本文主要是介绍对ANNs相关论文的阅读及PyTorch代码学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
文献阅读
torchvision中数据集的使用
DataLoader的使用
神经网络的基本骨架-nn.Moudle的使用
总结
摘要
本周对文献展开了阅读和理解,针对ANNs的相关内容进行了学习,以及对于PyTorch的基本方法继续上周后的学习内容。
文献阅读
题目:基于人工神经网络算法的大气污染统计预测模型研究进展
作者:屈 坤 王雪松# 张远航
abstract:
人工神经网络算法(ANNs)能够对影响大气污染物各变量间的非线性关系进行较好描述,因而在空气质量预 测、重污 染预警工作中得到了广泛的应用。随着算法结构的不断发展,基于 ANNs的大气污染统计预测模型在其预测精准性上得以显著提升。对近年来的相关研究成果进行归纳,从变量的选取与预处 理、算法结构的调整与优化等方面总结提升模型预测性能的主要方法,最终形成构建基于 ANNs的大气污染统计预测模型的方法体系。
论文目的:
对近年来基于ANNs的 大 气污染统计预测模型的研究进展进行总结,梳理算法改进与优化的基本思路,为多层 次 预 报 预 警 系 统 的构建提供理论基础。
ANNs模型的组成:
-
输入层(算法输入变量)
-
输出层(算法输出变量)
-
隐藏层(Sigmoid函数作为激活函数)
采用多层感知机(MLP)结构,无论如何变化其基本结构组成仍然与MLP相似。
ANNs的重点内容:
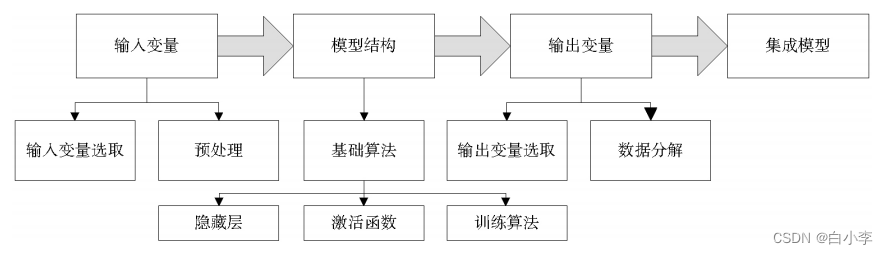
对于输入变量进行标准化处理以防止数据数量级不同而加大计算量的问题出现,处理方法有如下几种:
-
线性转化至[0,1];
-
线性转化 至[a,b],通常选择区间为[0.1,0.9]或[0.2,0.8];
-
统计学意义的数据标准化;
-
通过除以最大值,进行简单标准化。
对输入变量的组合:
-
降维处 理,以减少变量间共线性的影响、提高预测效率。
-
进行分类,将分类结果作为一类新的变量加入模 型,使预测 更具针对 性。
输出变量的分解:
对基于ANNs的大气 污染统计预测模型进行训练时,可将所关注污染物 的浓度分解为不同频率的周期性序列与非周期性序 列的加和,并选取其中的周期性序列作为预测模型 的输出变量。常用方法包 括小波分解、经验模态分解(EMD)等。
隐藏层的结构设计:
隐藏层主要设计为单层结构,节点数过少,模型难以把握各数据间复 杂的作用关系;节点数过多,数据本身噪音的影响被 放大,模型易出现过拟合现象,同时增加计算消耗。在确定节点数时通常参考一些与输入层输出层节点数相关的经验公式。
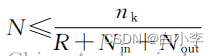
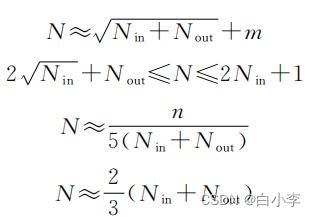
N 为隐藏层节点数;nk为训练数据类别数;R、m 均为经验参数,分别取5~10、0~10;Nin、Nout分 别为输入层、输出层节点数;n为训练总数据量。
各种不同算法的大气污染统计预测模型性能比较:
-
在NUNNARI中用于比较的算法共8类,包括了ANNs、FNN 算法、广义线性算法、相空间局地预测算法、线性时间序列模型等。对预测结果进行评估,总体上非线性模型的预测结果要好于线性模型。
-
在HAJEK中选取用于比对的算法包括前向传播神经网络算法(FFNNs)、时延神经网络算(TDNNs)、径向基神经网络算法(RBF)、 SNR等11类,发现结构更为复杂的RBF与SVR等算法效果要好于结构较为简单的 FFNNs。
-
在GONC中共考虑8类算法,包括 ANNS、SVM、 CART、RF、梯度增强机(GBM)、adaboost算法、装袋算法(Bagging)与线性聚合(L-ensemble)。预测结果表明各算法的预测性能间差异不大,CART所得预测结果总体上要好于ANNs与SVM,集成模型所得结果精确度要优于单个模型。
论文结论:
-
ANNs的预测性能一般优于线性算法,但与其他非线性算法进行比对时并不能够得到明确的结论;
-
结构相对复杂的 ANNs预测能力一般强于 结构简单的MLP等;
-
集成模型的预测性能一般优于单个模型;
-
结合多类参数训练、输入变量预处理与输出变量分解等环节的先进算法可提升基于 ANNs的大气污染统计预测模型的整体性能。
针对于ANNs改进方向:
-
完善模型构建的基础内容。
-
加强模型构建的体系化。
-
