本文主要是介绍GitHub:HairCLIP AI换发型 项目部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过文本和参考图像设计你的头发(CVPR2022)

HairCLIP是在2022年3月发布的,它是基于StyleCLIP改进的,StyleCLIP是一种用文本换发型的项目,比如输入文本:长发、短发、刘海、卷发等等,就能生成对应发型图片,但很多发型不好准确的描述出来,所以HairCLIP在文本的基础上增加了参考图片,也就是可以同时用文本描述+参考图片的方式训练,它的优点是处理图片速度很快,几秒钟一张,缺点是只支持固定的几种发型,可选项有限,虽然官方说可以从头训练自己的发型库,但我还没训练成功。
GitHub地址(需翻墙):
GitHub - wty-ustc/HairCLIP: [CVPR 2022] HairCLIP: Design Your Hair by Text and Reference Image
demo演示地址:
wty-ustc/hairclip – Run with an API on Replicate
Google Colab地址(需翻墙):
https://colab.research.google.com/github/kaz12tech/ai_demos/blob/master/HairCLIP_demo.ipynb#scrollTo=uoREcCRMjiNk
前期准备
百度网盘:https://pan.baidu.com/s/1RtDLCAlFShF2ugCrptp4ug?pwd=3mu2
提取码:3mu2
外网实在太慢,我把整个项目的代码,以及辅助模型全部保存到了百度网盘里,此版本为2022.03.19发布的,3G大小,请先下载;另外此代码中有部分细节改动,是为了解决官网下载的代码直接跑会有各种未知报错(环境、版本、冲突等),此代码在下方云服务器上调试可完全跑通。

服务器租赁
这个项目需要搭建环境有python3.8、pytorch1.9.1、cuda11.1、cuDNN8.0.5、Anaconda等等,如果你的目的是为了跑通这个项目,不值当霍霍自己的笔记本,我建议直接花5毛钱,租一个集成好各种环境的GPU服务器,能让你省下不少和环境问题纠缠的时间。
矩池云官网:矩池云 - 专注于人工智能领域的云服务商
首先注册一个矩池云账号,然后选一台GPU服务器 NVIDIA Tesla K80
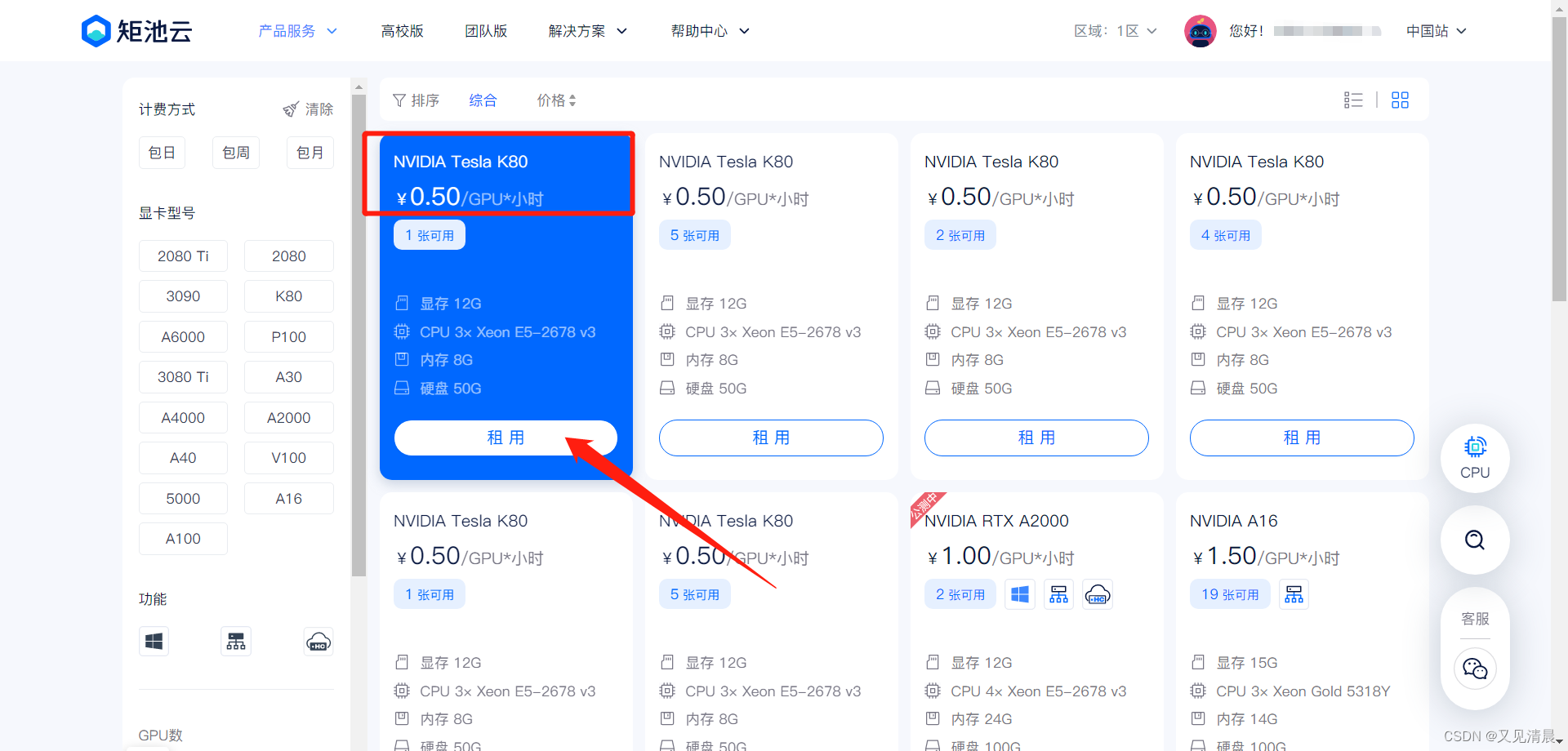
选择系统镜像:pytorch1.9.1

