本文主要是介绍为什么要用scrapy爬虫库?而不是纯python进行爬虫?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么要用scrapy爬虫库?而不是纯python进行爬虫?
- Scrapy的优点
- Scrapy节省的工作
- 使用纯Python编写爬虫的不足
Scrapy是一个使用Python编写的开源和协作的web爬虫框架,它被设计用于爬取网页数据并从中提取结构化数据。Scrapy的强大之处在于其广泛的功能和灵活性,可以让开发者高效地构建复杂的爬虫。下面是Scrapy的一些优点,以及它帮我们节省的工作和使用纯Python编写爬虫的潜在不足之处。
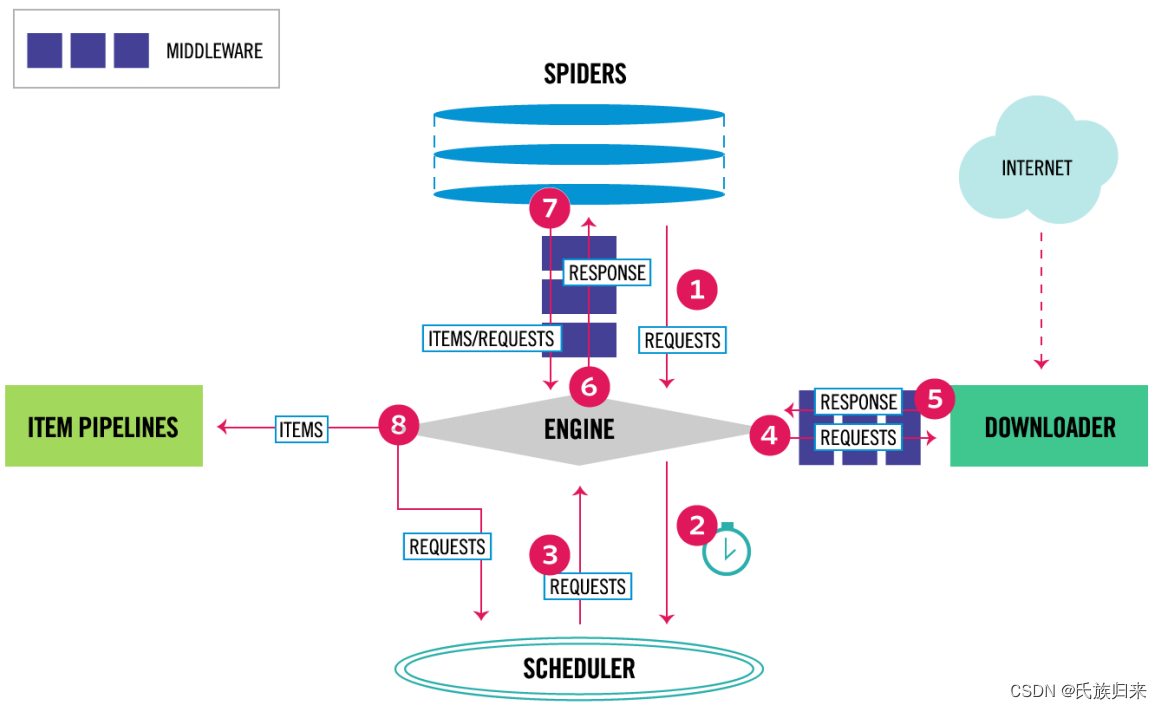
Scrapy的优点
- 内置的项目结构:Scrapy提供了一个清晰、易于管理的项目结构,这让开发、测试和部署爬虫变得更加简单和高效。
- 强大的选择器:它内置了对XPath和CSS选择器的支持,让提取数据变得非常简单和直观。
- 中间件和插件系统:Scrapy有一个灵活的中间件和插件系统,允许开发者自定义和扩展框架的功能,例如处理请求、响应、项目管道等。
- 内置的并发处理:Scrapy使用Twisted异步网络框架来处理网络通信,能够实现高效的并发请求,显著提高爬虫的抓取效率。
- 强大的抓取控制:提供了强大的抓取控制功能,包括自动重试、数据下载延迟、遵守robots.txt协议等。
- 易于扩展:可以轻松添加新的功能,如扩展项、管道和中间件。
- 数据导出:Scrapy可以轻松将抓取的数据导出到多种格式,如CSV、JSON、XML等。
Scrapy节省的工作
- 自动化请求调度和处理:Scrapy自动处理请求的发送、接收以及回调函数的调用,无需手动管理网络连接和数据流。
- 错误处理和重试机制:自动处理网络请求的错误,并且可以配置重试机制,降低临时网络问题对爬虫的影响。
- 遵循robots.txt策略:Scrapy可以配置为自动识别并遵守目标网站的robots.txt文件,减少手动检查的需要。
- 数据提取和处理的便利性:提供了强大的工具来提取和处理数据,减少了编写解析代码的复杂度。
- 高级功能的实现:如Cookies和Session的管理、用户代理的设置等,这在使用纯Python实现时可能需要大量的工作。
使用纯Python编写爬虫的不足
- 开发效率:不使用Scrapy等框架,开发同等功能的爬虫通常需要更多的时间和代码。
- 错误处理和稳定性:需要手动实现错误处理和重试逻辑,这可能导致代码更加复杂和难以维护。
- 并发处理:实现高效的并发或异步请求处理可能相对困难,需要对异步编程有深入的理解。
- 功能丰富性:自己编写可能难以快速实现Scrapy提供的一些高级功能,如中间件、信号等。
总的来说,Scrapy提供了一个高效、灵活且功能丰富的环境,大大减少了开发高性能爬虫所需的工作量。虽然使用纯Python也能实现相同的功能,但往往需要更多的时间和精力去处理底层的细节问题。
这篇关于为什么要用scrapy爬虫库?而不是纯python进行爬虫?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




