本文主要是介绍简单!实用!易懂!:Java如何批量导出微信收藏夹链接-->转换成Markdown/txt,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 参考方案
- 方案1:Python
- 方案2:Python
- 我的方案
- 手动前置操作
- 代码处理

前言
不知道是否有很多小伙伴跟我一样,有个问题非常愁,对于收藏党来说,收藏了=学会了!然后导致微信收藏夹的东西越来越多了,现在想要把这些内容整理出来导到电脑上,我在全网搜索了太多太多相关的内容,却发现好像没有一个比较实用的工具。
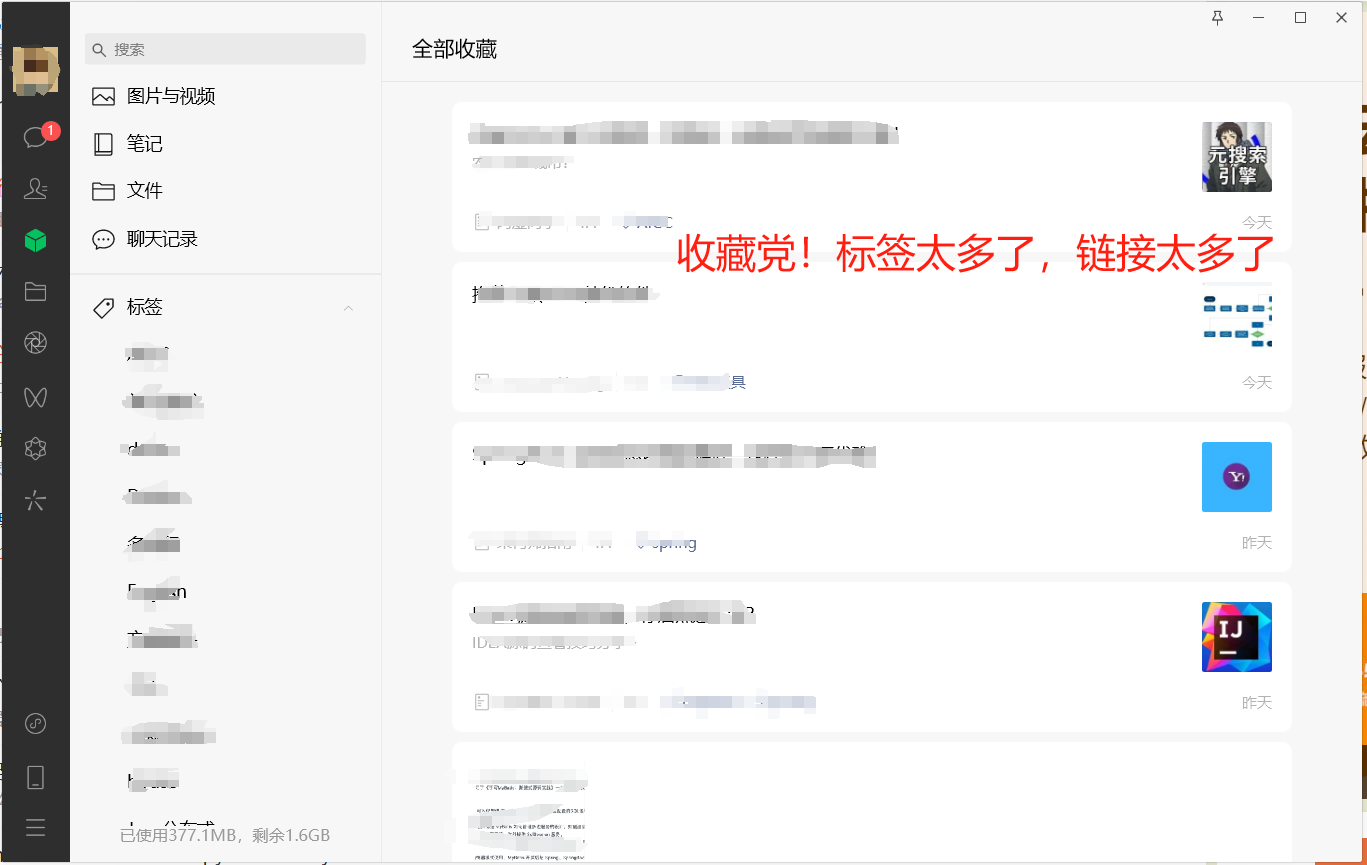
如果手动一个个导的话非常麻烦,操作步骤如下:
1、打开微信收藏,点开标签
2、提取链接:使用鼠标右键点击链接,然后选择“复制地址”
3、导出链接:将复制的链接地址粘贴到一个文本文件中,每个链接一行。
http://mp.weixin.qq.com/s?__biz=MjM5MjAxNDM4MA==&mid=2666802429&idx=1&sn=11ffbcbb32e8956bf3d52086b7288cc0&chksm=bc99d366