本文主要是介绍Seata 2.x 系列【10】回滚日志表 undo_log,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有道无术,术尚可求,有术无道,止于术。
本系列Seata 版本 2.0.0
本系列Spring Boot 版本 3.2.0
本系列Spring Cloud 版本 2023.0.0
源码地址:https://gitee.com/pearl-organization/study-seata-demo
文章目录
- 1. 概述
- 2. 表语句
- 3. 配置项
- 4. 回滚信息
- 4.1 内容
- 4.2 序列化/反序列化
- 4.3 压缩
1. 概述
在AT模式中,需要在参与全局事务的数据库中,添加一个undo_log表,类似于Mysql数据库中的undo log事务回滚日志表,在事务没提交之前,记录分支事务更新前的数据到日志表中,当全局事务需要回滚时,TC发出回滚命令,RM收到后使用undo log进行回退,并删除日志。
2. 表语句
undo_log建表语句如下:
-- seata_account.undo_log definitionCREATE TABLE `undo_log` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',`branch_id` bigint NOT NULL COMMENT '分支事务ID',`xid` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8_general_ci NOT NULL COMMENT '全局事务唯一标识',`context` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8_general_ci NOT NULL COMMENT '上下文',`rollback_info` longblob NOT NULL COMMENT '回滚信息',`log_status` int NOT NULL COMMENT '状态,0正常,1全局已完成(防悬挂)',`log_created` datetime NOT NULL COMMENT '创建时间',`log_modified` datetime NOT NULL COMMENT '修改时间',PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='AT模式回滚日志表';
各字段详细说明如下:
| 字段名 | 说明 |
|---|---|
id | 主键ID |
branch_id | 分支事务ID,比如:99302990136558270 |
xid | 全局事务唯一标识,比如:192.168.58.1:8091:99302990136558268(Seata 服务端地址+全局事务ID) |
context | 回滚信息序列化和压缩格式,serializer=fastjson&compressorType=NONE,表示使用fastjson序列化,没有采用压缩 |
rollback_info | 回滚信息 |
log_status | 日志状态,0正常,1全局已完成 (防悬挂) |
log_created | 创建时间 |
log_modified | 修改时间 |
3. 配置项
Server端关于undo log的配置项:
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
配置说明:
| 配置项 | 描述 | 备注 |
|---|---|---|
server.undo.logSaveDays | 保留天数 | 默认 7 天,清理log_status=1和未正常清理的记录 |
server.undo.logDeletePeriod | 清理线程间隔时间 | 默认 86400000(24小时),单位毫秒 |
Client端关于undo log的配置项:
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
配置说明:
| 配置项 | 描述 | 备注 | 版本说明 |
|---|---|---|---|
client.undo.dataValidation | 二阶段回滚镜像校验 | 默认 true 开启,false 关闭 | |
client.undo.logSerialization | 序列化方式 | 默认 jackson | |
client.undo.logTable | 自定义表名 | 默认 undo_log | |
client.undo.onlyCareUpdateColumns | 只生成被更新列的镜像 | 默认 true | |
client.undo.compress.enable | 压缩开关 | 默认 true | 1.4.1 版本新增 |
client.undo.compress.type | 压缩算法 默认 zip,可选 NONE(不压缩)、GZIP、ZIP、SEVENZ、BZIP2、LZ4、 | DEFLATER、ZSTD | 1.4.1 版本新增 |
client.undo.compress.threshold | 压缩阈值 | 默认值 64k,压缩开关开启且 undo log 大小超过阈值时才进行压缩 | 1.4.1 版本新增 |
4. 回滚信息
4.1 内容
RM执行分支事务后,开始构建回滚日志,其中最重要的就是回滚信息rollback_info字段,记录了数据修改前后镜像。
例如调用库存服务扣减时,undo_log表生成的rollback_info信息如下:

rollback_info信息对应的类为BranchUndoLog,经过序列化后,在数据库以longblob格式存储:
public class BranchUndoLog implements Serializable {private static final long serialVersionUID = -101750721633603671L;// 全局事务标识private String xid;// 分支事务IDprivate long branchId;// undo log 信息private List<SQLUndoLog> sqlUndoLogs;
}
undo log 信息对应的类为SQLUndoLog:
public class SQLUndoLog implements Serializable {private static final long serialVersionUID = -4160065043902060730L;// SQL 类型private SQLType sqlType;// 表名private String tableName;// 操作前数据镜像private TableRecords beforeImage;// 操作后数据镜像private TableRecords afterImage;
}
前置镜像中,会记录该条数据被修改前的主键ID、被修改的字段及值:

后置镜像中,会记录该条数据被修改后的主键ID、被修改的字段及值:
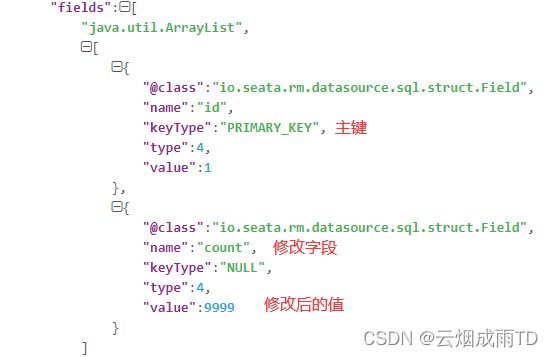
当全局事务需要回滚时,RM会根据事务ID查询到回滚信息(反序列化),根据前后镜像将数据还原到被修改前的状态,然后进行日志删除和事务提交,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
注意: 详细的执行流程,会在后续源码分析篇介绍。
4.2 序列化/反序列化
回滚信息在进行存储、查询时,涉及到序列化、反序列化。Seata 提供了UndoLogParser 接口处理回滚日志的序列化和反序列化:
public interface UndoLogParser {// 序列化类型名称,比如fastjsonString getName();// 获取默认的内容=》{}byte[] getDefaultContent();// 序列化BranchUndoLog 对象 byte[] encode(BranchUndoLog var1);// 反序列化BranchUndoLog 对象 BranchUndoLog decode(byte[] var1);
}
UndoLogParser 接口的实现类就对应了Seata 提供的序列化方式:

简要说明:
FastjsonUndoLogParser:FastjsonJacksonUndoLogParser:JacksonKryoUndoLogParser:KryoProtostuffUndoLogParser:Protostuff
推荐使用默认的jackson即可,其他方式可能还需要额外引入对应的包,并通过以下配置项进行修改:
client.undo.logSerialization=jackson
client.undo.logSerialization=fastjson
client.undo.logSerialization=kryo
client.undo.logSerialization=protostuff
4.3 压缩
在上面我们只修改了库存表的一个存库值,回滚信息的内容已经很多,如果是批量插入、更新、删除等操作,其影响的行数可能会比较多,将会拼接成一个大的字段插入到数据库中,会带来以下问题:
- 超出数据库单次操作的最大写入限制,比如
MySQL的max_allowed_package参数 - 较大的数据量带来的网络
IO和数据库磁盘IO开销比较大
Seata 1.4.1 版在框架层面提供了undo log数据压缩功能,通进一步提高Seata在处理数据量较大的时候的性能,同时也提供了对应的开关和相对合理的默认值,既方便用户进行开箱即用,也方便用户根据实际需求进行一定的调整,使得对应的功能更适合实际使用场景。
实现思路如下图所示:
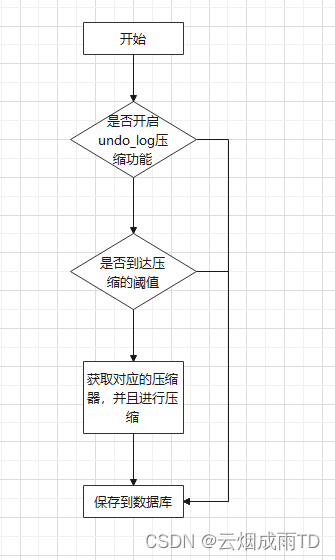
默认配置项如下说示:
# 是否开启undo_log压缩,默认为true
seata.client.undo.compress.enable=true
# 压缩器类型,默认为zip,一般建议都是zip
seata.client.undo.compress.type=zip
# 启动压缩的阈值,默认为64k
seata.client.undo.compress.threshold=64k
这篇关于Seata 2.x 系列【10】回滚日志表 undo_log的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