进 一 步 提 升 模 型 的 预 测 能 力。
torchvision中数据集的使用
torchvision独立于pytorch,专门用来处理图像,通常用于计算机视觉领域。在pytorch中存在许多数据集给我们使用,通过到官方网站进行下载后,可以对利用这些数据集来完成我们的目的。
其中在torchvision最常用的3个包:
models:提供了很多常用的训练好的网络模型
transforms:提供了一些常用的图像转换处理操作,主要针对Tensor或PIL Image进行操作
datasets:提供了一些常用的图片数据集和加载自己的数据集的常用方法
import torchvisiontrain_set torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)print(test_set[0])print(test_set.classes)
img,target = test_set[0]
print(target)
print(img)
print(test_set.classes[target])
img.show()打印后的结果

与transforms的联合使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor()])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
writer = SummaryWriter("p10")
for i in range (10): img ,target = test_set[i] writer.add_image("test_set", img, i)
writer.close()DataLoader的使用
DataLoader就是数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。
在pytorch中加载数据的顺序一般为先创建一个dataset对象,之后创建一个dataloader对象,最后对dataloader进行循环操作,讲data,lable拿到模型中去训练
import torchvision
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./daataset", train=False, download=True,transform=torchvision.transforms.ToTensor())#batch_size每次取4个数据集进行打包,
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)将数据打包后的输出

在实践中,数据读取经常是训练的性能瓶颈,特别当模型较简单或者计算硬件性能较高时。Pytorch的Dataloader中一个很方便的功能是允许使用多进程来加速数据读取,我们可以通过num_workers来设置使用几个进程读取数据。
神经网络的基本骨架-nn.Moudle的使用
Module是Contains中最常用的模块。
使用nn.Moudle,首先是创建一个类继承nn.Moudle,之后继承nn.Moudle的初始化加上自己的初始化,最后重写forward方法。
import torch
from torch import nn
class Tudui(nn.Module):def __init__(self):super().__init__()
def forward(self, input):output = input+1return output
tudui = Tudui()
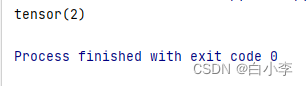
x = torch.tensor(1)
output = tudui(x)
print(output)这就是一个简单的神经网络,搭建好骨架后对其进行输入数据
总结
这周是第一次对文献展开阅读,有着许多不熟练的地方,阅读完后对整个文章的理解程度还是不够的,因此需要在阅读过程中加强对其中内容的理解以及重复阅读。除此之外,对于基本方法还需要加强学习,现在的掌握程度是远远不够的。下周计划继续阅读文献以及展开对工程项目的相关技术ASP.net.MVC的学习。
这篇关于对ANNs相关论文的阅读及PyTorch代码学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