a8bc341683438c979d747a8e2582ac2683139e2199f3f2380ee1d0efd785f3893e6a&scene=126&sessionid=1710664419#rd
4、为每个链接进行命名:从微信复制出来的链接,没有名字只有单纯的URL链接,你都不知道这个链接是什么,很不友好,所以还得打开链接,复制标题,类似这样的格式
近日择机发射!:http://mp.weixin.qq.com/s?__biz=MjM5MjAxNDM4MA==&mid=2666802429&idx=1&sn=11ffbcbb32e8956bf3d52086b7288cc0&chksm=bc99d366a8bc341683438c979d747a8e2582ac2683139e2199f3f2380ee1d0efd785f3893e6a&scene=126&sessionid=1710664419#rd
如果几百条收藏链接,这样操作得有几千步操作,手工完成得多浪费时间!!!
参考方案
方案1:Python
此方案需要你学过一点python,且好像这种并没有提取标题,我这里并未实际尝试过
可参考链接:分享一个批量提取微信收藏链接到TXT文件的方法
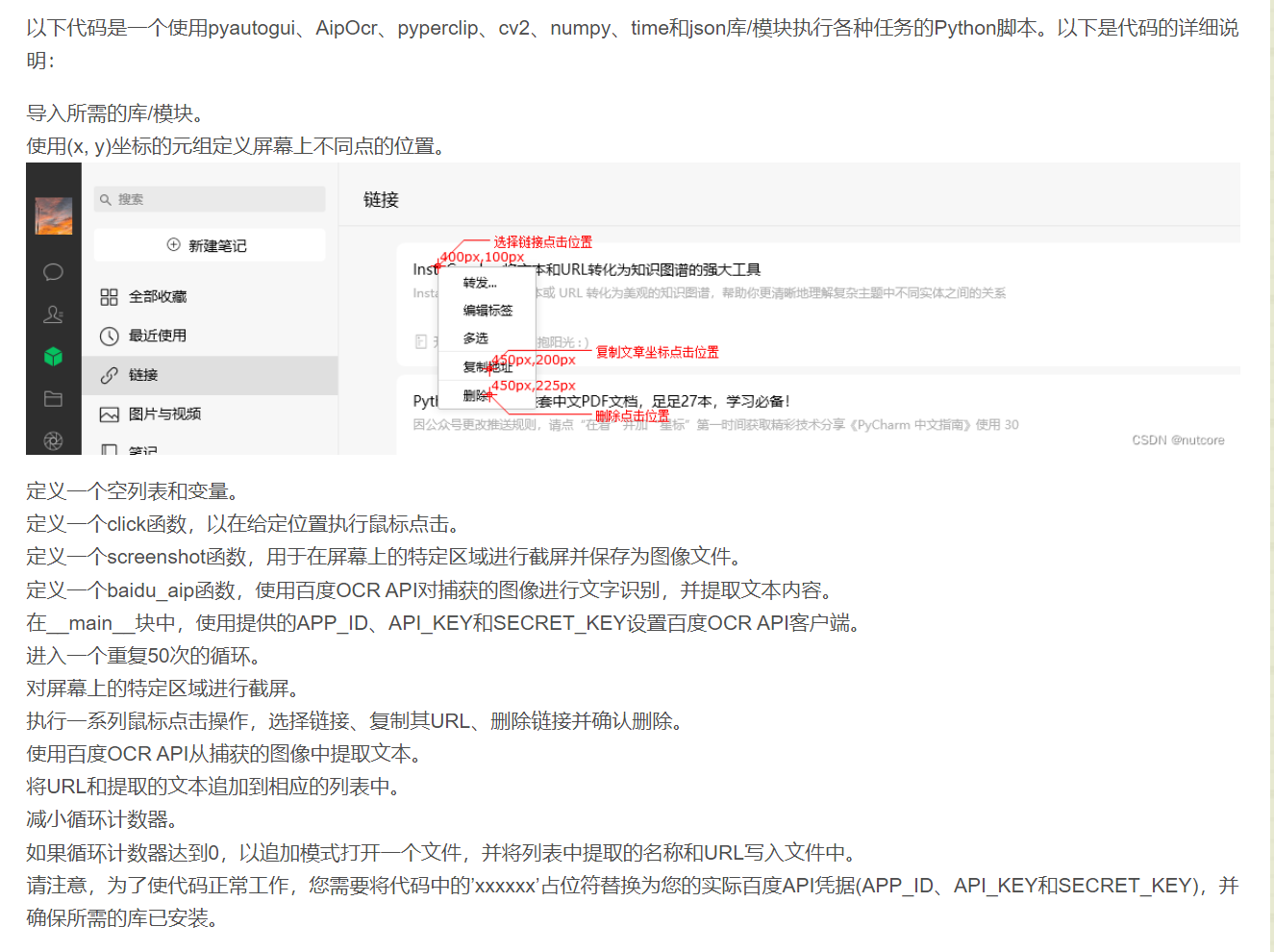
方案2:Python
Python轻松下载或整理删除微信收藏
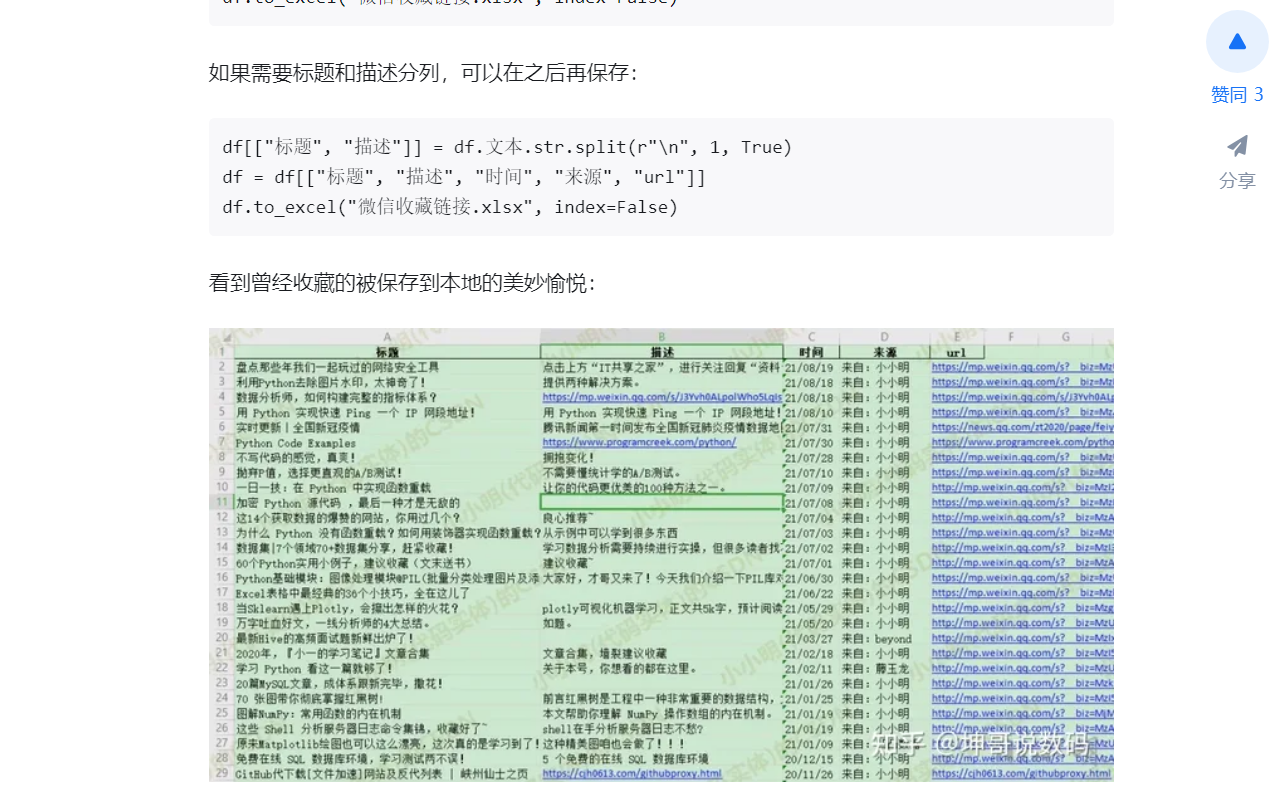
此方案也是采用Python,且看最终的效果不错,有标题和对应的链接,比较符合我的预期,但是我不懂Python咋办??我是Java程序员,我想看看有没有别的方式!
我的方案
手动前置操作
1、先将所有要导出的推文批量多选,并分享给好友或者文件传输助手;
主要批量多选如果在手机没法批量一次性全选的方式,但是电脑可以一键拉取!!!

电脑可以一键拉取全选!!!这样就可以不用一个个像手机一样手动勾选了,说实话,这点微信做的是真的拉胯,居然多选没有做全选的功能!!!

2、选中发送到文件助手
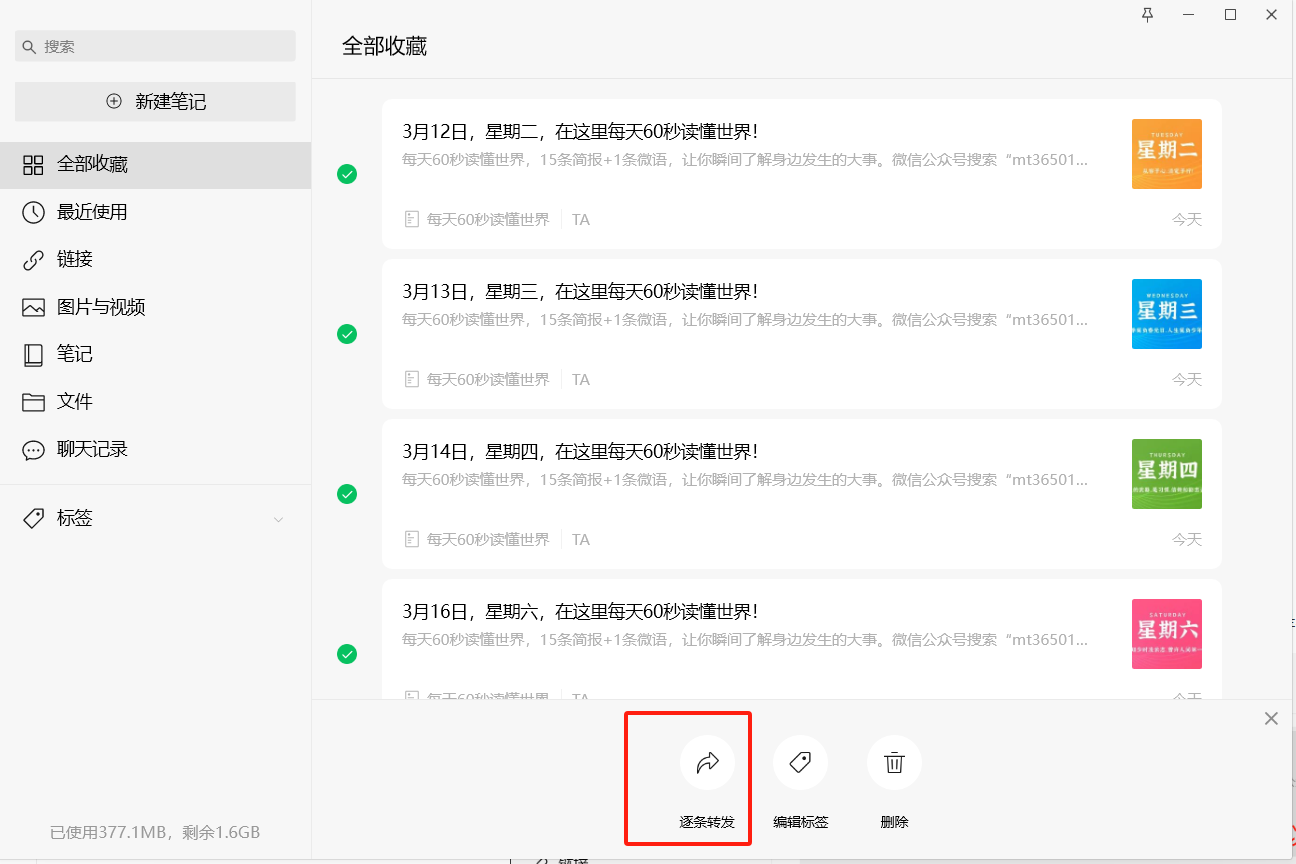

3、然后在聊天界面多选并使用邮箱发送;这点我又要吐槽一下了:
-
电脑版本可以一键拉取聊天记录,但是居然没有发送邮件的功能,
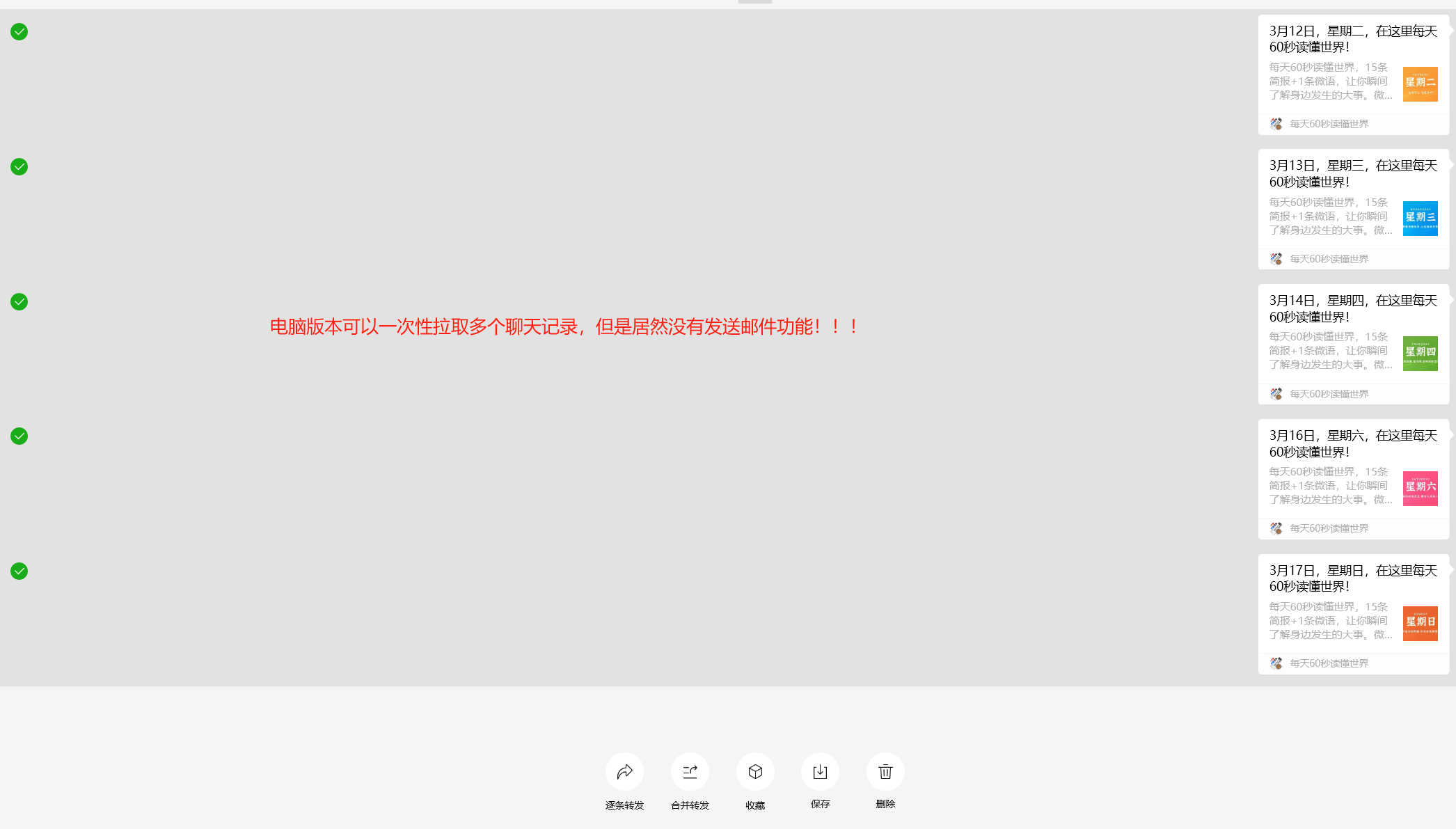
-
手机版本有发送邮件的功能,但是并没有一次性全选的功能,我这里又只能一个个去勾选了。。。

