本文主要是介绍【案例】英大财险数据整合的背后,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着IT信息化大潮的不断发展,企业的信息化发展经历了逐步发展、逐渐成熟的过程。但后期都会一个这样的现状——随着业务的增多、系统的增多,在管理上的难度上也大大增加;从另一方面,数据的孤岛效应也越发的明显。越来越多的用户都希望能将计算资源、存储资源和数据库资源都能集中统一的进行管理,资源“池化”也成了信息化发展的一个新的理念和需求。
在国内,保险行业发展尤其迅速,各类信息化系统不断推陈出新,系统规模越来越庞杂,日常的IT系统运维开销越来越大,运营压力也在不断增大。在保险行业的先行者英大财险意识到自身如果不做出调整,在今后肯定会大大限制自身的发展规模。所以,英大财险提出,需要将自身的IT架构逐渐统一化、集中化,让各系统不再独立,而是集中统一进行运维管理。这将极大的提升软硬件的运营效率,降低运维压力。
通过对资源的统一管理和集中利用可以:
节省投资,减少重复的资源投入,提高资源利用率;
避免各业务系统成为一个个的烟囱式的信息孤岛,降低了建设成本、运维成本和维护压力;
集中统一管理能够在整体上统筹业务系统的部署和发展。
对于这次成功的数据整合项目,我们有幸邀请到了英大财险信息技术部总经理助理朱建华和信息技术部运行维护处运维经理胡少华,让他们来讲述一下项目背后的故事。
整合的方案
“英大财险现有Oracle数据库将近30套,主要运行于两个平台和3种操作系统之上;数据库版本基本上为Oracle 10g,也有9i的版本,小版本则各有不同;各库的用户总数将近100个(不包括系统用户)。"朱总说。
"根据目前英大财险的业务系统情况和项目预期,要将所有数据库变成3套RAC数据库,这3套RAC的所有节点将共同承担外部业务访问,同时通过将不同的数据库进行适当schema模式合并,集中把库构建在新的Oracle RAC架构下,消除目前存在的单点故障现象,并增强了系统的安全性和延续性。"
由于涉及到的业务系统有数十个之多,整合起来无疑有很大难度,因此必须从多方面考虑,精心准备:
安全
多个业务系统的数据集中存放在同一套物理库中,数据的安全防范必须考虑。因此,细化权限管理,减少不必要的高级别角色、权限的授予,考虑适当使用专用登陆用户(不包含对象的用户)等方法,都是减少数据访问风险的重要手段。
性能
多套系统运行在一套物理库中,是否相互会产生性能影响,会在哪些资源上产生竞争,这些都应该在整合的生产系统上线前进行分析和处理。简单说,根据业务情况预估充足的硬件资源、充分全面的多业务性能测试和优化,是确保性能良好的关键。
稳定
复杂的业务需求意味着对系统稳定性要求更高,结合业务特性对数据库的架构、配置、软硬件特性进行规划设计,而不是简单的参照文档安装。这对于提升业务系统的健壮性和稳定性有很大的帮助。
资源需求
集中系统的数据量和并发量都将成倍增加,硬件资源必须满足需求,因此硬件配置选型应结合业务峰值需求和业务增长特性进行评估,硬件的估算应具备足够的前瞻性,满足整合后多业务增长的需求。
维护影响
多套系统运行在同一个物理库上,数据库的一次重启将造成所有系统的影响,因此,在选择整合系统时必须考虑哪些系统更适合整合在一起,同时在规划数据库配置时,也应考虑尽量将各种维护需求和维护任务能够在线执行,确保维护操作对各系统带来的大影响。
