本文主要是介绍存储成本仅为OpenTSDB的1/10,TDengine的最大杀手锏是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在《这几个神秘参数,教你TDengine集群的正确使用方式》中,我们告诉了大家:如何才能让数据均匀的分布在节点中。接下来,我们和大家一起以产品使用者的视角继续向前探索。
如果说让数据均匀分布的目的是为了最大化地使用CPU资源的话,那么充分地利用数据压缩能力就是为了最大化地驾驭存储资源了。
我只能说,在这个方面TDengine做得棒极了。
在官网上,有这样的描述:
TDengine 相对于通用数据库,有超高的压缩比,在绝大多数场景下,TDengine 的压缩比不会低于 5 倍,有的场合,压缩比可达到 10 倍以上。
下面就是TDengine在最近三个月内打出的成绩。
在顺丰科技的应用案例中,TDengine轻松替换掉了OpenTSDB+HBase:
服务端物理机由21台降至3台,每日所需存储空间为93G(2副本),同等副本下仅为OpenTSDB+HBase的约1/10,在降低成本方面相对通用性大数据平台有非常大的优势。
在得物APP的应用案例中,TDengine通过10%的压缩率为对方节约了大量存储资源:
目前Sentinel的数据没有使用副本,全量数据分散在三台机器中,根据计算得知TDengine对于Sentinel监控数据的压缩率达10%,相当可观。
一是开源产品免费,二是能白白给自己省下那么多服务器,三是读写性能都不错——这种降本增效的工具谁不喜欢呢。
于是一些用户开始安装产品,并开始使用官方推荐的压测工具taosdemo造数写入,想看看是不是真的可以做到宣传的效果。
但是测试过后,很多用户感觉TDengine的压缩率并没有达到自己的预期。可另一方面,顺丰和得物这些大企业又实实在在地得到了非常可观的成本降低,那么问题到底出在哪里呢?
大家都知道IoT数据的特点之一就是,对于同一监测量而言,相互之间相差小且有规律,即便是字符型也会有相当大数据重复出现或者类似的可能。正是这样的数据模型才给了TDengine的列式压缩广阔的发挥空间。
但是呢,如果仅以taosdemo默认配置的随机数据来做测试,生成的数据未必具有这样的特点。比如,默认的配置有一个长度为16的nchar字符类型,每个 nchar 字符占用 4 bytes 的存储空间4*16占据了几乎一半的行长度又不好压缩,所以就显得压缩效率有点低。
为了优化这个体验,在2.1版本的taosdemo里默认的写入数据换成了四列INT。但如果大家想写入自定义格式的数据,只要根据这个博客操作就好了。
TDengine taosdemo工具使用指南
那么回到真实生产环境上,又会是什么情况呢。换言之,TDengine到底是如何帮助顺丰与得物这样的独角兽企业降低存储成本的呢?
接下来,我们就来看看——什么叫赢在起跑线上:超级表建表语句和普通表建表语句的区别就只在这一个地方——Tag(标签)。超级表多了它就可以管理百万千万级别的子表,充分地说明了它的重要性。

正是因为TDengine把每个设备的标签都提取出来放在了内存里,所以才让设备的裸数据量天生就少了很多。所以,如果你想测试一样的业务场景下的性能时,在生成数据的那一刻你就会发现TDengine已经赢了。因为想要营造出一样的场景,它根本不需要造出那么多数据。
假设一个设备光是标签数就和测点数差不多甚至更多的时候,那在原始数据上你就可能已经省下了至少一半的磁盘占用。
