本文主要是介绍PointNet++GPD<论文>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
尽管在单个已知物体和结构化环境中的抓取技术研究取得了重大进展和应用,传统的机器人抓取技术在复杂环境中无法很好地解决这一挑战,这些复杂环境往往是多个未知物体,杂乱不堪,并且包含真实环境中的光线和物体遮挡,但凭借深度学习强大的知识迁移和非线性拟合能力,它为解决这一问题提供了可能性。
除了用于抓取特定物体的人类设定轨迹外,传统的机器人抓取技术还需要对非结构化环境进行姿态估计来规划物体的抓取,而基于深度学习的视觉抓取技术可以直接预测抓取姿态,而无需对物体进行姿态估计,这大大降低了系统的复杂性[1]。
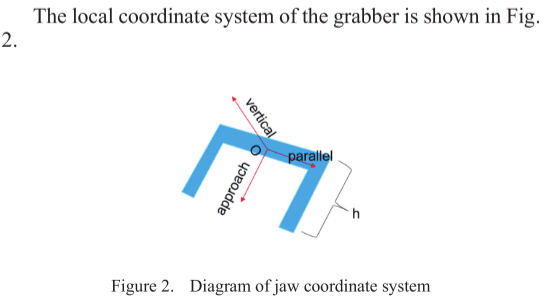
要抓取物体,机器人需要根据物体的位置驱动抓取器(三维坐标和三维方向),因此在机器人抓取功能的实现规划中,最重要的是获得抓取器的姿态[2]。它可以分为二维平面抓取和六自由度抓取。在二维平面抓取方法中,抓取器只能在一个方向上抓取物体[3][4]。由于抓取器到物体的高度是确定的,因此6D抓取器姿势被简化为3D,只需要2D平面内位置和1D旋转角度即可表达抓取姿势[5]。然而,抓取器也失去了抓取物体的灵活性,它只适用于只包含简单物体而不考虑几何信息且不包含多个物体的场景。在6自由度抓取时,抓取器可以从不同角度抓取物体,与二维平面抓取相比,这种方法更适合于多个物体的复杂环境。
在计算机视觉领域,PointNet[6]被广泛用于解决三维点云数据的分类和分割问题,梁等人设计了基于PointNet的PointNetGPD[7]抓取姿态检测模型,但由于PointNet不能获得局部特征的缺点,该模块在抓取姿态质量评估中的准确性较低。PointNet[8]模型借用了CNN感知场的思想,通过多层网络结构获得了更深层次的特征,在分类和分割问题上都优于PointNet模型。
为了提高抓取检测模型生成抓取姿态的准确性和可靠性,本文提出了一种基于PointNet的端到端抓取姿态检测网络,并基于BigBIRD数据集[9]生成了700k个真实点云和抓取标签的数据集来训练模型,实验结果表明,该模型比测试集中的PointNetGPD和GPD具有更高的分类精度,在多目标密集环境中的抓取性能也优于这两种模型。
2.本文结构
本文的模型架构如图1所示,主要由两个模块组成:一是候选抓取姿态生成模块;另一个是抓取姿态质量评估模块。
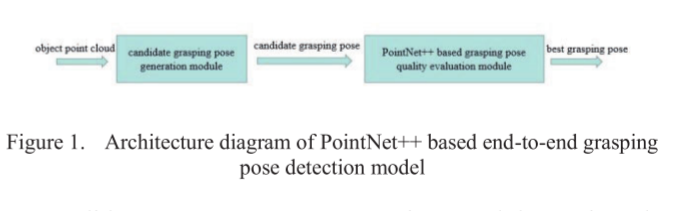
候选捕捉姿态生成模块:以相机获取的物点云为输入,采用GPG[11]方法生成候选捕捉姿态。抓握姿势质量评估模块:基于PointNet网络,我们设计了一个分类网络来评估候选抓握姿势作为输入,并得到抓握姿势的类别(正或负),以过滤出可靠的抓握姿势。
3.候选抓取的生成
