本文主要是介绍【第六章】简单网络实现手写数字分类-编程实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
让我们编写一个程序,学习如何使用随机梯度下降和MNIST训练数据来识别手写数字。我们将通过一个简短的Python程序来实现这一点,只需要74行代码!首先我们需要获取MNIST数据。
本章代码和数据下载地址:
https://download.csdn.net/download/zhoushenghuang/88975860
顺便提一下,当我之前描述MNIST数据时,我说它被分成了60,000个训练图像和10,000个测试图像。这是官方的MNIST描述。实际上,我们将稍微不同地分割数据。我们将保留测试图像不变,但将60,000图像的MNIST训练集分成两部分:一个包含50,000图像的集合,我们将使用它来训练我们的神经网络,以及一个独立的10,000图像验证集。在本章中我们不会使用验证数据,但在书的后面,我们会发现验证数据在确定神经网络的某些超参数时非常有用——比如学习率等,这些不是由我们的学习算法直接选择的。尽管验证数据不是原始MNIST规范的一部分,但许多人以这种方式使用MNIST,而且在神经网络中使用验证数据是很常见的。从现在起,当我提到“MNIST训练数据”时,我将指的是我们的50,000图像数据集,而不是原始的60,000图像数据集。
除了MNIST数据,我们还需要一个叫做Numpy的Python库,用于进行快速的线性代数运算。
network.py
在下面提供完整代码清单之前,让我先解释神经网络代码的核心特性。中心部分是一个Network类,我们用它来表示一个神经网络。这是我们用来初始化一个Network对象的代码:
class Network(object):def __init__(self, sizes):self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
在这段代码中,列表sizes包含了各层中神经元的数量。所以,例如,如果我们想创建一个在第一层有2个神经元、第二层有3个神经元、最后一层有1个神经元的Network对象,我们可以用以下代码来实现:
net = Network([2, 3, 1])
Network对象中的偏置和权重都是通过Numpy的np.random.randn函数随机初始化的,该函数生成均值为0、标准差为1的高斯分布。这种随机初始化为我们的随机梯度下降算法提供了一个起点。在后面的章节中,我们会找到初始化权重和偏置的更好方法,但目前这样做就足够了。请注意,Network初始化代码假定第一层神经元是输入层,并且没有为这些神经元设置任何偏置,因为偏置仅在计算后面层次的输出时使用。
还要注意,偏置和权重被存储为Numpy矩阵的列表。所以,例如 net.weights[1] 是一个Numpy矩阵,存储连接第二层和第三层神经元的权重。(这里指的是第二层和第三层,而不是第一层和第二层,因为Python的列表索引是从0开始的。)由于 net.weights[1] 相对来说比较繁琐,我们就简单地将这个矩阵记作 w 。这是这样一个矩阵:其中wjk 是第二层的第k个神经元和第三层的第j个神经元之间连接的权重。j和k索引的这种排序可能看起来有些奇怪。交换j和k索引岂不是更有意义?使用这种排序的一个大优点是,它意味着第三层神经元的激活向量为:

这个等式里包含了相当多的内容,所以让我们一步步解开它。a 是第二层神经元的激活向量。为了获得 a’,我们将 a 与权重矩阵 w 相乘,并加上偏差向量 b。然后我们将函数 σ 逐元素地应用于向量 wa+b 的每一个元素。(这称为向量化函数 σ。)很容易验证,等式 (22) 得到的结果与我们早先用来计算 sigmoid 神经元输出的规则,即等式 (4),是相同的。
牢记这些,编写代码来计算网络实例的输出就变得简单了。我们首先定义 sigmoid 函数:
def sigmoid(z):return 1.0/(1.0+np.exp(-z))
注意,当输入 z 是一个向量或 Numpy 数组时,Numpy 会自动逐元素地应用 sigmoid 函数,即以向量化的形式。
我们接着在网络类中添加一个前馈方法,该方法接收网络的输入 a,并返回相应的输出。该方法所做的就是对每一层应用方程(22):
def feedforward(self, a):"""Return the output of the network if "a" is input."""for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a)+b)return a
当然,我们希望我们的 Network 对象能够学习。为此,我们将为它们提供一个实现随机梯度下降的 SGD 方法。以下是代码。有几个地方可能有些神秘,但我将在下面的清单之后进行详细解释。
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):"""使用小批量随机梯度下降训练神经网络。"training_data" 是一个包含元组 "(x, y)" 的列表,表示训练输入和期望输出。其他非可选参数都是不言自明的。如果提供了 "test_data",则网络将在每个周期后针对测试数据进行评估,并打印出部分进展。这对于跟踪进展很有用,但会大大减慢速度。"""if test_data: n_test = len(test_data)n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta)if test_data:print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)else:print "Epoch {0} complete".format(j)
