本文主要是介绍U-Net原理、SegNet和DeepLab等分割任务综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Unet 背景介绍:
Unet 发表于 2015 年,属于 FCN 的一种变体。Unet 的初衷是为了解决生物医学图像方面的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。
Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。Encoder 负责特征提取,你可以将自己熟悉的各种特征提取网络放在这个位置。由于在医学方面,样本收集较为困难,作者为了解决这个问题,应用了图像增强的方法,在数据集有限的情况下获得了不错的精度。
Unet 网络结构与细节
- Encoder
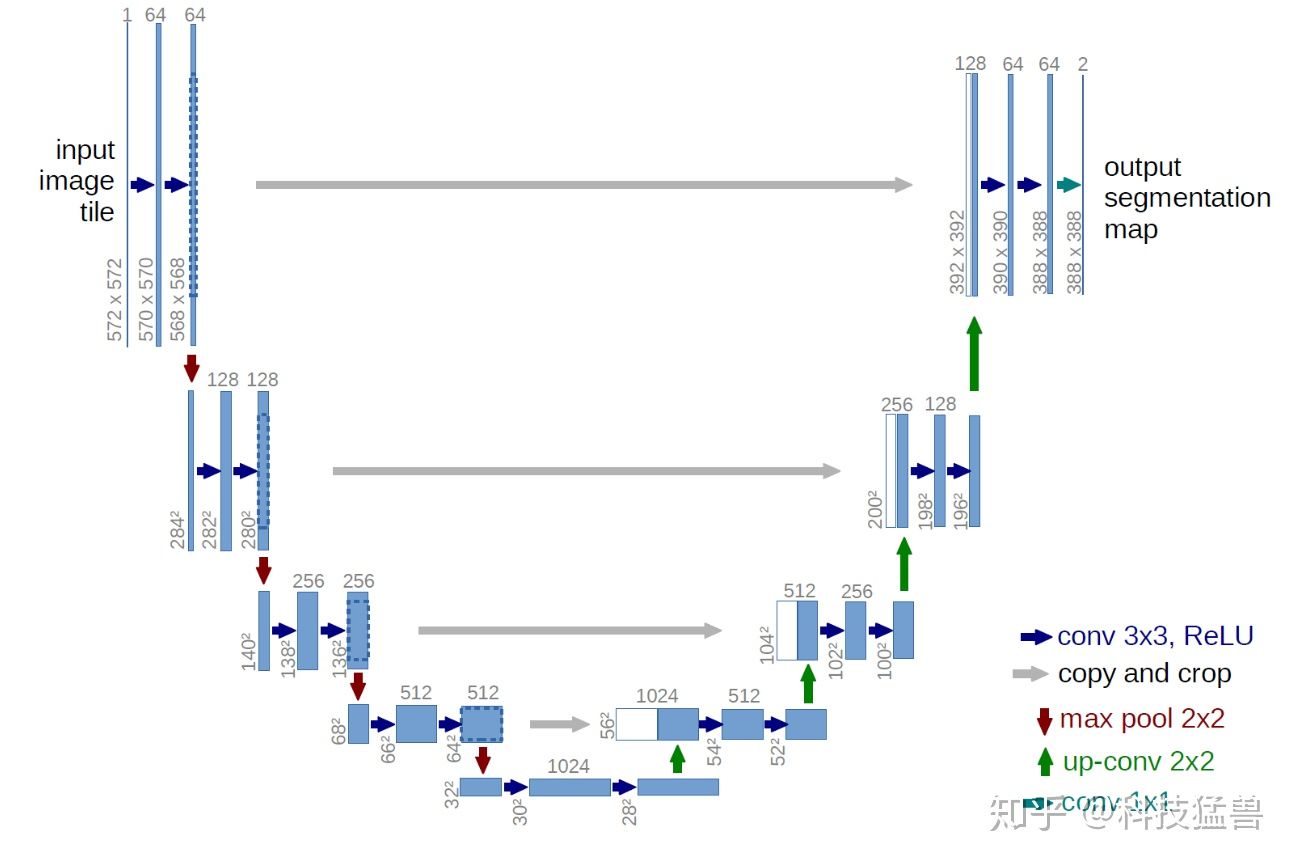
如上图,Unet 网络结构是对称的,形似英文字母 U 所以被称为 Unet。整张图都是由蓝/白色框与各种颜色的箭头组成,其中,蓝/白色框表示 feature map;蓝色箭头表示 3x3 卷积,用于特征提取;灰色箭头表示 skip-connection,用于特征融合;红色箭头表示池化 pooling,用于降低维度;绿色箭头表示上采样 upsample,用于恢复维度;青色箭头表示 1x1 卷积,用于输出结果。