接下来,我们来看看TDengine的数据压缩流程:当数据写入内存的时候,为了防止断电等特殊情况带来的数据丢失,TDengine会把数据先写入wal(write ahead log)文件。
当落盘机制被触发,数据开始持久化到存储之前,COMP参数就开始生效了。根据这个参数的值(0 1 2),TDengine会分别选择是做不压缩,一阶段压缩,还是二阶段压缩:一阶段压缩会根据数据的类型进行了相应的列压缩,压缩算法包括delta-delta编码、simple 8B方法、zig-zag编码、LZ4等算法。所以,总结一下:
- 1.对于特定列有特定算法的针对性压缩
- 2.物联网场景下数据的普遍规律性
这两点共同造就了TDengine超强的压缩能力。
接下来,二阶段压缩又在一阶段压缩的基础上用通用压缩算法进行了压缩,压缩效果更高。关于TDengine压缩算法的说明见如下链接。
https://github.com/taosdata/TDengine/blob/master/src/util/src/tcompression.c
最后,我们再来看看,到底要如何估算出压缩率:
首先,我们要算出裸数据的大小,官网上提供的计算公式为:
Raw DataSize = numOfTables * rowSizePerTable * rowsPerTablerowSizePerTable(每行长度)可以根据每个数据类型的长度来计算。describe table你会看到表的结构以及各个字段的大小。其中binary和nchar类的长度为最大长度。实际占用要以真实数据长度为准(下面示范中binary和nachar占满全部空间),而nchar字段的占用长度还要乘4。此外,每个binary和nchar还要额外占据两个字节。
比如下表:
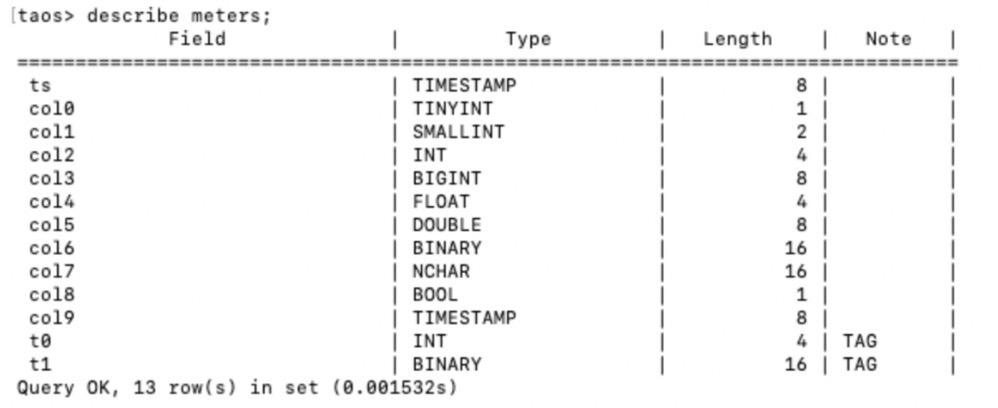
在假设Binary和Nchar数据都是写满16个的情况下,单行总长度就是(8+1+2+4+8+4+8+16+16*4+1+8)+4=128字节。用128字节乘以 rowsPerTable(每个表行数)*numOfTables(表数),就可以大体地估算出我们的总数据量了。
其实,测试中更常见的是直接用超级表作为测试主体,直接使用超级表的count(*)数据去乘以每行长度就可以得到Raw DataSize了。
最后,再用/var/lib/taos/vnode/下面各个vnode的数据文件大小除以Raw DataSize。
大功告成——我们终于得出实际压缩率了。这里,大家要留意一下:在数据文件目录下的vnode目录里面还有一个wal目录。如果这里面有数据说明数据还没有落盘到存储里面,也就是说数据是还没有压缩过的。为了让测试结果更加精准,所以大家可以使用最简单直接的办法——重启服务进程,这样就可以直接触发落盘机制了。
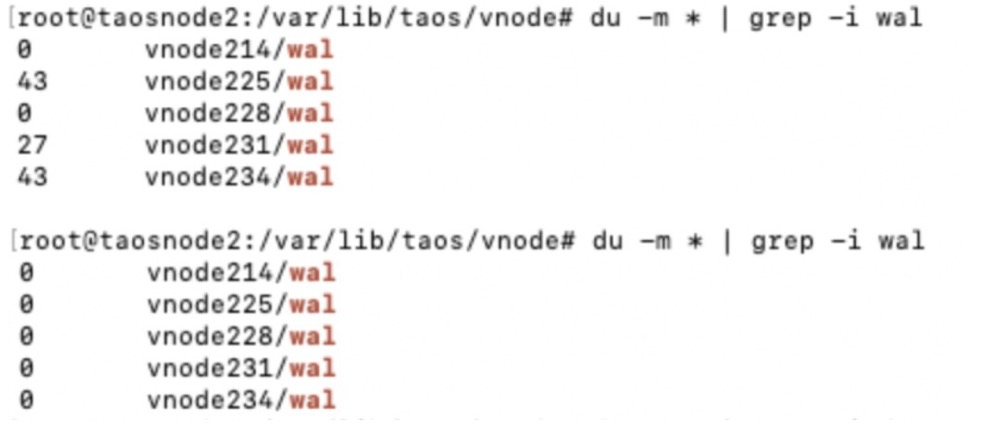
上图显示:重启过后,所有的wal文件大小都是0,证明数据已经成功被压缩后写入存储了。

本次TDengine之旅,终于到此告一段落。
其实,测试压缩率最好的办法就是在合理的数据建模之后,用自己的真实数据试去跑一下,这时候就一目了然了。
以上,就是TDengine降低存储成本的最大杀手锏。
点击这里,体验TDengine!
这篇关于存储成本仅为OpenTSDB的1/10,TDengine的最大杀手锏是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