4、打开邮箱,复制内容保存文本为测试链接.txt
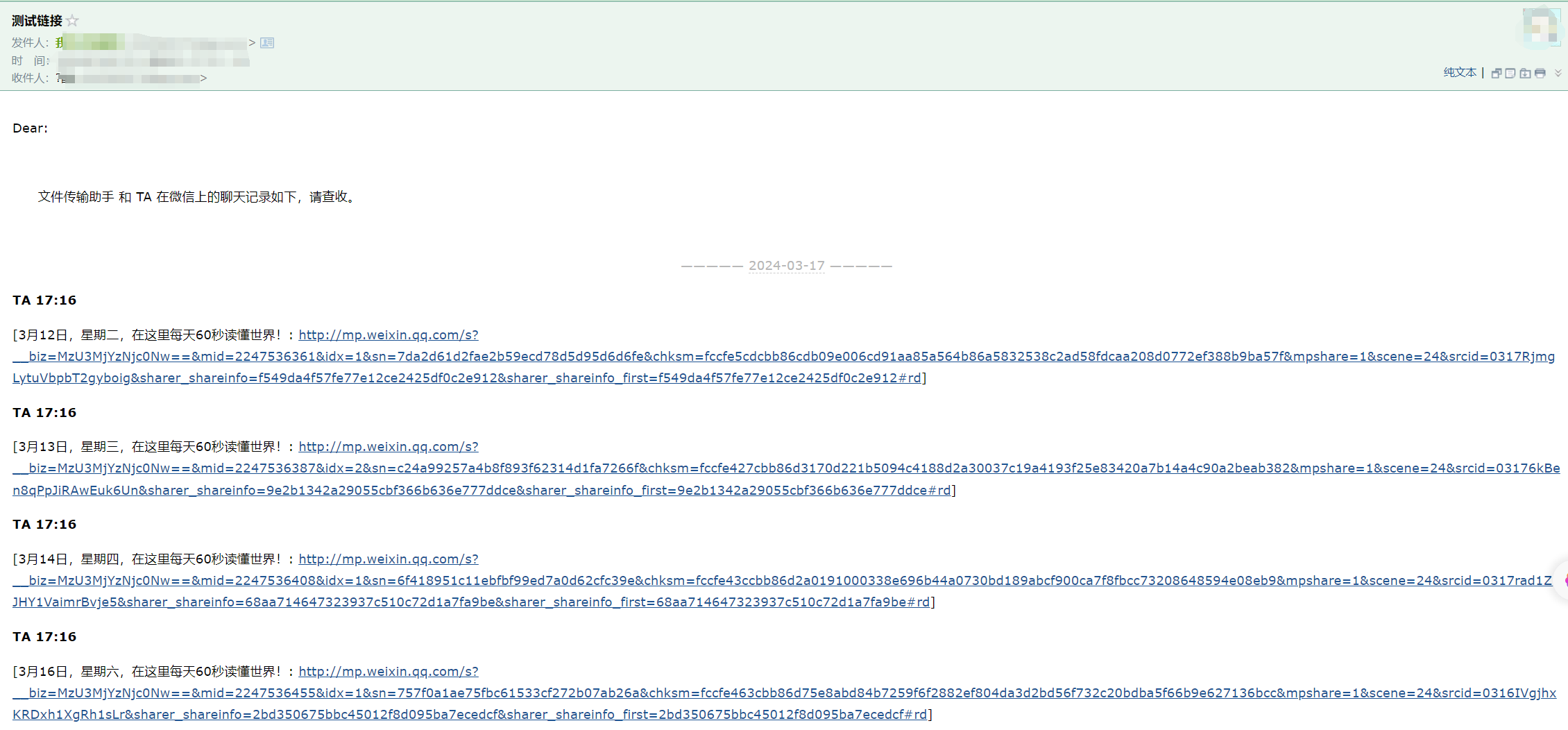
代码处理
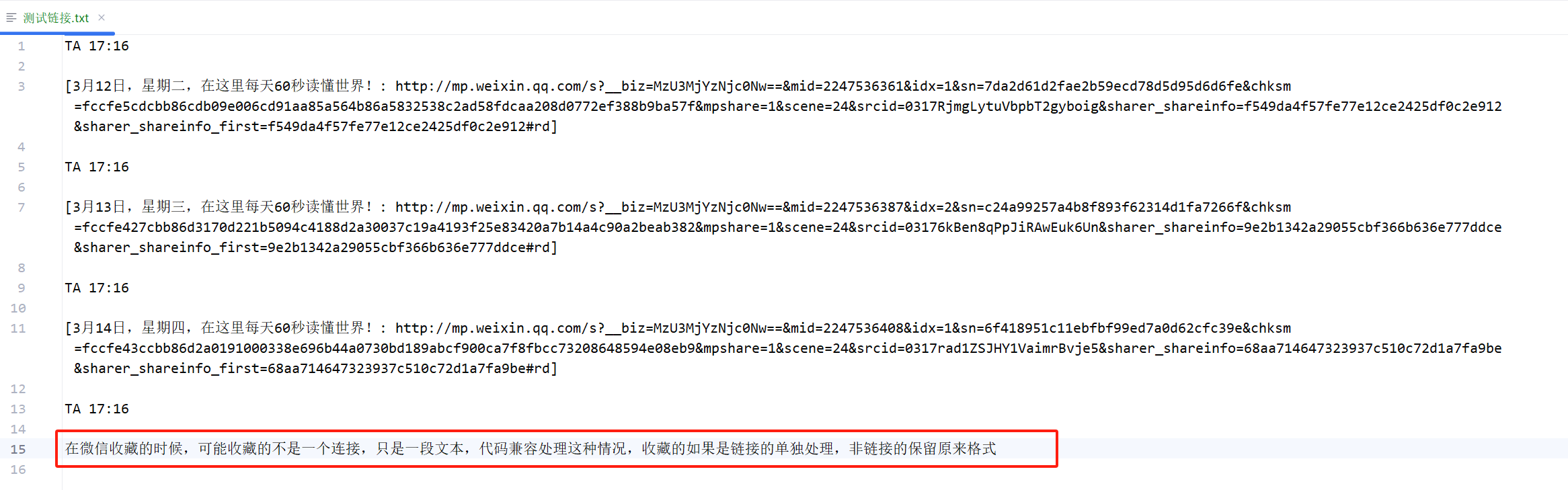
上面我们把内容保存了为测试链接.txt,里面内容如下所示,
注意一点: 我这里多放了一种不是链接的内容,是因为有时候我在微信收藏的时候,可能收藏的不是一个连接,只是一段文本,代码兼容处理这种情况,收藏的如果是链接的单独处理,非链接的保留原来格式
我的目的就是将txt里面的内容进行处理,需要符合以下条件:
- 如果是[title:url]这种格式的,就转换成Markdown格式输出,输出到
测试链接-md.md - 如果是非上面的格式,也就是纯文本这种,就保持原样输出,输出到
测试链接-other.txt - 同时上面的文件输出时,每个收藏都需要有序号标注
接下来就是代码处理了:
下面代码我们从一个文本输入文件 (E:\code\测试链接.txt) 中读取内容,根据特定的分隔模式切分内容(我们会发现微信导出来的收藏内容,每个都是 微信名字 