用你的Xshell和FTP远程连上就可以使用了
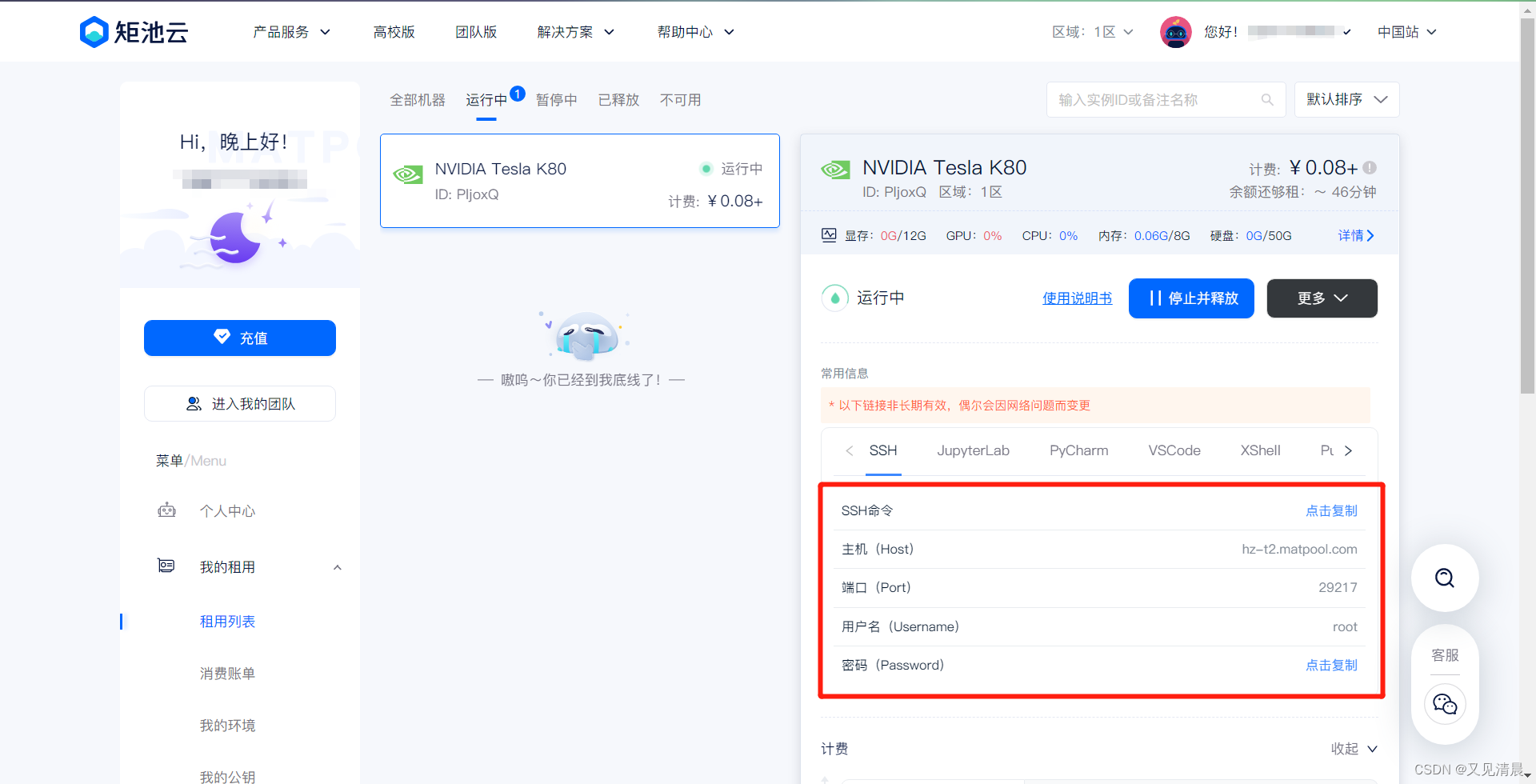
如果没有这两个远程工具的可以下载
百度网盘:https://pan.baidu.com/s/1lK5slEaKi5VaQgFR_KcRmQ?pwd=qsha
提取码:qsha