training_data 是一个包含元组 (x, y) 的列表,表示训练输入和相应的期望输出。变量 epochs 和 mini_batch_size 是你期望的训练周期数和采样时使用的小批量大小。eta 是学习率η。如果提供了可选参数 test_data,那么程序将在每个训练周期后评估网络,并打印出部分进展。这对于跟踪进展很有用,但会大大减慢速度。
该代码的工作方式如下。在每个周期中,它首先随机对训练数据进行洗牌,然后将其分成适当大小的小批量。这是从训练数据中随机抽样的一种简单方式。然后对于每个小批量,我们应用一次梯度下降的单步操作。这通过代码 self.update_mini_batch(mini_batch, eta) 完成,它根据一个梯度下降的单次迭代,仅使用小批量中的训练数据来更新网络的权重和偏差。以下是 update_mini_batch 方法的代码:
def update_mini_batch(self, mini_batch, eta):"""使用反向传播,通过应用梯度下降更新网络的权重和偏置,针对单个小批量进行操作。"mini_batch" 是一个包含元组 "(x, y)" 的列表,而 "eta" 则代表学习率。"""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)]self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)]
大部分工作都由以下代码行完成:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
这会调用称为反向传播算法的东西,这是一种快速计算损失函数梯度的方法。因此,update_mini_batch 的工作原理是简单地计算小批量中每个训练样本的这些梯度,然后适当地更新 self.weights 和 self.biases。
我现在不打算展示 self.backprop 的代码。我们将在下一章中学习反向传播的工作原理,其中包括 self.backprop 的代码。现在,只需假设它按照所述行为运行,返回与训练样本 x 相关的成本的适当梯度即可。
让我们看一下完整的程序。除了 self.backprop 方法之外,该程序是不言自明的 - 所有的重活都在 self.SGD 和 self.update_mini_batch 方法中完成,而这两个方法我们已经讨论过了。self.backprop 方法利用了一些额外的函数来帮助计算梯度,即 sigmoid_prime 函数,用于计算 σ 函数的导数,以及 self.cost_derivative 函数,我不会在这里描述。通过查看代码和文档,您可以大致了解这些函数的功能(甚至是细节)。我们将在下一章中详细介绍它们。请注意,尽管程序看起来很长,但其中大部分代码都是文档,旨在使代码易于理解。实际上,该程序只包含 74 行非空白、非注释代码。
import random
import numpy as npclass Network(object):def __init__(self, sizes):"""列表 sizes 包含网络各层中的神经元数量。例如,如果列表是 [2, 3, 1],那么它将是一个三层网络,第一层包含 2 个神经元,第二层包含 3 个神经元,第三层包含 1 个神经元。网络的偏置和权重是随机初始化的,使用均值为 0、方差为 1 的高斯分布。请注意,第一层被假定为输入层,并且按照惯例,我们不会为这些神经元设置任何偏置,因为偏置仅在计算后续层的输出时使用。"""self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]def feedforward(self, a):"""如果 a 是输入,则返回网络的输出。"""for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a) + b)return adef SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):"""使用小批量随机梯度下降训练神经网络。"training_data" 是一个包含元组 "(x, y)" 的列表,表示训练输入和期望输出。其他非可选参数都是不言自明的。如果提供了 "test_data",则网络将在每个周期后针对测试数据进行评估,并打印出部分进展。这对于跟踪进展很有用,但会大大减慢速度。"""if test_data: n_test = len(test_data)n = len(training_data)for j in range(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k + mini_batch_size]for k in range(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta)if test_data:print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test))else:print("Epoch {0} complete".format(j))def update_mini_batch(self, mini_batch, eta):"""使用反向传播,通过应用梯度下降更新网络的权重和偏置,针对单个小批量进行操作。"mini_batch" 是一个包含元组 "(x, y)" 的列表,而 "eta" 则代表学习率。"""