本文主要是介绍CXL-Enabled Enhanced Memory Functions——论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
IEEE Micro 2023 Paper CXL论文阅读笔记整理
问题
计算快速链路(CXL)协议是系统社区的一个重要里程碑。CXL提供了标准化的缓存一致性内存协议,可用于将设备和内存连接到系统,同时保持与主机处理器的内存一致性。CXL使加速器(例如,GPU和DPU)既能直接加载/存储对主机存储器的访问,又能使它们自己的设备上存储器同样可由CPU访问。CXL允许在内存数据平面上插入技术,所以它允许将功能实现到内存子系统中的可能性。
本文方法
本文中介绍了增强内存功能(EMF)的概念。描述了两个用例,其中一个使用基于现场可编程门阵列(FPGA)的智能存储控制器平台实现原型。
有效的EMF将利用以下一个或多个属性来实现其功能:(1) 接近内存介质本身。(2) 能够在数据平面上插入内存读/写命令。(3) 主机处理器缓存层次结构外部。(4) 独立于主机ISA限制。(5) 与虚拟内存子系统分离。(6) 能够与主机处理器复合体进行交互,以保持数据一致性。
设想的EMF:

访问热图
访问热图提供了更好的源数据,操作系统和管理程序可以使用这些数据来决定数据应该放在多个内存设备的何处。
CXL的使用带来了异构内存域,这些异构内存可能具有不同的容量、性能(延迟、带宽)、能耗和耐久性(寿命)特性,因此需要仔细管理数据的放置。例如对内存页进行预测,区分冷热页,将热页放置到性能更高的存储设备。
现有方法包括:页表监视、内存访问采样、性能计数器,但在CXL场景下,增加总容量和内存硬件共享会带来更高的性能开销。
图3展示了如何实现访问热图EMF。应用程序发送注册感兴趣的地址范围和跟踪参数的配置命令。读写请求照常进行。IMC识别被监视的地址,并增加存储在控制器芯片或存储器的保留部分中的读写计数器(元数据)。主机可以根据需要读取或重置计数器,该主机运行页面调度策略并协调迁移。