导入项目
1. 连接FTP,将压缩包 ①CLIP.zip ②encoder4editing.zip ③HairCLIP.zip ④ninja-linux.zip ⑤path.zip上传至/home/下
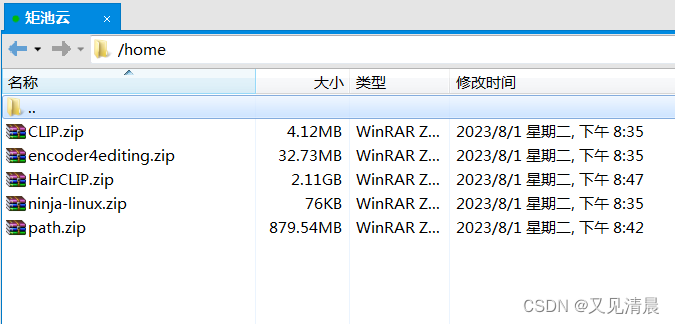
2. 连接Xshell,运行以下命令解压项目
cd /home # 项目目录
unzip HairCLIP.zip # 解压缩
unzip encoder4editing.zip
unzip path.zip -d /
unzip ninja-linux.zip -d /usr/local/bin/
update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force # 多版本切换
pip install CLIP.zip # 安装CLIP包3. 删除压缩包
rm -f /home/HairCLIP.zip
rm -f /home/encoder4editing.zip
rm -f /home/path.zip
rm -f /home/ninja-linux.zip
rm -f /home/CLIP.zip安装依赖
pip install ftfy regex tqdm
pip install tensorflow-io
pip install tensorboard
pip install --upgrade --no-cache-dir gdown
pip install imgaug
pip install cog
conda install -c conda-forge dlib运行项目
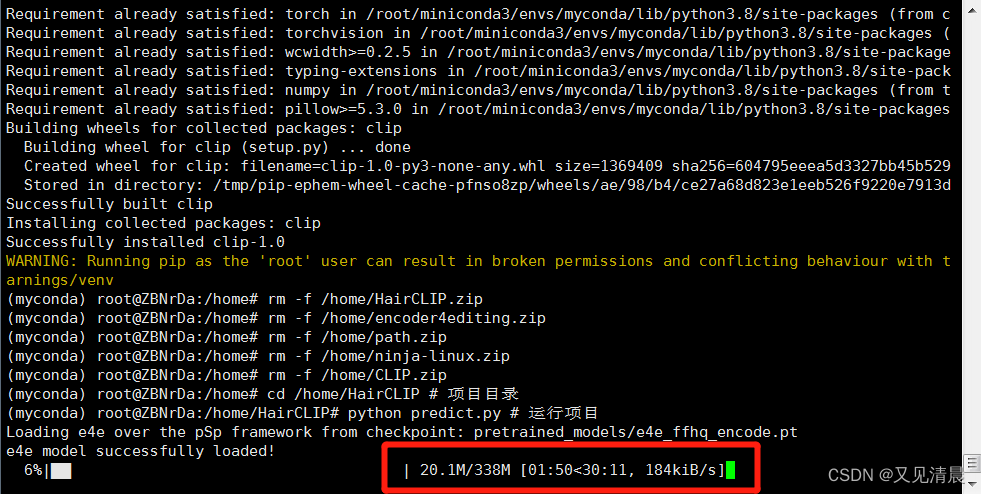
1. 运行项目
cd /home/HairCLIP # 项目目录
python predict.py # 运行项目第一次运行项目时会下载一个338M的模型,耗时30分钟—1小时,第二次运行时就不会下载了。
运行完的结果将会出现在/home/HairCLIP/output/下,如果要调整目标人脸、发型、颜色等参数可以在predict.py文件的predict()方法里按注释修改对应代码(官方代码没有注释,我自己加的注释)

