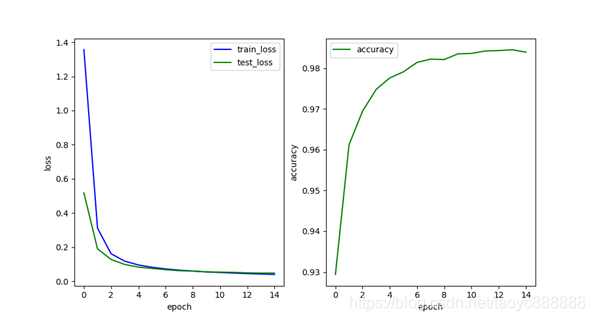
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.070 | 0.069 | 0.9784 |
| 多层网络 | 0.040 | 0.048 | 0.9839 |
添加BN层结果有所好转
3.激活函数
tanh
单层网络效果:
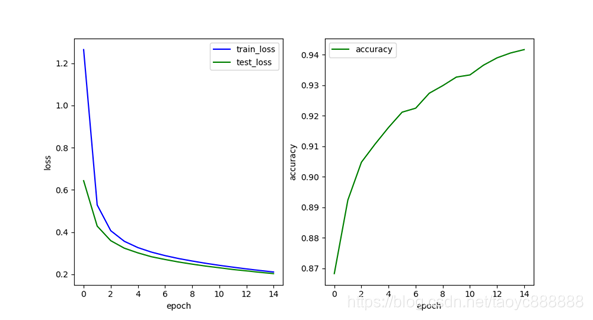
多层网络效果:
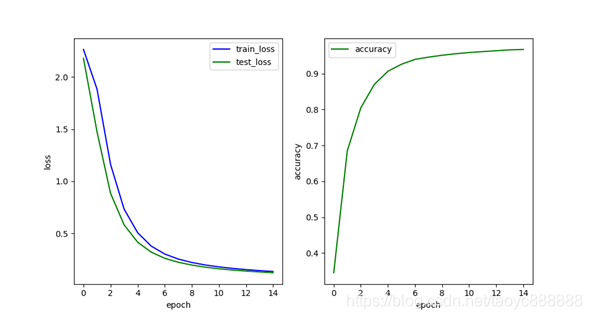
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.210 | 0.202 | 0.9417 |
| 多层网络 | 0.135 | 0.122 | 0.9675 |
单层多层的表现都不如relu,比较接近
sigmoid
单层网络效果:
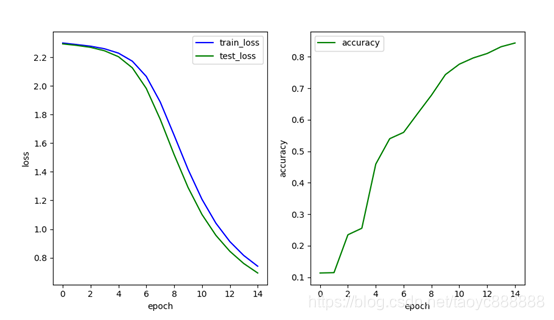
多层网络效果:
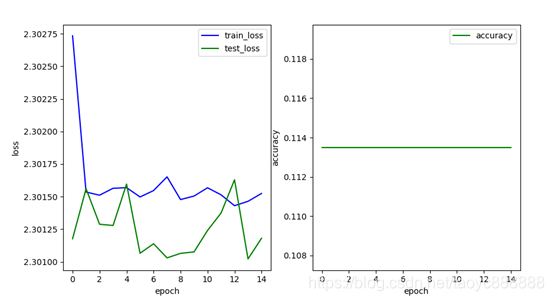
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.740 | 0.693 | 0.8436 |
| 多层网络 | 2.301 | 2.301 | 0.1135 |
relu
单层网络效果:
多层网络效果:
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.136 | 0.128 | 0.9634 |
| 多层网络 | 0.090 | 0.080 | 0.9734 |
4. 正则化
L2正则化
optimizer=optim.SGD(model.parameters(),lr=learning_rate,momentum=0.9,weight_decay=0.001)
weight_decay设置为0.001
单层网络效果:
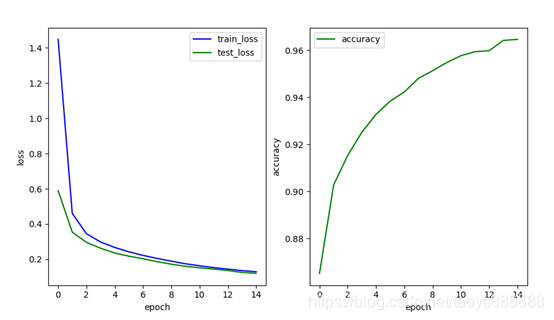
多层网络效果:
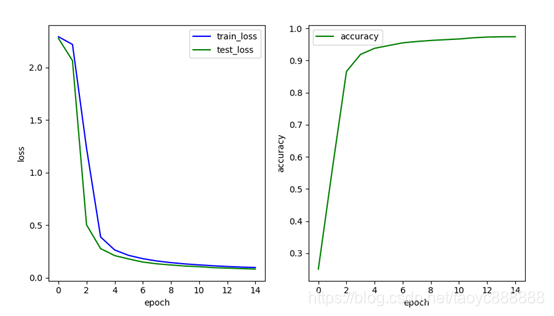
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.129 | 0.120 | 0.9646 |
| 多层网络 | 0.096 | 0.081 | 0.974 |
Dropout
nn.Dropout(p=0.5)
单层网络效果:
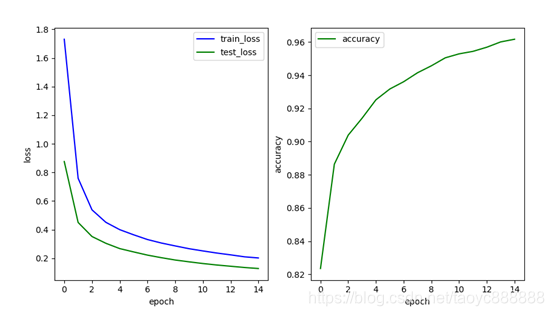
多层网络效果:
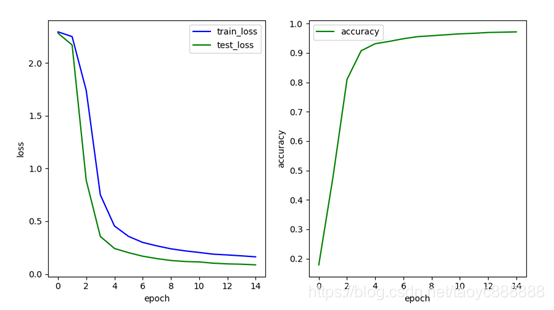
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.201 | 0.128 | 0.9617 |
| 多层网络 | 0.162 | 0.086 | 0.9718 |
5.优化器
将SGD优化器变更为Adam优化器
单层网络效果:
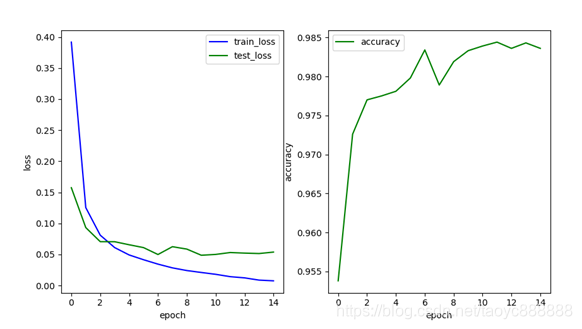
多层网络效果:

最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.007 | 0.053 | 0.9836 |
| 多层网络 | 0.020 | 0.034 | 0.9889 |
6. 学习率衰减
scheduler_step = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.2)此处使用Adam优化器,weight_decay为0.001,添加BN层,Dropout层,使用Relu函数
单层网络效果:
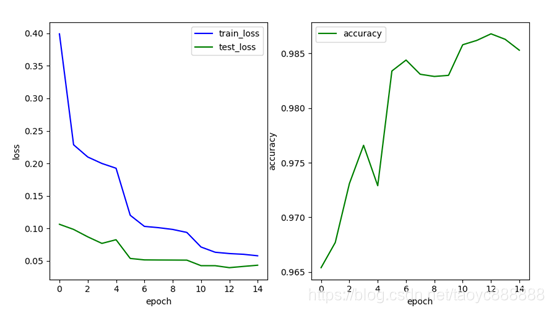
多层网络效果:
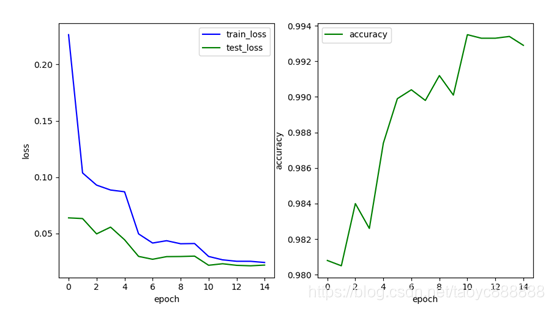
最后一次的结果:
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 单层网络 | 0.058 | 0.043 | 0.9853 |
| 多层网络 | 0.024 | 0.022 | 0.9929 |
三.最优测试
Batchsize :200
Learning_rate:0.01
Epochs:15
优化器:torch.optim.Adam,weight_decay为0.001
学习率衰减:step_size=2, gamma=0.2
损失函数:nn.CrossEntropyLoss()
激活函数:Relu
添加BN,dropout层
多层网络效果:
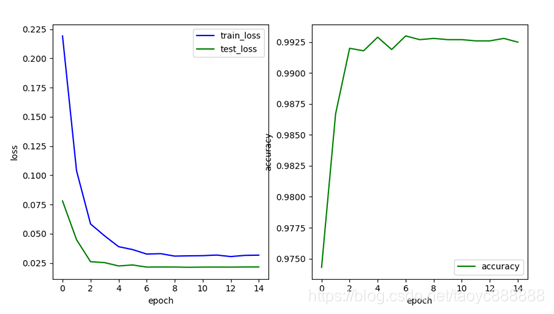
| train_loss | test_loss | accuracy | |
|---|---|---|---|
| 多层网络 | 0.031 | 0.021 | 0.9925 |
附: 完整代码
import matplotlib.pyplot as plt
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, optimdef main():batch_size = 200learning_rate = 0.01epochs = 50train_loader = DataLoader(datasets.MNIST('MNIST', train=True, download=True, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.5, 0.5)])),batch_size=batch_size,shuffle=True)test_loader = DataLoader(datasets.MNIST('MNIST', train=False, download=True, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.5, 0.5)])),batch_size=batch_size,shuffle=True)device = torch.device('cuda')model = Net_2().to(device)criteon = nn.CrossEntropyLoss().to(device)optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0.001)scheduler_step = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.2)train_loss = []test_loss = []acc = []for epoch in range(epochs):loss_1 = 0.loss_2 = 0.model.train()for i, (x, label) in enumerate(train_loader):x, label = x.to(device), label.to(device)out = model(x)loss = criteon(out, label)optimizer.zero_grad()loss.backward()optimizer.step()loss_1 += loss.item()scheduler_step.step()loss_1 = loss_1 / (i + 1)train_loss.append(loss_1)print('train: 第{}次,loss为{}'.format(epoch, loss_1))model.eval()with torch.no_grad():correct = 0.for i, (x, label) in enumerate(test_loader):x, label = x.to(device), label.to(device)out = model(x)loss = criteon(out, label)pred = out.argmax(dim=1)correct += torch.eq(pred, label).sum().item()loss_2 += loss.item()accuracy = correct / len(test_loader.dataset)loss_2 = loss_2 / (i + 1)test_loss.append(loss_2)acc.append(accuracy)print('test: 第{}次,loss为{},accuracy为{}'.format(epoch, loss_2, accuracy))plt.figure(num=1, figsize=(10, 5.4))plt.subplot(121)# plt.title("loss")plt.plot(train_loss, 'b-', label='train_loss')plt.plot(test_loss, 'g-', label='test_loss')plt.xlabel('epoch')plt.ylabel('loss')plt.legend()plt.subplot(122)plt.plot(acc, 'g-', label='accuracy')plt.xlabel('epoch')plt.ylabel('accuracy')plt.legend()plt.show()if __name__ == '__main__':main()
这篇关于MINIST数据集测试不同参数对网络的影响的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





