本文主要是介绍基于深度学习的口罩人脸识别研究进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MTCNN模型训练输入的所有图像都是正样本(戴口罩的照片),没有负样本作为模型输入。在后续的识别任务模块中,导入MTCNN模型检测结果,对特征点进行编码比较进行识别。
基于MTCNN的口罩人脸识别框架可分为四个阶段:
人脸检测;面部与面罩对齐;带面具的人脸编码;戴口罩人脸对应的身份识别。
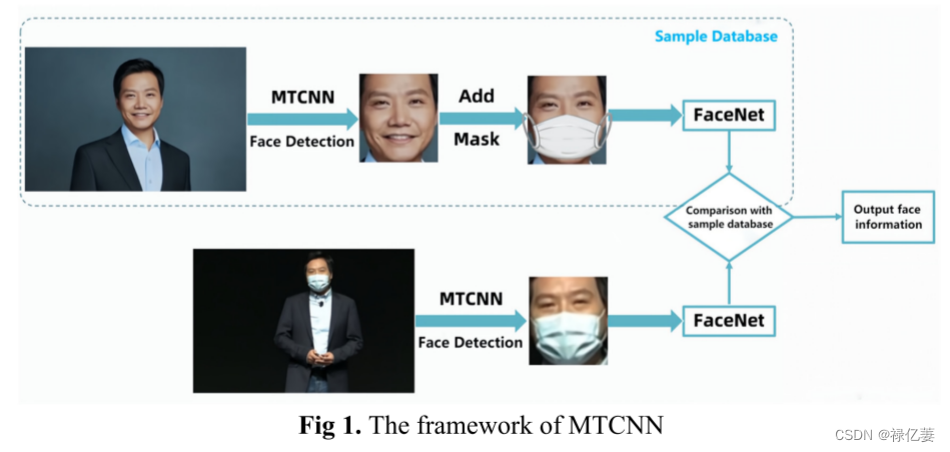
如图1所示,在训练过程中,同一目标首先需要两组输入图像(未遮蔽的人脸图像和遮蔽的人脸图像)。机器自动为未蒙版图像添加蒙版,然后将其放入样本库中与蒙版图像进行特征比较。
这个过程分为两条链:
第一条链是首先使用MTCNN技术的三个子网络并从粗到精地提取人脸部分,然后使用MobileNet组件进行掩模检测。如果发现输入是原始图像(无掩模),则在口鼻特征点区域添加掩模,并将处理后的“掩模人脸图像”输入到识别样本数据库中。
第二条链是MTCNN的级联校正。将采集到的蒙版人脸图像裁剪为与初始样本库相同的像素大小。然后并行将两个链接添加到样本库中,进行比较(将自动处理的蒙版人脸与原始蒙版人脸进行比较)来预测最终的人脸信息。
在创建识别样本数据库时收集未遮蔽的人脸图像,在执行识别时收集遮蔽的人脸图像。之后,将遮罩添加到未遮罩的人脸图像中,然后将遮罩的人脸与手动处理的遮罩人脸和收集的遮罩人脸进行比较。最后输出该人的身份信息。
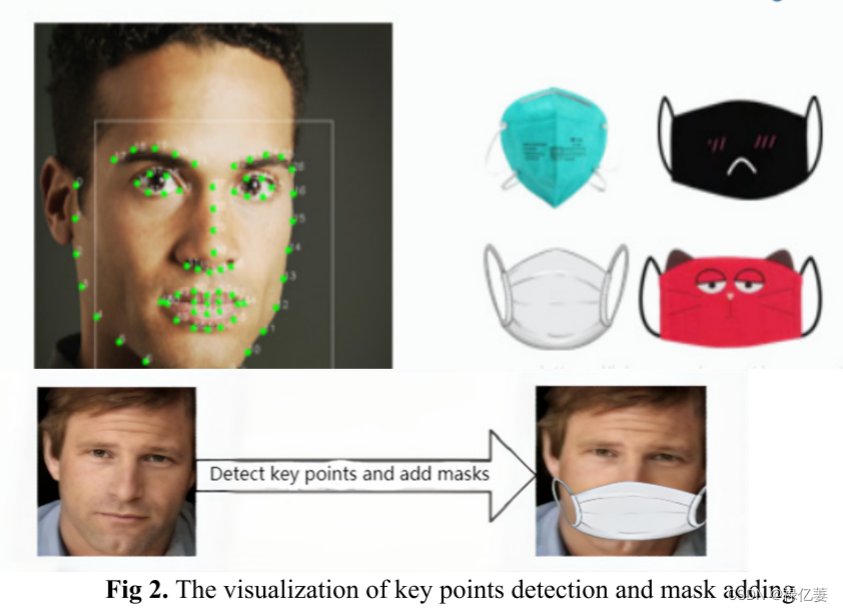
对于MTCNN网络,简单调整P/R/O-Net的阈值。三个阈值控制裁剪框输出高精度的面部信息。Faceplus-mask程序主要应用脸部的68个关键点。如图2所示,为人脸添加蒙版的主要部分如下:
(1)搜索面部68个关键点。
(2)确定人的鼻子和面部轮廓。
(3)根据面部轮廓确定面部左侧点、面部下侧点和面部右侧点。
(4)从鼻子到面部底点的高度、口罩尺寸中心线确定。
(5)将口罩左右均匀分开;使用最左侧面部点与中心轴之间的距离作为宽度来调整蒙版左侧的大小。调整右蒙版,宽度为面部右侧点到中心轴的距离。将左蒙版和右蒙版合并为一个新蒙版。
(6) 以中心轴相对于Y轴的旋转角度调整并旋转新的掩模,最终将掩模放置在图像上的适当位置。
最后基于FaceNet开源模块对两组数据进行对比识别。