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [w - (eta / len(mini_batch)) * nw for w, nw in zip(self.weights, nabla_w)]self.biases = [b - (eta / len(mini_batch)) * nb for b, nb in zip(self.biases, nabla_b)]def backprop(self, x, y):"""返回一个元组 ``(nabla_b, nabla_w)`` 表示成本函数 C_x 的梯度。 ``nabla_b`` 和``nabla_w`` 是逐层的 numpy 数组列表,类似于``self.biases`` 和``self.weights``."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]# 前馈计算activation = xactivations = [x] # 用于逐层存储所有激活值的列表zs = [] # 用于逐层存储所有 z 向量的列表for b, w in zip(self.biases, self.weights):z = np.dot(w, activation) + bzs.append(z)activation = sigmoid(z)activations.append(activation)# 向后传播delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])nabla_b[-1] = deltanabla_w[-1] = np.dot(delta, activations[-2].transpose())'''在这里,l = 1 表示最后一层的神经元,l = 2 是倒数第二层,依此类推。在这里利用了 Python 可以在列表中使用负索引的事实。'''for l in range(2, self.num_layers):z = zs[-l]sp = sigmoid_prime(z)delta = np.dot(self.weights[-l + 1].transpose(), delta) * spnabla_b[-l] = deltanabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())return nabla_b, nabla_wdef evaluate(self, test_data):"""返回神经网络输出正确结果的测试输入数量。请注意,假定神经网络的输出是最后一层中具有最高激活的神经元的索引。"""test_results = [(np.argmax(self.feedforward(x)), y)for (x, y) in test_data]return sum(int(x == y) for (x, y) in test_results)def cost_derivative(self, output_activations, y):"""返回输出激活的偏导数向量 \partial C_x / \partial a """return output_activations - y#### 杂项函数
def sigmoid(z):"""sigmoid 函数"""return 1.0 / (1.0 + np.exp(-z))def sigmoid_prime(z):"""sigmoid 函数的导数"""return sigmoid(z) * (1 - sigmoid(z))
运行测试
这个程序对手写数字的识别效果如何呢?好吧,让我们首先加载 MNIST 数据集。我将使用一个小辅助程序 mnist_loader.py 来完成这个任务,辅助程序稍后会进行描述。我们在 Python shell 中执行以下命令:
>>> import mnist_loader
>>> training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
当然,这也可以在一个单独的 Python 程序中完成,但如果您正在跟随教程,最简单的方法可能是在 Python shell 中完成。
加载 MNIST 数据后,我们将设置一个具有 30 个隐藏神经元的网络。在这之前,我们需要导入上面列出的名为 network 的 Python 程序。
>>> import network
>>> net = network.Network([784, 30, 10])
最后,我们将使用随机梯度下降算法在 MNIST 的训练数据上进行学习,迭代 30 个周期,每个周期使用小批量大小为 10,学习率为 η=3.0。
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
请注意,如果您在阅读过程中运行代码,执行可能需要一些时间 - 对于一台典型的机器(截至2015年),运行可能需要几分钟。我建议您启动代码运行,继续阅读,并定期检查代码的输出。如果您赶时间,可以通过减少周期数、减少隐藏神经元数量或仅使用部分训练数据来加快速度。请注意,生产代码会快得多:这些 Python 脚本旨在帮助您理解神经网络的工作原理,而不是成为高性能代码!当然,一旦我们训练了一个网络,它就可以在几乎任何计算平台上非常快速地运行。例如,一旦我们学习了一个网络的良好的权重和偏置集合,它可以轻松地移植到在 Web 浏览器中运行的 Javascript,或者作为移动设备上的本地应用程序运行。无论如何,这里是神经网络的一个训练运行的输出的部分。显示了每个训练周期后神经网络正确识别的测试图像数量。正如您所看到的,仅仅经过一个周期,这个数字已经达到了10,000个中的9,129个,并且这个数字继续增长。
Epoch 0: 9129 / 10000
Epoch 1: 9295 / 10000
Epoch 2: 9348 / 10000
...
