本文主要是介绍520情人节,不懂送女朋友什么牌子的口红?没关系!Python 数据分析告诉你,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、案例说明
1、案例背景
520情人节,不懂送女朋友什么牌子的口红?没关系!Python 数据分析告诉你。
我们爬取了京东商城口红近 4000 条口红商品信息,并对这些口红数据进行分析,让大家买口红给女朋友时有个选择的参考,从如下几个方面去分析:
1、哪些价格区间的口红卖的最好?
2、口红销量分布情况。
3、销量前10的口红有哪些?
4、销量前10的店铺。
5、商品价格和销量的关系。
文末领取全套最新Python学习资源!
2、任务说明
通过 Python 爬虫爬取了京东上所有口红铺的数据集 jd_data.csv。
我们希望通过该数据集,针对不同的口红品牌和店铺进行统计与分析,从而能够解开我们上述疑问。
3、数据字段的说明
字段含义图:

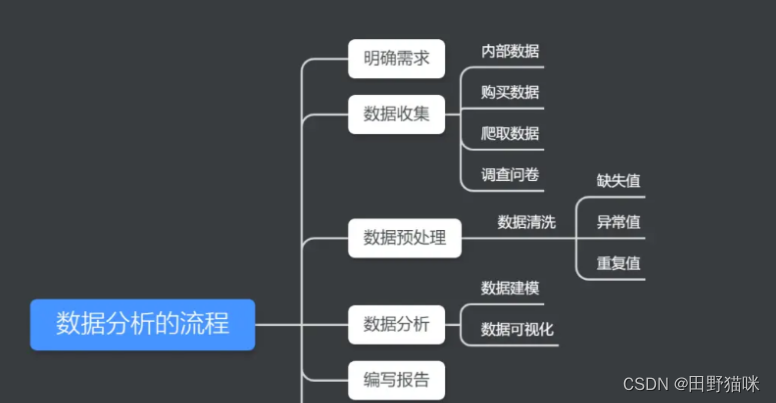
4、数据分析的流程
二、数据预处理
数据清洗
1、首先从csv文件中导入数据
python复制代码import pandas as pd
import matplotlib.pyplot as plt #读取数据
dataframe = pd.read_csv('jd_data.csv',encoding = 'gb18030')#这里不能使用utf-8
print(dataframe.shape)
查看下有多少行、列数据:
(3816, 6)
共有3816行,6列(上面有这六个字段说明)
2、缺失值处理
kotlin复制代码data = dataframe.dropna(how='any')
data.head()
print(data.shape)
(3610, 6)
从这里可以看出还是有些缺失值的
对于缺失值的处理主要有两种方法:
删除
填充:分为均值、中位数、众数、附近值进行填充,还有牛顿差值法等等。
这里偷一下懒,使用比较简便的删除的方式处理缺失值,毕竟缺失的不是很多。
ini复制代码# inplace=True表示原地修改数据集
data.dropna(axis=0, inplace=True) # 对删除后缺失值后的数据集,再次进行缺失值统计
data.isnull().sum(axis=1)
数据转换
1、将评论的+和万字修改
scss复制代码def dealComment(comm_colum):num = str(comm_colum).split('+')[0]if '万' in num:if '.' in num :num = num.replace('.','').replace('万','000')else:num = num.replace('.','').replace('万','0000')return num
dataframe['comment'] = dataframe['comment'].apply(lambda x: dealComment_num(x))
#转换成int类型
dataframe['comment'] = dataframe.comment.astype('int')
data = dataframe.drop('comment',axis = 1)
print(data.head(10))
经过处理完后的数据:

数据预处理是数据分析的一项重要任务,能否得到准确的数据分析结果离不开数据预处理,下面我们开始对口红数据进行分析吧!
文末领取全套最新Python学习资源!
三、数据分析
京东上面商品没有销量这一信息,我们姑且将评论数当成是销量。
本次项目中取用了 name、price、comment、shop_name 、shop_type 这几个字段的信息。
分别是商品标题名称、价格、评论数、店铺名、店铺类型来进行分析。
1、口红价格分布区间
ini复制代码import pandas as pd
import matplotlib.pyplot as plt#读取数据
data = pd.read_csv('jd_data.csv',encoding = 'gb18030')plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure(figsize=(10,8))
price = data[data['price'] < 1000]
plt.hist(price['price'], bins=10, color='brown')
plt.xlabel('价格')
plt.ylabel('商品数量')
plt.title('价格商品分布')
plt.show()
结果如下:

通过上图,可以很清楚看到:
- 口红的价格绝大多数在0-500元的区间之内,但是也有口红的售价达到了1000元,哈哈努力挣钱吧。
- 其中200-300元价位的数量非常的高,超过了1200,而且价格超过300元的有明显的减少趋势,哈哈价格才是王道。
2、销量分布情况
由于没有爬取到销量信息,所以将评论数当成销量
ini复制代码#销量分析
sale_num = data[data['comment'] > 100]
plt.figure(figsize=(10,8))
#print(len(sale_num)/len(data)) #查看下大致的区间分布
plt.hist(sale_num['comment'], bins=20, color='blue')
plt.xlabel('销量')
plt.ylabel('数量')
plt.title('销量情况')
plt.show()
结果如下:

通过直方图我们可以看到:
- 销售量基本是在20万以内。
- 销售量在10万以内的占了绝大多数
- 还有极个别的店铺销量竟然超过了100万
3、销售前10的口红
scss复制代码#销售前10的口红
#抽取商品标题的简略信息
def get_title(item):title = item.split(' ')[0]return titledata['small_name'] = data['name'].apply(lambda x: get_title(x))
data1 = data.drop('name',axis = 1)
top10Lipstick = data1.sort_values('comment',ascending=False)
print(top10Lipstick.head(10))
title = top10Lipstick['small_name'][:10]
sale_num = top10Lipstick['comment'][:10]
plt.figure(figsize=(10,8),dpi = 80)
plt.bar(range(10),sale_num,width=0.6,color='red')
plt.xticks(range(10),title,rotation=45)
#plt.ylim((9,9.7)) #设置y轴坐标
plt.ylabel('数量')
plt.xlabel('标题')
plt.title('销量前10的糖果')
for x,y in enumerate(list(sale_num)): plt.text(x,float(y)+0.01,y,ha='center')
结果如下:
文末领取全套最新Python学习资源!


可以发现,排名前三位的是:
- 京东国际魅可(MAC)经典唇膏 子弹头口红3g Chili 小辣椒色
商品图片

- 【520礼物】中国风口红套装礼盒女颐和园同款唇膏唇釉学生非小样彩妆 口红套装(6支)
商品图片

- 【520礼物】迪奥(Dior)烈艳蓝金唇膏-哑光999# 3.5g 传奇红(口红 正红色 传奇红 赠精美礼盒)
商品图片

4、销量前10的店铺
分析完销量前10的商品后,我们再来看下销量前10的店铺:
代码如下:
scss复制代码#销量前10的店铺
top_shop = data.groupby('shop_name')['comment'].sum().sort_values(ascending=False)[:10]
print(top_shop.head(10))plt.figure(figsize=(10,8),dpi = 80)
top_shop.plot(kind = 'bar',color='red',width= 0.6)
plt.ylabel('数量')
plt.xlabel('店铺名')
plt.title('销量前10的店铺')
plt.xticks(rotation=45)
for x,y in enumerate(list(top_shop)): plt.text(x,float(y)+0.1,y,ha='center')
plt.show()
结果如下:

由上图可以看到:
- MAC魅可海外自营专区 占据第一名,达 1365308 的销售量,而且基本前10的店铺销量都在5万以上。
- 前三名都基本达到了130多万
- 前10名中有5个是京东自营
5、商品价格和销量的关系
我们采用散点图的方式,看看价格和销量的分布关系
kotlin复制代码plt.figure(figsize=(10,8))
plt.scatter(data['price'],data['comment'], color='blue')
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('价格、销量的散点分布')
plt.show()
结果如下:

可以看出:
随着价格的升高销量会减小,而且价格在400内,对销量的影响不大,证明绝大多数人的口红消费区间在0-400元之间,但是最贵的竟然达到了近1700元,哈哈,贫穷限制了我的想象。
四、总结
经过这次小小的数据分析,还是学到了许多的。作为一名小白,还有许多要学习:
- 数据清洗,它是能分析出正确结果的保证;
- 如何挖掘数据不同维度间的联系等;
不足:本次数据分析还有许多需要完善的地方:
- 比如分析不同类型的店铺占比店铺;
- 不同类型的店铺之间的销量对比;
- 由于本次没有爬取评论数据,没有做情感分析;
数据分析之路还很漫长,加油!
如果大家对Python感兴趣,那么这套python学习资料一定对你有用
对于0基础小白入门:
这如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等习教程。带你从零基础系统性的学好Python!

我已经上传至CSDN官方,如果需要可以扫描下方二维码都可以免费获取【保证100%免费】

零基础Python学习资源介绍
-
Python所有方向的学习路线图,清楚各个方向要学什么东西
-
600多节Python课程视频,涵盖必备基础、爬虫和数据分析
-
100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
-
爬虫与反爬虫攻防教程包,含15个大型网站迫解
-
超300本Python电子好书,从入门到高阶应有尽有
-
华为出品独家Python漫画教程,手机也能学习
-
历年互联网企业Python面试真题,复习时非常方便
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
👉Python必备开发工具👈

👉Python学习视频与电子书籍👈
观看零基础学习视频,结合电子书籍最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果,巩固所学知识。

👉面试刷题👈



最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
本期内容就分享到这里,下回再见啊 !喜欢并且对你有用的话,记得点赞支持一下 !!
这篇关于520情人节,不懂送女朋友什么牌子的口红?没关系!Python 数据分析告诉你的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