当从深度相机获得目标物体信息并且已知抓取器的几何信息时,候选抓取姿态生成模块需要从点云生成候选抓取姿态,作为抓取姿态质量评估模块的输入。


4.生成抓取
在本文中,我们从BigBIRD数据集中基于35个对象生成700k抓取姿态质量分数标签,以训练本文提出的基于PointNet的抓取姿态可行性评估网络,该网络需要两个步骤:a.为对象点云生成抓取姿态;b.用抓握质量分数标记抓握姿势。
A.基于对象的点云抓取姿势的生成
对于每个抓取姿势的生成,在BigBird数据集中提供的物体配准点云上随机采样物体表面的前两个点p1、p2,接近角在[0,π]之间,每个抓取姿势可以表示为
![]()
B、抓取姿势评分规则
在本文中,我们主要通过结合无摩擦判断方法[10]和力闭合准则[11]来推导抓取姿态的质量分数。对于无摩擦力的判断方法,由于每次抓握都会在物体表面产生两个接触点p1、p2,无论摩擦系数如何,两个接触点将连接的方向和接触点处法线n1和n2之间的角度A1、A2越小,如图3所示,抓握力闭合的可能性就越大,可以用(5)表示
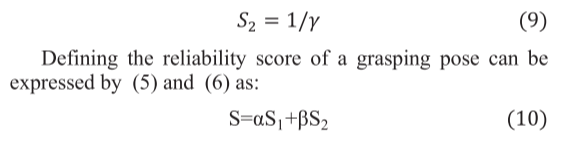
α、 和β是确定这两个度量对抓取姿势的可靠性得分的影响程度的缩放参数。当S较大时,意味着抓握姿势更可靠,抓握物体的成功率更高。

五、掌握姿势质量评价网络
为了验证模型的有效性,本文的实验步骤和设置如下:a.本文首先基于BigBIRD数据集的物点云生成抓取姿态,并结合无摩擦力判断方法和强制闭合准则推导抓取姿态的质量分数,从而获得抓取数据集。b.抓取数据集中的训练集用于对抓取姿态检测模型进行200次迭代训练,每次迭代后,预测数据集中其他对象的抓取姿态类别进行分类。c.将本文的网络与GPD和PointNetGPD在预测测试集中抓取姿势类别方面的准确性进行比较,证明了本文网络的优越性。d.在凉亭仿真平台上,使用训练好的模型驱动机械臂和夹具抓取物体。总体流程图如图8所示,主要分为两个阶段:离线阶段和在线阶段。
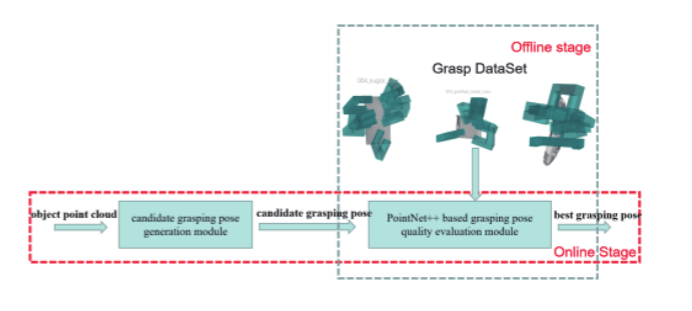
离线阶段的作用是训练一个基于PointNet的模型,用于评估所掌握姿势的质量。由于生成的抓取数据集的标签是连续值,因此可以自定义阈值来确定类别。在线阶段是实时检测物体点云的抓取姿态。首先,深度相机获取物体点云并将其输出到候选抓取姿态生成模块,候选抓取姿态产生模块输出可变量的抓取姿态,然后使用训练后的抓取质量评估模型来获得抓取姿态的类别。
A.掌握评估模型的培训和测试 抓取姿势评估模型的训练在生成抓取数据集时,(7)中的参数α、β表示抓取位姿势得分,设置为0.6、0.4。在本文中,该模型使用二进制分类,阈值设置为1.5,即高于1.5为正。损失函数是交叉熵
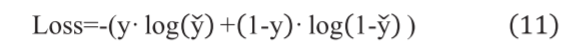