分开跟踪读取和写入很重要,因为读取延迟通常对性能更具影响,而写入可能会导致NVM磨损,因此会有不同的处理方式。这种组织下,IMC与存储器芯片接近,减少了更新访问计数器所需的CXL链路上的带宽需求,并以尽可能低的延迟利用了完整的内部设备带宽。该设备还可以将访问计数器的操作与实际数据路径重叠,从而不存在性能损失。

内存回滚
内存回滚允许在崩溃一致的版本中使用具有持久内存的未经修改的软件库。与仅使用软件实现崩溃一致性的方法相比,它还显著减少了写入放大。
现有方法的问题:
-
使用编译器的指令实现崩溃一致性,现有的持久存储器编程框架需要有效地重写应用程序代码,以使用框架的数据结构和控制接口。
-
使用软件实现崩溃一致性,在内存使用和性能方面都非常昂贵。对于树和哈希图数据结构,持久化和日志记录一起会导致63%-72%的插入性能开销和61%-68%的删除性能开销。
本文的回滚EMF设计基于识别与事务相关联的内存区域,采用微堆,以更精细的粒度管理堆内存。
IMC的回滚功能(图5)通过三种方式增强了正常的控制器功能:(1)跟踪其任何缓存行在主机缓存中处于修改状态的可能性;(2) 响应回滚事务启动和停止请求;(3)执行高速缓存行写入的在线处理。
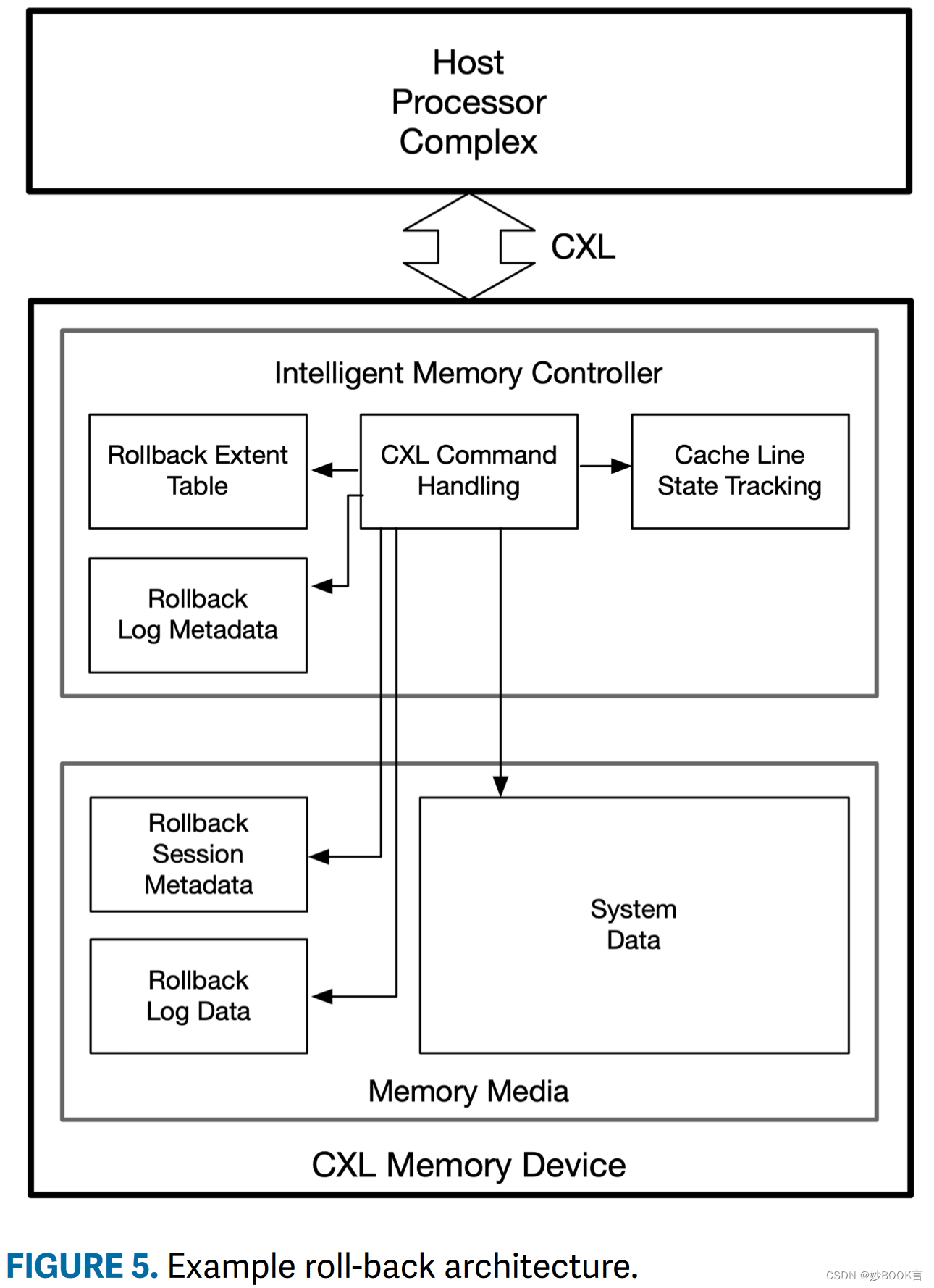
基于FPGA实现,实验结果表明,EMF回滚优于软件解决方案。
总结
介绍了增强内存功能(EMF)的概念,提供了如何在智能内存控制器(IMC)中实现两个用例(访问热图和内存回滚)的EMF。本质来说是利用近数据处理的思路,在CXL设备端通过IMC获取更多数据,例如访问跟踪、缓存行状态,并响应来自主机的请求,实现更高的性能。
提出了EMF设计思路,利用以下一个或多个属性来实现其功能:(1) 接近内存介质本身。(2) 能够在数据平面上插入内存读/写命令。(3) 主机处理器缓存层次结构外部。(4) 独立于主机ISA限制。(5) 与虚拟内存子系统分离。(6) 能够与主机处理器复合体进行交互,以保持数据一致性。
这篇关于CXL-Enabled Enhanced Memory Functions——论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)