1 蒙面人脸检测部分
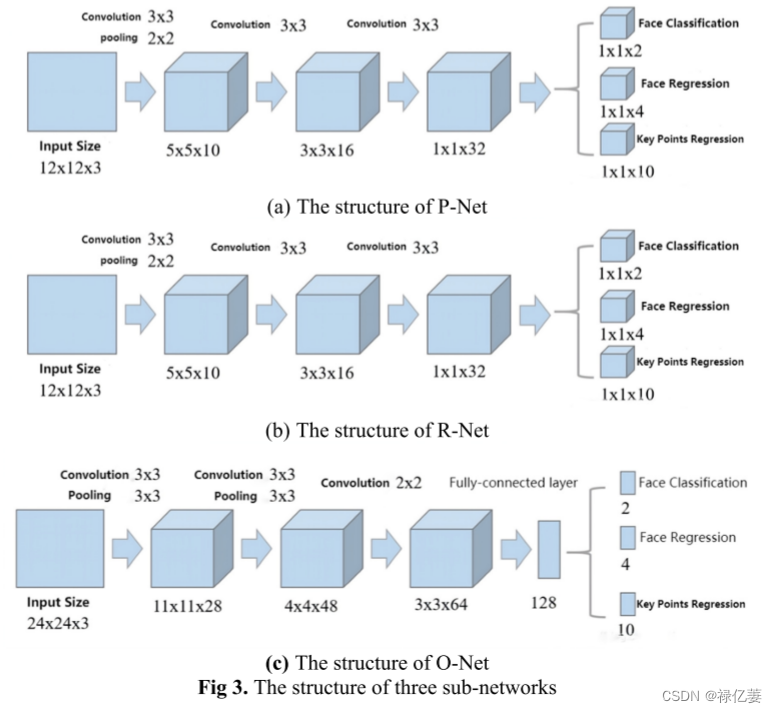
正样本图片(戴口罩的人脸图片)的输入样本库使用统一尺寸的图片,因为获取的图片中可能存在手臂、肩膀等身体部位,这对于训练来说可能会产生较多的噪声,MTCNN方法是用于裁剪蒙版图片的人脸区域;而MTCNN,是一种多任务卷积神经网络,其网络模型,主要通过三个级联网络进行人脸分框,即P/R/O-Net。
(1)P-net用于快速生成面部拦截窗口。执行过程如下:对输入特征进行三层卷积后,利用人脸分类器、边界回归和人脸关键点定位来初步选择人脸区域。然后,P-Net 的主要选择将被馈送到 R-Net 进行下一步。
(2)R-Net 用于以更精细的方式过滤从上一步截取的面部区域。其过程是:将P-Net得到的所有候选窗口输入R-Net,淘汰较少的有效候选窗口,通过边缘回归和非极大值抑制得到进一步的预测窗口。
(3)O-Net的作用是生成最终的识别边界和人脸的关键点。运行过程与R-Net类似,但增加了人脸特征点位置的回归预测。最后输出人脸的5个人脸特征点。
2 佩戴口罩时的面部对准部分
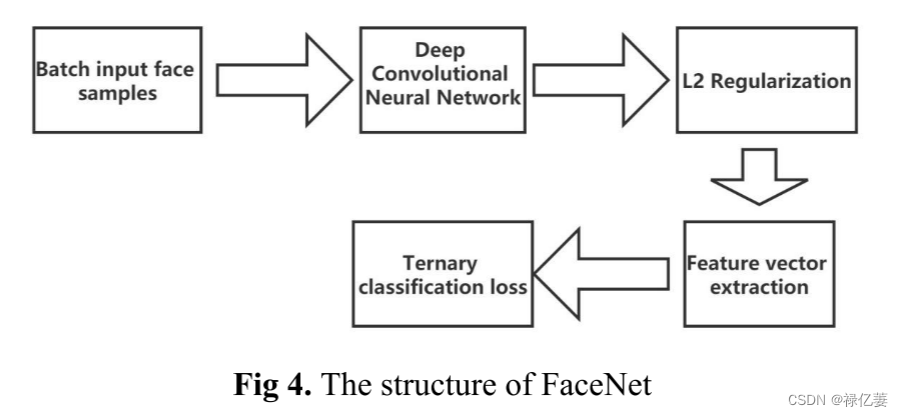
主要调用“Dlib”开源库提取128个特征点,输入戴口罩的人脸图片,针对鼻子和嘴巴两个部位,在口罩遮盖下,模型自动补足特征点人脸特征点提取;深度学习部分采用Face-net模型。该模型通过提取其中一层作为特征来学习从图像到欧几里得空间的编码方法。该算法主要直接应用已建立的CNN模型(例如GoogleNet等)并在此基础上改变损失函数,以方便将人脸图像映射到高层空间层次结构。利用损失函数来优化人脸之间的欧氏距离,使得同一个人的人脸图片的误差距离最小,不同人的人脸图片的误差距离最大。根据获取的特征向量,计算“欧氏距离”进行人脸识别。网络结构如图4所示。经过这一步,人脸缺失的特征点将被填充并参与识别。
3 佩戴口罩人脸编码部分
获取人脸128个点的特征编码,并根据人脸编码信息矩阵计算不同人脸之间的距离。
4 佩戴口罩的人脸识别部分
所有计算距离的方法都安排好之后,就进行最后一步的人脸识别。计算数据库中的人脸数据,将信息编码后的图片存入已知人脸信息列表中。

这篇关于基于深度学习的口罩人脸识别研究进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