时间点,也就是需要针对这块进行分割内容,分割的话可以用正则表达式),并根据内容的格式将其转换为Markdown格式或者原始的文本格式,最后将转换后的结果输出到两个不同的文件中(一个是Markdown格式的文件 E:\code\测试链接-md.md,另一个是原始文本格式的文件 E:\code\测试链接-other.txt)。
// 用于处理文本内容转换
public class Content2MdAndTxtForPattern {// 定义一个正则表达式模式,用于匹配类似 "TA 21:54 " 这样的分隔符,\s+代表一个或多个空格。public static final Pattern DELIMITER_PATTERN = Pattern.compile("TA\\s+\\d{2}:\\d{2}\\s+");public static void main(String[] args) {// 文件名前缀String fileName = "测试链接";// 定义输入文件的路径String inputFilePath = "E:\\code\\" + fileName + ".txt";// 定义Markdown格式输出文件的路径String outputBPath = "E:\\code\\" + fileName + "-md.md";// 定义原始文本格式输出文件的路径String outputCPath = "E:\\code\\" + fileName + "-other.txt";try {// 读取输入文件的全部内容到字符串中String content = new String(Files.readAllBytes(Paths.get(inputFilePath)));// 使用定义的分隔模式分割文件内容String[] sections = DELIMITER_PATTERN.split(content);// 初始化Markdown输出文件的序号int countB = 1;// 初始化原始文本输出文件的序号int countC = 1;try (BufferedWriter writerB = Files.newBufferedWriter(Paths.get(outputBPath));BufferedWriter writerC = Files.newBufferedWriter(Paths.get(outputCPath))) {// 遍历分割后的所有部分,从索引1开始,因为分割后的第一个部分(索引0)是不需要的内容for (int i = 