其中灰色箭头copy and crop中的copy就是concatenate而crop是为了让两者的长宽一致
可能你会问为啥是 5 层而不是 4 层或者 6 层,emmm,这应该去问作者本人,可能对于当时作者拿到的数据集来说,这个层数的表现更好,但不代表所有的数据集这个结构都适合。我们该多关注这种 Encoder-Decoder 的设计思想,具体实现则应该因数据集而异。
Encoder 由卷积操作和下采样操作组成,文中所用的卷积结构统一为 3x3 的卷积核,padding 为 0 ,striding 为 1。没有 padding 所以每次卷积之后 feature map 的 H 和 W 变小了,在 skip-connection 时要注意 feature map 的维度(其实也可以将 padding 设置为 1 避免维度不对应问题),pytorch 代码:
nn.Sequential(nn.Conv2d(in_channels, out_channels, 3),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))上述的两次卷积之后是一个 stride 为 2 的 max pooling,输出大小变为 1/2 *(H, W):
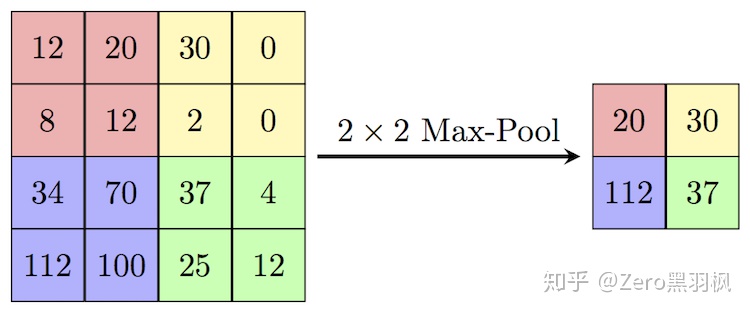
pytorch 代码:
nn.MaxPool2d(kernel_size=2, stride=2)上面的步骤重复 5 次,最后一次没有 max-pooling,直接将得到的 feature map 送入 Decoder。
- Decoder
feature map 经过 Decoder 恢复原始分辨率,该过程除了卷积比较关键的步骤就是 upsampling 与 skip-connection。
Upsampling 上采样常用的方式有两种:1.FCN 中介绍的反卷积;2. 插值。这里介绍文中使用的插值方式。在插值实现方式中,bilinear 双线性插值的综合表现较好也较为常见 。
双线性插值的计算过程没有需要学习的参数,实际就是套公式,这里举个例子方便大家理解(例子介绍的是参数 align_corners 为 Fasle 的情况)。
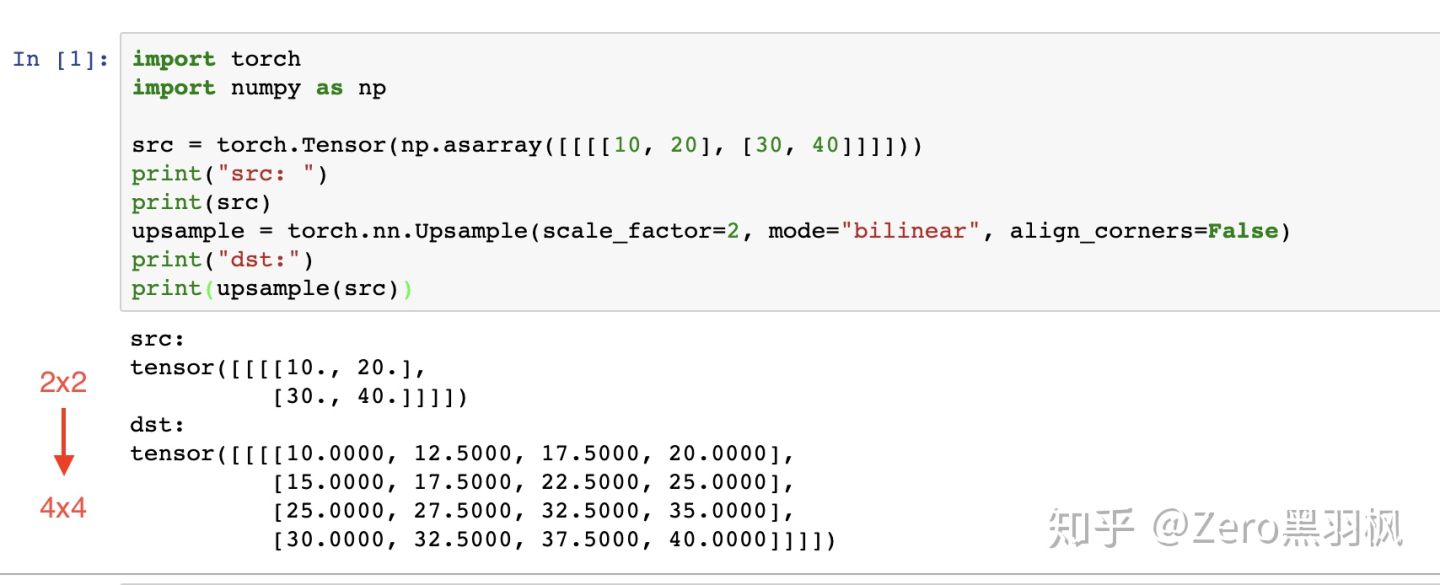
例子中是将一个 2x2 的矩阵通过插值的方式得到 4x4 的矩阵,那么将 2x2 的矩阵称为源矩阵,4x4 的矩阵称为目标矩阵。双线性插值中,目标点的值是由离他最近的 4 个点的值计算得到的,我们首先介绍如何找到目标点周围的 4 个点,以 P2 为例。