目标人脸(左),融合人脸(右)
到此项目就算跑通了,建议此时保存环境,下次调试可以直接读档,不需要重新部署。

模型测试
运行测试代码(仅以参考图片改变发型),模型测试的目的主要为了体验预训练模型的效果,它会对接人脸数据集给你生成一大堆换发后的示例图像,用来测试(演示)模型能力;
参数详细注释 /home/HairCLIP/mapper/options/test_options.py
参考图片目录 /path/to/celeba_hq_train
结果输出目录 /path/to/experiment
注意:每次运行测试代码,都会创建一个/path/to/experiment目录,运行代码前须保证没有这个目录,否则会报错目录已存在
cd /home/HairCLIP/mapper
python scripts/inference.py \
--exp_dir=/path/to/experiment \
--checkpoint_path=../pretrained_models/hairclip.pt \
--latents_test_path=/path/to/test_faces.pt \
--editing_type=hairstyle \
--input_type=image \
--hairstyle_ref_img_test_path=/path/to/celeba_hq_val \
--num_of_ref_img=1从运行结果可以看出,使用参考图像生成的发型并不理想,并且面部ID有改变,我猜测可能是作者发布的预训练模型只支持训练好的几款固定发型(固定发型可参考官网demo),而对陌生的参考图片拟合度不高。

目标人脸(左),融合人脸(中),参考人脸(右)
模型训练
运行训练代码(仅以参考图片改变发型),模型训练的目的主要是为了从头训练自己的发型库,调整好训练参数,它会对接人脸数据集开始训练,并实时生成训练结果图片,同时在原模型的基础上迭代更新神经网络
参数详细注释 /home/HairCLIP/mapper/options/train_options.py
参考图片目录 /path/to/celeba_hq_train
结果输出目录 /path/to/experiment
注意:每次运行训练代码,都会创建一个/path/to/experiment目录,运行代码前须保证没有这个目录,否则会报错目录已存在
cd /home/HairCLIP/mapper
python scripts/train.py \
--exp_dir=/path/to/experiment \
--hairstyle_description="hairstyle_list.txt" \
--color_description="purple, red, orange, yellow, green, blue, gray, brown, black, white, blond, pink" \
--latents_train_path=/path/to/train_faces.pt \
--latents_test_path=/path/to/test_faces.pt \
--hairstyle_ref_img_train_path=/path/to/celeba_hq_train \
--hairstyle_ref_img_test_path=/path/to/celeba_hq_val \
--color_ref_img_train_path=/path/to/celeba_hq_train \
--color_ref_img_test_path=/path/to/celeba_hq_val \
--color_ref_img_in_domain_path=/path/to/generated_hair_of_various \
--hairstyle_manipulation_prob=1 \
--color_manipulation_prob=0 \
--both_manipulation_prob=0 \
--hairstyle_text_manipulation_prob=0 \
--color_text_manipulation_prob=0 \
--color_in_domain_ref_manipulation_prob=0 \这是我训练了4万次的结果(NVIDIA GeForce RTX 2080 1元每时 共7小时),刘海在1万次以内就差不多定型了,但是两鬓是一点也不收敛呀,另外也尝试过文字描述+参考图片一起训练,文字内容:“ponytail hairstyle”(马尾辫发型);一丁点效果都没有,目前炼丹进度卡在此处,欢迎大家集思广益。


目标人脸(左),融合人脸(中),参考人脸(右)
这篇关于GitHub:HairCLIP AI换发型 项目部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