Epoch 27: 9528 / 10000
Epoch 28: 9542 / 10000
Epoch 29: 9534 / 10000
也就是说,经过训练的网络在其峰值(“Epoch 28”)达到了约 95% 的分类率 - 95.42%!作为第一次尝试,这是相当令人鼓舞的。然而,我应该警告您,如果您运行代码,您的结果不一定会和我的完全相同,因为我们将使用(不同的)随机权重和偏置来初始化我们的网络。为了在本章中生成结果,我进行了三次运行中的最佳结果的选择。
让我们重新运行上面的实验,将隐藏神经元数量改为100个。和之前一样,如果您在阅读过程中运行代码,请注意它执行起来需要相当长的时间(在我的计算机上,每个训练周期大约需要几十秒),所以在代码执行时继续阅读是明智的。
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
确实,这将结果提高到了96.59%。至少在这种情况下,使用更多的隐藏神经元有助于我们获得更好的结果。当然,为了获得这些准确度,我必须对训练的周期数、小批量大小和学习率 η 做出特定选择。正如我上面提到的,这些被称为我们神经网络的超参数,以区别于我们学习算法学习到的参数(权重和偏置)。如果我们选择超参数不当,就会得到糟糕的结果。例如,假设我们选择的学习率是 η=0.001。
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 0.001, test_data=test_data)
结果远没有那么令人鼓舞
Epoch 0: 1139 / 10000
Epoch 1: 1136 / 10000
Epoch 2: 1135 / 10000
...
Epoch 27: 2101 / 10000
Epoch 28: 2123 / 10000
Epoch 29: 2142 / 10000
然而,您可以看到随着时间的推移,网络的性能正在逐渐提高。这表明需要增加学习率,比如说将 η 增加到 0.01。如果我们这样做,就会得到更好的结果,这表明需要再次增加学习率。(如果进行了改变而使事情变得更好,尝试做更多!)如果我们多次这样做,最终我们将得到一个类似于 η=1.0(可能微调到 3.0)的学习率,这接近我们之前的实验。因此,即使我们最初选择了不良的超参数,至少我们得到了足够的信息来帮助我们改进超参数的选择。
总的来说,调试神经网络可能具有挑战性。特别是当初始超参数的选择产生的结果不比随机噪声好时。假设我们尝试之前成功的30个隐藏神经元网络架构,但将学习率更改为 η=100.0:
>>> net = network.Network([784, 30, 10])
>>> net.SGD(training_data, 30, 10, 100.0, test_data=test_data)
在这一点上,我们实际上已经走得太远了,学习率太高:
Epoch 0: 1009 / 10000
Epoch 1: 1009 / 10000
Epoch 2: 1009 / 10000
Epoch 3: 1009 / 10000
...