第一个公式,目标矩阵到源矩阵的坐标映射:

为了找到那 4 个点,首先要找到目标点在源矩阵中的相对位置,上面的公式就是用来算这个的。P2 在目标矩阵中的坐标是 (0, 1),对应到源矩阵中的坐标就是 (-0.25, 0.25)。坐标里面居然有小数跟负数,不急我们一个一个来处理。我们知道双线性插值是从坐标周围的 4 个点来计算该坐标的值,(-0.25, 0.25) 这个点周围的 4 个点是(-1, 0), (-1, 1), (0, 0), (0, 1)。为了找到负数坐标点,我们将源矩阵扩展为下面的形式,中间红色的部分为源矩阵。
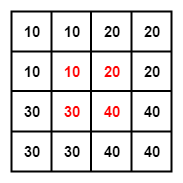
我们规定 f(i, j) 表示 (i, j)坐标点处的像素值,对于计算出来的对应的坐标,我们统一写成 (i+u, j+v) 的形式。那么这时 i=-1, u=0.75, j=0, v=0.25。把这 4 个点单独画出来,可以看到目标点 P2 对应到源矩阵中的相对位置。

第二个公式,也是最后一个。
f(i + u, j + v) = (1 - u) (1 - v) f(i, j) + (1 - u) v f(i, j + 1) + u (1 - v) f(i + 1, j) + u v f(i + 1, j + 1)
目标点的像素值就是周围 4 个点像素值的加权和,明显可以看出离得近的权值比较大例如 (0, 0) 点的权值就是 0.75*0.75,离得远的如 (-1, 1) 权值就比较小,为 0.25*0.25,这也比较符合常理吧。把值带入计算就可以得到 P2 点的值了,结果是 12.5 与代码吻合上了,nice。
pytorch 里使用 bilinear 插值:
nn.Upsample(scale_factor=2, mode='bilinear')CNN 网络要想获得好效果,skip-connection 基本必不可少。Unet 中这一关键步骤融合了底层信息的位置信息与深层特征的语义信息,pytorch 代码:
torch.cat([low_layer_features, deep_layer_features], dim=1)这里需要注意的是,FCN 中深层信息与浅层信息融合是通过对应像素相加的方式,而 Unet 是通过拼接的方式。
那么这两者有什么区别呢,其实 在 ResNet 与 DenseNet 中也有一样的区别,Resnet 使用了对应值相加,DenseNet 使用了拼接。个人理解在相加的方式下,feature map 的维度没有变化,但每个维度都包含了更多特征,对于普通的分类任务这种不需要从 feature map 复原到原始分辨率的任务来说,这是一个高效的选择;而拼接则保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势。
---------------------------
SegNet:
FCN 和 U-Net 是最先出现的编码器-解码器结构,都利用了快捷连接向解码器中引入编码器提取的特征。FCN 中的快捷连接是通过将编码器提取的特征进行复制,叠加到之后的卷积层提取出的特征上,作为解码器的输入来实现的。与 FCN 不同,SegNet 提出了最大池化索引(max-pooling indicies)的概念,快捷连接传递的不是特征本身,而是最大池化时所使用的索引(位置坐标)。利用这个索引对输入特征进行上采样,省去了反卷积操作,这也使得 SegNet 比 FCN 节省了不少存储空间。
----------------------------
DeepLab v1:
DeepLab v1 算法主要有两个创新点,分别是空洞卷积(Atrous Covolution,Dilated Convolution,膨胀卷积)和全连接条件随机场(fully connected CRF),具体算法流程如图9.5所示。空洞卷积是为了解决编码过程中信号不断被下采样、细节信息丢失的问题。由于卷积层提取的特征具有平移不变性,这就限制了定位精度,所以 DeepLab v1 引入了全连接条件随机场来提高模型捕获局部结构信息的能力。具体来说,将每一个像素作为条件随机场的一个节点,像素与像素间的关系作为边,来构造基于全图的条件随机场。参考文献[29]采用基于全图的条件随机场而非短程条件随机场(short-range CRF),主要是为了避免使用短程条件随机场带来的平滑效果。正是如此,与其他先进模型对比,DeepLab v1 的预测结果拥有更好的边缘细节。


不过光理解他的工作原理还是远远不够的,要充分理解这个概念我们得重新审视卷积本身,并去了解他背后的设计直觉。以下主要讨论 dilated convolution 在语义分割 (semantic segmentation) 的应用。
重新思考卷积: Rethinking Convolution
在赢得其中一届ImageNet比赛里VGG网络的文章中,他最大的贡献并不是VGG网络本身,而是他对于卷积叠加的一个巧妙观察。
This (stack of three 3 × 3 conv layers) can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
这里意思是 7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加。而这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。

然而 Deep CNN 对于其他任务还有一些致命性的缺陷。较为著名的是 up-sampling 和 pooling layer 的设计。这个在 Hinton 的演讲里也一直提到过。
主要问题有:
- Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)
- 内部数据结构丢失;空间层级化信息丢失。
- 小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度, 而 dilated convolution 的设计就良好的避免了这些问题。