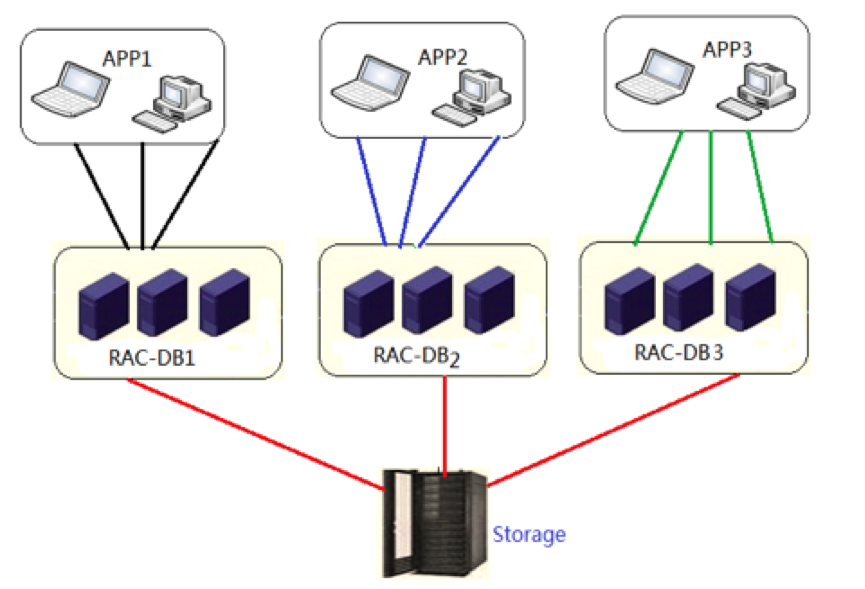
整合后的基本框架
整合前后的性能对比
英大财险运行维护处运维胡经理是本次迁移升级项目的现场指挥,据他介绍,将不同的数据库以schema的方式进行适当合并,通过对于整体统一化管理,可以大大提高硬件资源利用率,同时也增加了对数据库系统的可管理性和可维护性。
Oracle RAC技术可消除目前存在的单点故障现象。原先,每套数据库都运行在一个独立主机上面,如一个节点发生故障宕机,那这个业务系统将会受到很大影响。现在即便有一个节点发生了故障,那么通过RAC技术,另一个节点能快速的接管所有故障节点的连接,并继续对外提供服务,这对于增强系统的安全性和连续性具有很好的帮助作用。
相对于原来的资源利用率上面,一个主机上只运行一个数据库,尤其是对于那些数据库压力不大的业务系统,会导致主机资源的严重浪费。现以新旧的硬件组合的方式来共同组成新的集群环境,能大大利用其硬件资源空间,减少对资源的闲置状态,同时也能共同面对对未来的数据增长带来的压力。
负责本次迁移升级项目的云和恩墨公司项目经理罗晓程展示了两幅性能图表,他说,“每个新的RAC集群会有三个节点来承担所有的业务压力,硬件是以性能较好的IBM X3850或HP DL580 G7(也和旧机器混合使用)组成”。
下面展示了两幅性能图表:其中DB Time技术指标是衡量业务系统中在数据库层面上花费了多少时间,也能反映出数据库的繁忙以及负载程度。当然,在同等业务负载的情况下,DB Time越低则意味着数据负载相比较原来小。从迁移前后两幅图标的对比可以看出,迁移前DB Time的平均使用为10-15小时左右,而迁移后降为平均1小时左右,也就意味着承载负载数据库服务压力的效率提升大约10倍左右。整合后的集群数据库负载预计如下:(以其中一套RAC-DB2为例进行说明,其他两个负载都类似,都接近当前总负载的1/3,不再一一列举)
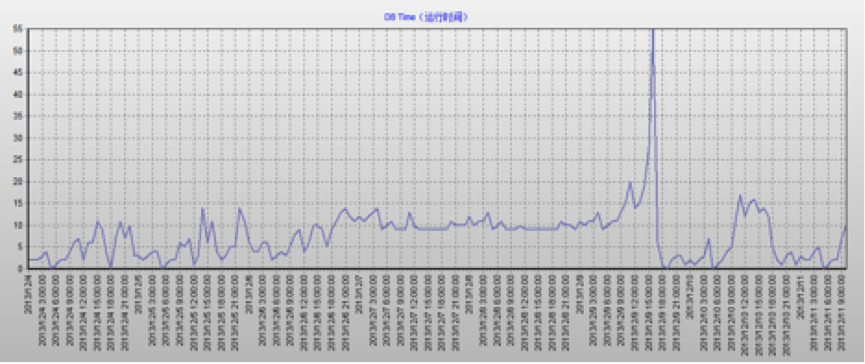
整合前的DB TIME趋势图
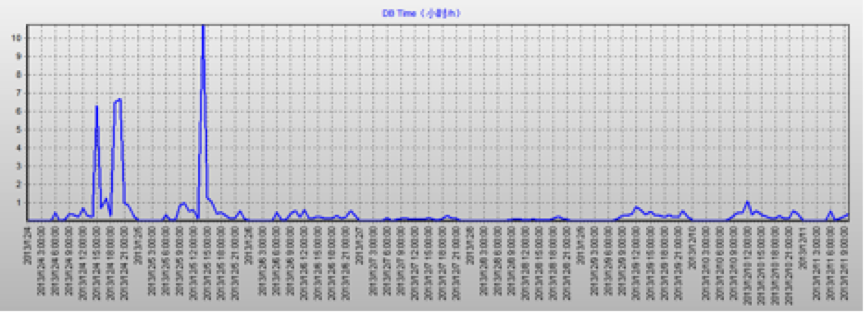
整合后的(RAC DB-2)DB TIME趋势图
企业为什么要重视数据整合?
在如此复杂的环境下,企业为什么要关注数据整合,更确切来说,是重视自身的发展需求。无论是在获取新客户,保留现有客户还是提升自身生产率,这都是与企业的业务增长和营收绩效息息相关的。重视自身发展需求的企业,都是很具有很高忧患意识的企业,这对于企业的发展壮大来说,都是必不可少的要素。
云和恩墨对于这次成功实施了英大财险这套数据整合方案表示,我们帮助客户做数据整合的目标并不仅是简单地满足客户的需求,而是会思考着怎样才能为客户创造出利润,这是我们长久发展的立足需求点。
我们应以小及大的看到问题本质:企业要重视自己的发展需求,并能真实的落地项目,企业才会走的更远。

云和恩墨
国内数据服务行业领导者
整合·优化·咨询
联系我们
电话:010-59003186-8019
邮件:marketing@enmotech.com
配图来源于网络,想了解更多云和恩墨成功案例,请点击阅读原文。
这篇关于【案例】英大财险数据整合的背后的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