Epoch 27: 982 / 10000
Epoch 28: 982 / 10000
Epoch 29: 982 / 10000
现在想象一下,我们是第一次遇到这个问题。当然,我们从之前的实验中知道正确的做法是降低学习率。但是,如果我们是第一次遇到这个问题,那么输出中几乎没有任何东西可以指导我们要做什么。我们可能不仅担心学习率,还担心神经网络的每个其他方面。我们可能会想知道我们是否以一种使网络难以学习的方式初始化了权重和偏置?或者也许我们没有足够的训练数据来获得有意义的学习?也许我们还没有运行足够的周期?或者也许对于具有这种架构的神经网络来说,学习识别手写数字是不可能的?也许学习率太低了?或者,也许,学习率太高了?当你第一次遇到一个问题时,你并不总是确定的。
从中得出的教训是,调试神经网络并不是一件微不足道的事情,就像普通编程一样,这需要一种艺术。为了从神经网络中获得良好的结果,您需要学习调试的艺术。更一般地说,我们需要开发出选择好的超参数和好的架构的启发式方法。我们将在本书中详细讨论所有这些问题,包括我如何选择上述超参数。
数据加载方法
之前,我跳过了加载MNIST数据的细节。这相当简单。为了完整起见,这里是代码。用于存储MNIST数据的数据结构在文档字符串中有描述 - 这是直截了当的内容,元组和Numpy ndarray对象的列表(如果您不熟悉ndarrays,请将它们视为向量):
'''
一个用于加载 MNIST 图像数据的库。要查看返回的数据结构的详细信息,请参阅
load_data 和 load_data_wrapper的文档
在实践中,我们的神经网络代码通常调用 load_data_wrapper
'''
import pickle
import gzip
import numpy as npdef load_data():"""将MNIST数据作为一个元组返回,其中包含训练数据、验证数据和测试数据。training_data 作为一个元组返回,包含两个条目。第一个条目包含实际的训练图像。这是一个包含50,000个条目的numpy ndarray。每个条目又是一个包含784个值的numpy ndarray,表示单个MNIST图像中的28 * 28 = 784个像素。training_data 元组中的第二个条目是一个包含50,000个条目的numpy ndarray。这些条目只是元组第一个条目中包含的相应图像的数字值(0...9)。validation_data 和 test_data 类似,只是每个包含10,000张图像。这是一个很好的数据格式,但在神经网络中使用时,修改一下 training_data 的格式会更有帮助。这是在下面的包装函数load_data_wrapper()中完成的。"""f = gzip.open('./data/mnist.pkl.gz', 'rb')training_data, validation_data, test_data = pickle.load(f, encoding="latin1")f.close()return (training_data, validation_data, test_data)def load_data_wrapper():"""返回一个元组,包含(training_data, validation_data, test_data)基于load_data但格式更方便用于我们的神经网络实现。具体而言, training_data是一个包含 50,000 个 2 元组(x, y) 的列表。x是一个 784 维的 numpy.ndarray,包含输入图像。y是一个 10 维的 numpy.ndarray,表示对应于x的正确数字的单位向量。validation_data和test_data是包含 10,000 个 2 元组(x, y)的列表。在每种情况下,x是一个 784 维的 numpy.ndarray,包含输入图像,而y则是相应的分类,即与x对应的数字值(整数)。显然,这意味着我们对训练数据和验证/测试数据使用了稍微不同的格式。这些格式在我们的神经网络代码中使用起来最方便。"""tr_d, va_d, te_d = load_data()training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]training_results = [vectorized_result(y) for y in tr_d[1]]training_data = zip(training_inputs, training_results)validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]validation_data = zip(validation_inputs, va_d[1])test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]test_data = zip(test_inputs, te_d[1])return (training_data, validation_data, test_data)def vectorized_result(j):"""返回一个10维单位向量,其中第j个位置为1.0,其他位置为零。这用于将一个数字(0...9)转换为神经网络的相应期望输出。"""e = np.zeros((10, 1))e[j] = 1.0return e后话
我上面说我们的程序获得了相当不错的结果。这是什么意思?与什么相比好?与一些简单的(非神经网络)基准测试进行比较是有益的,以了解何为表现良好。当然,最简单的基准测试是随机猜测数字。那大约有十分之一的机会是正确的。我们的表现比这好多了!