总结-空洞卷积(Dilated/Atrous Convolution) - 知乎
空洞卷积gridding问题
是的,空洞卷积是存在理论问题的,论文中称为gridding,其实就是网格效应/棋盘问题。因为空洞卷积得到的某一层的结果中,邻近的像素是从相互独立的子集中卷积得到的,相互之间缺少依赖。
- 局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。
- 远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果。
解决方案
- Panqu Wang,Pengfei Chen, et al.Understanding Convolution for Semantic Segmentation.//WACV 2018
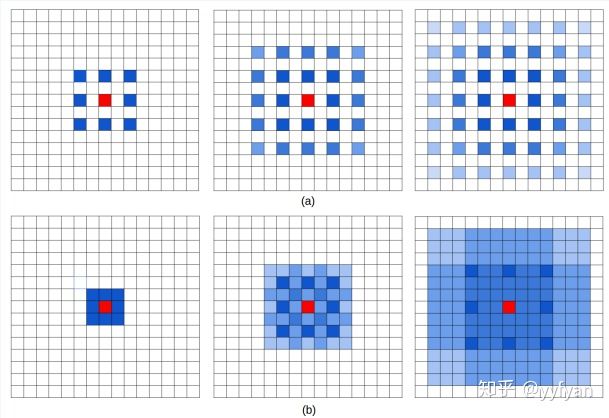
通过图a解释了空洞卷积存在的问题,从左到右属于top-bottom关系,三层卷积均为r=2的dilatedConv,可以看出最上层的红色像素的感受野为13且参与实际计算的只有75%,很容易看出其存在的问题。
使用HDC(Hybrid Dilated Convolution)的方案解决该问题,不同于采用相同的空洞率的deeplab方案,该方案将一定数量的layer形成一个组,然后每个组使用连续增加的空洞率,其他组重复。如deeplab使用rate=2,而HDC采用r=1,r=2,r=3三个空洞率组合,这两种方案感受野都是13。但HDC方案可以从更广阔的像素范围获取信息,避免了grid问题。同时该方案也可以通过修改rate任意调整感受野。
- Fisher Yu, et al. Dilated Residual Networks. //CVPR 2017

如果特征map有比空洞率更高频的内容,则grid问题更明显。
提出了三种方法:
Removing max pooling:由于maxpool会引入更高频的激活,这样的激活会随着卷积层往后传播,使得grid问题更明显。

Adding layers:在网络最后增加更小空洞率的残参block, 有点类似于HDC。
Removing residual connections:去掉残参连接,防止之前层的高频信号往后传播。
- Zhengyang Wang,et al.Smoothed Dilated Convolutions for Improved Dense Prediction.//KDD 2018.
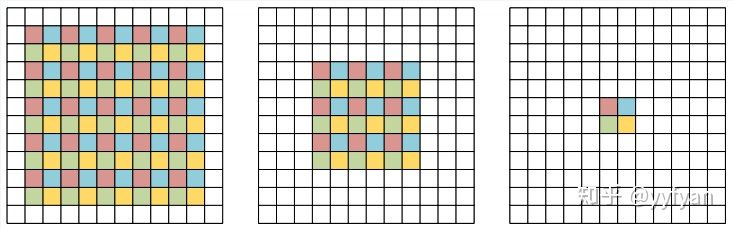
空洞卷积的分解观点,在原始特征图上周期性采样形成4组分辨率降低的特征图,然后使用原始的空洞卷积参数(去掉了空洞0)分别进行卷积,之后将卷积的结果进行上采样组合。从该分解观点可以看出,卷积前后的4个组之间没有相互依赖,使得收集到不一致的局部信息。

从上面分解的观点出发:
(1) 在最后生成的4组卷积结果之后,经过一层组交错层,类似于ShuffleNet,使得每组结果能进行相互交错,相互依赖,以此解决局部信息不一致的问题。
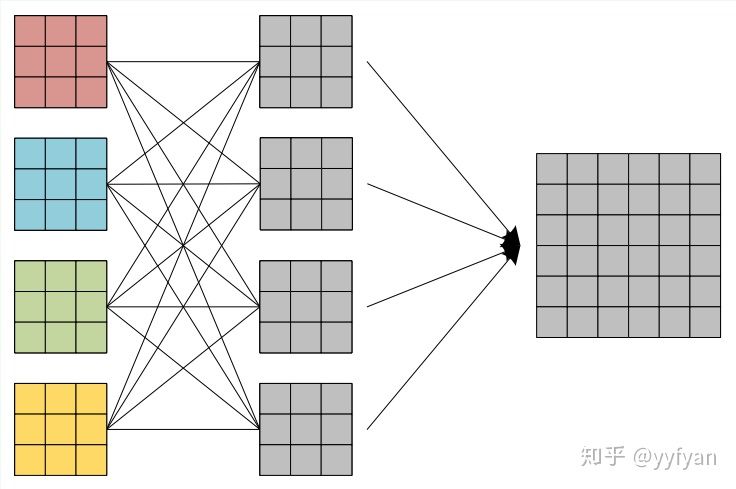
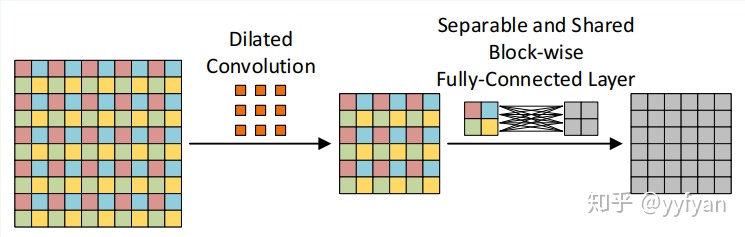
(2) 第二种方法为在空洞卷积之前进行局部信息依赖,即增加一层卷积操作,卷积利用了分离卷积,并且所有通道共享参数。

