本文主要是介绍大数据-基础架构设施演进的过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、第一阶段-Hadoop
以Hadoop为代表的离线数据处理基础设施
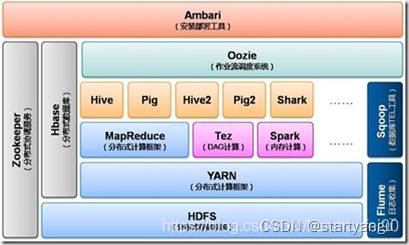
1.1、围绕HDFS和MR,产生了一系列的组件
- 面向在线KV操作的HBase
- 面向SQL的Hive
- 面向工作流的PIG
1.2、随着对批处理性能要求越来越高,产生了Tez、Spark、Flink等计算引擎。RM模型也逐步进化成DAG模型。
DAG模型
1、增加计算模型的抽象和并发能力
根据聚合操作把任务分为多个stage,每个stage由一个或者多个task组成,task可以并行执行,从而提供计算的并行能力
2、减少计算过程中的中间结果IO操作
为了减少处理过程中的中间结果写文件操作,spark、presto等计算引擎尽量使用计算节点的内存对数据进行缓存,从而提高整个计算过程中的数据效率和吞吐能力
二、第二阶段-lambda架构
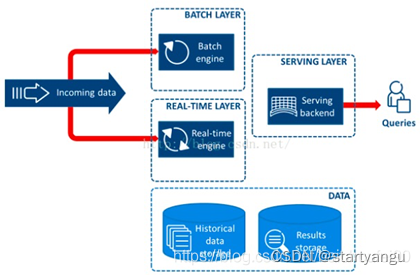
批处理计算能力提升有限了还是无法满足需求,需要结合离线和实时才能解决问题。催生了,SparkStreaming、Flink的出现。最终“流批一体”出现了。
三、第三阶段-kapa架构
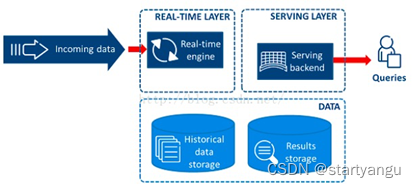
流批一体解决了问题,但是架构太复杂了,能不能用一套系统来跑就行了。流失处理天生的并发行和分布式特点,注定有更好的拓展性。通过流式计算提高并发行,加大流式计算的窗口。来统一批流程和流处理两种计算模式
这篇关于大数据-基础架构设施演进的过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