其中,是模型预测样本为阳性病例的概率,y是样本标签,如果样本为阳性,则取1,否则取0。学习率的初始值为0.01,并且选择Adam优化器来动态更新学习率,以避免陷入局部次优解。为了避免梯度消失和梯度爆炸,通过对零均值高斯分布进行采样来初始化所有参数。为了防止模型过拟合,通过添加随机旋转和随机平移来进行数据扩充。
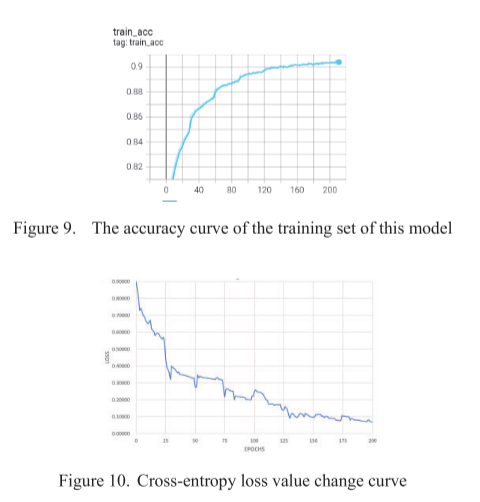
抓取数据集中的25个对象数据用作训练集,其他10个对象数据作为测试集。本文对模型进行了200次训练,模型在训练集中的精度曲线如图9所示,交叉熵损失值变化曲线如图10所示。
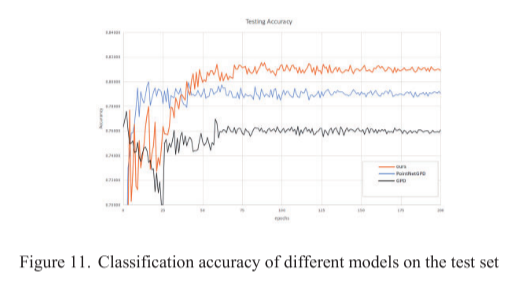
比较研究为了验证本文方法的优越性,使用抓取数据集中包含10个物体抓取数据的测试集对本文模型、GPD和PointNetGPD模型的精度进行了比较,三个模型在测试集中的精度曲线如图所示。11。从图11可以看出,本文模型的分类精度高于GPD和PointNetGPD模型。GPD由于缺乏几何特征而容易过拟合,而使用点云信息作为抓取检测模型输入的PointNetGPD解决了这一问题,提高了精度。本文设计了一种基于PointNet的抓取检测模型,解决了PointNetGPD不能学习局部特征的问题。从图中可以看出,本文中的模型收敛速度比PointNetGPD慢,这是因为使用多层网络结构提取局部特征使模型的层次更深,参数更多,这也使本文中模型的分类精度更高。
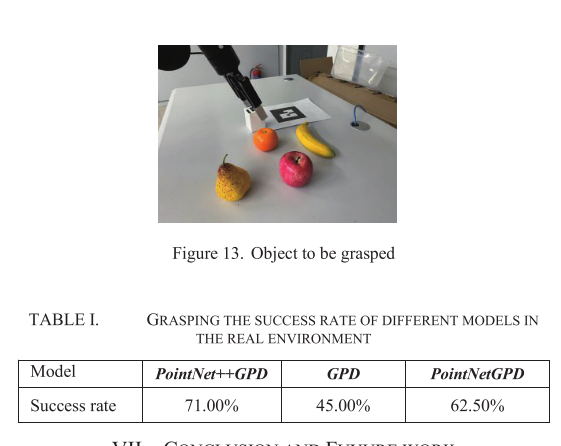
B.真实世界的机械臂抓取实验物理实验使用配备有双指机械爪和KinectV2相机的aubo机械臂来获取点云,实验环境如图12所示。从相机中获取物体的点云信息,使用GPG方法获得不确定数量的抓取姿势,使用抓取姿势评估模型获得每个抓取姿势的类别,并输出具有正类别的抓取姿势。在使用该模型获得抓取姿态后,通过使用BioIK[12]的逆运动学解算器来驱动机械臂,从而求解机械臂关节角度。并用GPD、PointNetGPD与本文的模型进行了比较。将多个物体放置在桌面上,当所有物体都被成功抓住时,实验结束。判断标准是比较抓取成功的概率(抓取成功的次数除以抓取总数)。实验中使用的物体如图13所示,结果如表1所示,从中可以看出,本文的模型预测了更高的抓取姿势精度和更高的抓握成功率。

七、结论与FUYURE WORK
本文提出的PointNet-GPD方法从点云中获取抓取姿态,解决了PointNet-GMD模型不能学习局部特征的缺陷,提高了端到端抓取检测模型的准确性和可靠性。PointNet GPD的缺点是模型太大,参数大约是PointNetGPD的三倍,导致模型的训练时间很长,因此未来的工作将首先减轻本文提出的PointNet GPD模型的重量。本文将在模型中添加一个实例分割算法,以实现对指定对象的抓取。
这篇关于PointNet++GPD<论文>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