1; i < sections.length; i++) {// 去除内容前后的空白字符String section = sections[i].trim();// 定义一个新的正则表达式模式,用于匹配带链接的文本Pattern pattern = Pattern.compile("\\[([^\\]]+):\\s*(http[^\\]]+)\\]");// 创建matcher去匹配当前部分内容Matcher matcher = pattern.matcher(section);// 如果匹配到带链接的文本格式if (matcher.find()) {// 提取标题和URLString title = matcher.group(1).trim();String url = matcher.group(2).trim();// 将提取出来的标题和URL转换为Markdown格式,写入到对应的文件中writerB.write(countB++ + ". [" + title + "](" + url + ")\n");} else {// 如果不是链接格式,原样写入到另一个文件中writerC.write(countC++ + ". " + section + "\n");}}}// 文件处理完毕后打印提示信息System.out.println("内容已解析到文件:" + outputBPath + " 和 " + outputCPath);} catch (IOException e) {e.printStackTrace();}}
}
最终效果如下:
1、Markdown文件内容如下

2、txt纯文本打开内容如下

参考文章:
https://blog.csdn.net/qq_32832803/article/details/122508085
https://blog.csdn.net/fitAllEnv/article/details/134000975
https://blog.csdn.net/u010751000/article/details/106515427
https://blog.csdn.net/m0_59235245/article/details/124973234
这篇关于简单!实用!易懂!:Java如何批量导出微信收藏夹链接-->转换成Markdown/txt的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