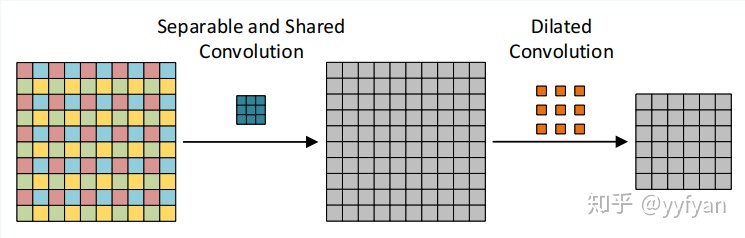
- Liang-Chieh Chen,et al.Rethinking Atrous Convolution for Semantic Image Segmentation//2017
deeplabv3在v2基础上进一步探索空洞卷积,分别研究了级联ASPP与并联ASPP两种结构。

deeplabv3不同于deeplabv2,在resnet101基础上级联了更深的网络,随着深度的增加,使用了不同的空洞率的卷积,这些卷积保证分辨率不降低的情况下,感受野可以任意控制,一般让空洞率成倍增加。同时使用了Multigrid策略,在同一个blocks的不同层使用分层的空洞率,如2,4,8,而不是都使用2,这样使得感受野相比原来的有所增加。但这样同样会存在grid问题。
ASPP存在的问题,当使用的空洞率增大时,有效的滤波参数数量逐渐减小。极端的,当r等于特征图大小时,该卷积没有捕获整幅图像的上下文信息,而是退化为1*1卷积。
解决方案:增加图像级特征,使用全局池化获取图像全局信息,而其他部分的卷积为了捕获多尺度信息,这里的卷积不同于deeplabv2,加了batch normalization。
- Sachin Mehta,et al. ESPNet: Efficient Spatial Pyramid of DilatedConvolutions for Semantic Segmentation. //ECCV 2018
ESPNet利用分解卷积的思想,先用1*1卷积将通道数降低减少计算量,后面再加上基于空洞卷积的金字塔模型,捕获多尺度信息。

之前的方法都是通过引入新的计算量,学习新的参数来解决grid问题。而这里直接使用了特征分层的思想直接将不同rate的空洞卷积的输出分层sum,其实就是将不同的感受野相加,弥补了空洞带来的网格效应。从结果上看效果不错。

训练技巧:
所有卷积后都使用BN和PReLU,很多实时分割小网络都使用了PReLU;
使用Adam训练,很多小网络使用这个;
- Tianyi Wu,et al.Tree-structured Kronecker Convolutional Networks for Semantic Segmentation.//ICME 2019

使用Kronecker convolution来解决空洞卷积局部信息丢失问题,以r1=4、r2=3为例,KConv将每个标准卷积的元素都乘以一个相同的矩阵,该矩阵由0,1组成,这样参数量是不增加的。该矩阵为:
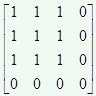
这样每个元素乘以矩阵后变为上面右图所示的图。因此,可以看出r1控制空洞的数量,也即扩大了感受野,而r2控制的是每个空洞卷积忽视的局部信息。当r2=1时,其实就是空洞卷积,当r2=r1=1时就是标准卷积。
总体效果mIOU提升了1%左右。
除此之外,提出了一个TFA模块,利用树形分层结构进行多尺度与上下文信息整合。结构简单,但十分有效,精度提升4-5%。
- Hyojin Park,et al.Concentrated-Comprehensive Convolutionsfor lightweight semantic segmentation.//2018