让我们尝试一个非常简单的想法:我们将看一下图像有多暗。例如,数字2的图像通常会比数字1的图像要暗一些,因为更多的像素被涂黑,如下面的例子所示:

这表明我们可以使用训练数据来计算每个数字(0、1、2、…、9)的平均暗度。当出现新图像时,我们计算图像的暗度,然后猜测它是哪个数字的平均暗度最接近。这是一个简单的过程,很容易编写代码,所以我不会明确写出代码 - 如果您感兴趣,可以在GitHub存储库中找到。但这比随机猜测要好得多,正确识别了10,000个测试图像中的2,225个,即22.25%的准确率。
可以找到其他想法,其准确率在20%到50%的范围内。如果你再努力一点,就可以提高到50%以上。但要获得更高的准确率,最好使用成熟的机器学习算法。让我们尝试使用最知名的算法之一,支持向量机(Support Vector Machine,SVM)。如果您对SVM不熟悉,不用担心,我们不需要理解SVM的详细工作原理。相反,我们将使用一个名为scikit-learn的Python库,它提供了一个简单的Python接口,用于访问名为LIBSVM的C库。
如果我们使用scikit-learn的SVM分类器默认设置运行,则它可以正确识别10,000个测试图像中的9,435个。这比我们基于图像暗度的天真方法要好得多。事实上,这意味着SVM的性能与我们的神经网络大致相同,只是稍微差一些。在后面的章节中,我们将介绍新的技术,使我们能够改进我们的神经网络,使其性能远远优于SVM。
然而,故事还没有结束。9,435个正确识别的10,000个结果是基于scikit-learn的SVM默认设置。SVM有一些可调参数,可以搜索参数来提高默认性能。事实表明,通过一些工作来优化SVM的参数,可以将性能提高到98.5%以上的准确率。换句话说,一个调整良好的SVM只会在大约70个数字中出现一个错误。这相当不错!神经网络能做得更好吗?
事实上,可以。目前,设计良好的神经网络在解决MNIST问题时胜过了所有其他技术,包括SVM。2013年的记录是正确分类10,000个图像中的9,979个。这是由李万(Li Wan)、马修·泽勒(Matthew Zeiler)、张思鑫(Sixin Zhang)、杨立春(Yann LeCun)和罗布·费格斯(Rob Fergus)完成的。我们将在本书的后面看到他们使用的大部分技术。在这个水平上,性能接近于人类水平,甚至可以说更好,因为其中许多MNIST图像即使对于人类来说也很难有信心地识别,例如:
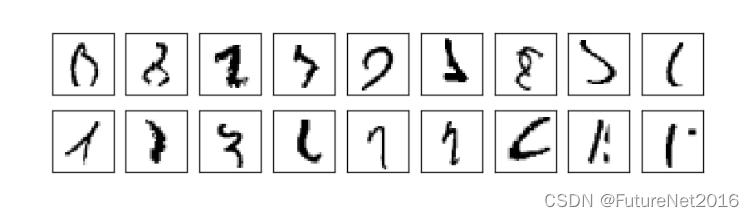
我相信您会同意这些图像很难分类!在MNIST数据集中有这样的图像,神经网络能够准确地对除了10,000个测试图像中的21个之外的所有图像进行分类,这是非常了不起的。通常,在编程时,我们相信解决诸如识别MNIST数字这样复杂的问题需要一个复杂的算法。但是即使是李万等人提到的神经网络也涉及相当简单的算法,是本章中我们所看到的算法的变种。所有的复杂性都是自动从训练数据中学到的。在某种意义上,我们的结果以及更复杂的论文中的结果是,对于某些问题:
复杂的算法 ≤ 简单的学习算法 + 良好的训练数据。
这篇关于【第六章】简单网络实现手写数字分类-编程实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