针对实时语义分割提出的网络结构,深度分离卷积与空洞卷积的组合,在ESPNet上做的实验。并且说明简单的组合会带来精度的降低,由于局部信息的丢失。为此,在深度分离空洞卷积之前,使用了两级一维分离卷积捕获局部信息。
网络结构上与ESPNet保持一致,其中,并行分支结果直接Cat,不需要后处理,每个分支不需要bn+relu。消融实验表明,在一维卷积之间加入BN+PReLU,精度会增加1.4%。
- Efficient Smoothing of Dilated Convolutions for Image Segmentation.//2019





From 如何理解空洞卷积(dilated convolution)? - 知乎
----------------------------
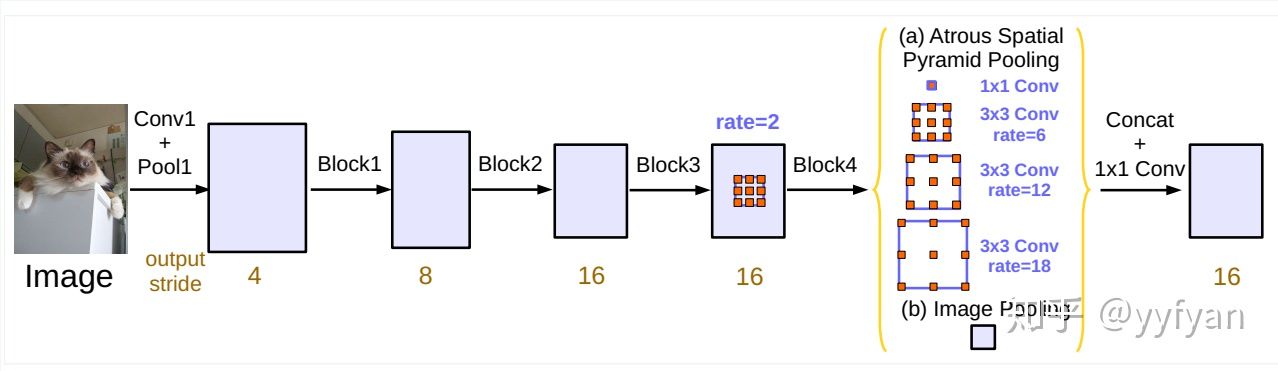
相较于 DeepLab v1, DeepLab v2 的不同之处是提出了空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)[30],并将 DeepLab v1 使用的 VGG 网络替换成了更深的 ResNet 网络。ASPP 可用于解决不同检测目标大小差异的问题:通过在给定的特征层上使用不同扩张率的空洞卷积,ASPP可以有效地进行重采样,如图9.6所示。模型最后将 ASPP 各个空洞卷积分支采样后的结果融合到一起,得到最终的分割结果。

图9.6 空洞空间金字塔池化示意图 (有效感受野的大小由不同颜色标记)
----------------------------
DeepLab v3 在 ASPP 部分做了进一步改动。首先,DeepLab v3加入了批归一化(BN)层;其次,将 ASPP 中尺寸为3×3、空洞大小为 24 的卷积(图9.6中最右边的卷积)替换为一个普通的 1×1 卷积,以保留滤波器中间部分的有效权重。这么做的原因是研究者通过实验发现,随着空洞卷积扩张率的增大,滤波器中有效权重的个数在减小。为了克服长距离下有效权重减少的问题,DeepLab v3 在空洞空间金字塔的最后增加了全局平均池化以便更好地捕捉全图信息。改进之后的 ASPP 部分如图9.7所示[31]。此外,DeepLab v3 去掉了 CRF,并通过将 ResNet 的 Block4 复制3次后级联在原有网络的最后一层来增加网络的深度。网络深度的增加是为了捕获更高层的语义信息。

转自: U-Net原理分析与代码解读 - 知乎
和 葫芦书
这篇关于U-Net原理、SegNet和DeepLab等分割任务综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






