本文主要是介绍深度学习总结(2016.9--2016.10),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原本的打算是参加上海Bot大赛,在比赛中学习一下相关知识,就是想入门而已。开学半个月一直没找到状态,只是上上课。后来在师兄的帮助下,开始逐渐着手比赛的事情,虽然最终没有赶上在比赛截至前提交一版测试。但学了不少,不亏!
大致记录一下这一个月做的事情:
keras篇
- win10下先配置keras,看keras文档,用theano后端跑了mnsit数据集,Dogs and Cats 数据集
- 熟悉keras后,搭VGG16网络,加载全连接层之前的参数,自带函数无法做到
- 加载部分参数,花了很久的时间才搞定,最终,强行一层一层的加载,全链接层用[-0.1,0.1]随机数,过程中学习了.h5文件的写入和读取
- 重载参数参数后用数据集训练模型,但acc数值一直和瞎猜的一样,三类的话,acc就是0.33,同时loss在一个epoch后,数值上升,并且保持不变!!!一直都不变!!!(过了一个月,发现是lr太高了,把lr调低模型就开始收敛了)找了很久没有找到原因,一方面是知识匮乏,一方面keras封装的太高层了,完全看不到实现细节,最终放弃keras,转向了caffe。
caffe篇
- win10下一晚上配好了caffe的cpu版本和gpu版本,感觉比keras好配置多了。查了资料学习如何使用,还是mnist入手,结果全是命令行一脸懵逼,好在搞清楚后确实方便很多,一行代码都没写,就是转数据成lmdb,设置各种路径,速度caffe确实比theano快,只不过命令行显示信息不如keras好看
- 会用caffe后,改VGG16模型,重载参数,最后一层全连接层(fc3层)随机初始化参数,fc1和fc2层重载参数并小lr更新,fc3层大lr更新,一切顺利,训练了6个epoch后top1命中0.8,top5命中0.95
- 想办法提高acc,之后就做了很多实验,如下:
- 师兄说试试增加数据量,全连接层参数全部随机初始化,只训练最后三层。
- 增加数据量方法:先保持长宽比调整原图片最短边为256,用边长224的正方形对图片进行crop,四个角+正中间,再左右反转,总共10张(原本还有旋转等,但一算扩大了134倍,有4T数据,放不下,就先扩大10倍)
- train_set有12W张图片,大小12G,扩充数据花了4个小时,扩充后大小25G,再转成lmdb格式,用时10小时,大小260G。
- 最后3层全连接层随机初始化参数,用260G数据训练30个epoch后准确率acc : 0.755080465171,比之前的还差…………
就开始找原因,先后做了很多实验(以下实验结果所用模型为120W数据训练最后三层fc层,30epoch所得的模型):
实验1:从train集合中抽出100张进行预测,统计acc,score=0.96
实验2:测试时,将测试图片直接压缩到224*224进行测试,统计acc=0.797251262775(这种方法acc比实验3的acc高)
实验3:测试时,将每张测试图片保持长宽比调整到最短边为256,对四个角+中心用224*224大小的正方形进行crop,用crop出来的5个图片分别进行预测,将5个小图片预测出来的置信度对应相加再除以5(保证总的置信度为1),取置信度最高的类别为预测出来的类别,统计acc=0.755080465171
实验4:结合实验2和实验3,将实验2和3预测出的置信度对应相加,平均,以计算出来的置信度为最终置信度,取最高为预测类别,统计acc=0.814049101374(这种方法准确率最高)
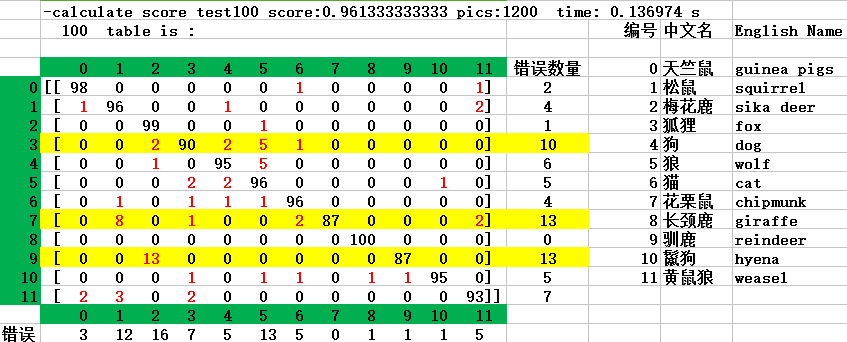
实验5:做一个12*12的表格,行数表示真实的图片类别,列表示预测的类别,统计每种情况的图片数量(贴一个120W张图片30个epoch模型的结果)
predict_pic_labels_32_use_mix_30_epoch_probability_12 -calculate score test score:0.843392458593 pics:8513 time: 6.904585 s top 1 count_num: 6930 sum_num: 8513 acc : 0.814049101374 test table is : [ 989 3 0 0 15 1 16 4 3 4 1 10] [ 23 476 7 4 12 3 32 63 7 13 3 38] [ 3 5 605 3 3 21 12 1 63 96 7 10] [ 13 13 13 632 17 66 23 7 3 12 15 22] [ 15 1 2 12 886 34 30 6 18 22 7 11] [ 13 5 10 17 20 341 22 3 7 29 17 11] [ 10 6 2 6 21 3 1096 8 5 0 2 7] [ 15 55 3 3 4 9 19 284 7 10 2 13] [ 16 0 20 0 11 3 25 3 846 18 3 7] [ 16 0 17 0 9 6 8 3 5 91 3 10] [ 0 3 1 7 7 29 11 1 9 35 449 5] [ 6 14 7 11 3 8 10 4 4 8 4 236]实验6:将test集合中错误分类的图片按类别输出,观察被分错的图片都有神马特点(发现大部分是动画图片)
test_wrong_pic_6(cat) real_animal toy_model _animal cartoon_animal sum_num=388 136 16 236 percent 36% 4% 60% 实验7:随机从train集合和test集合中抽出500张图片,分别人眼统计真实动物图片数量、玩具模型动物图片数量、动画动物图片数量
train集合12W张图片,结果:train_set_12W real_animal toy_model _animal cartoon_animal train_set_500_1 498 0 2 train_set_500_2 496 0 4 train_set_500_3 493 1 6 percent 99.13% 0.07% 0.8% test集合8513张图片,结果:
test_set_8513 real_animal toy_model _animal cartoon_animal test_set_500_1 419 10 71 test_set_500_2 496 12 68 percent 84% 2% 14% 实验8:从test集合中分别拿100张真实动物图片、玩具模型动物图和动画动物图片,进行测试统计acc
test_set_100 real_animal toy_model _animal cartoon_animal acc 84% 52% 35% - 结论:综合实验6、实验7和实验8,acc不高的主要原因就是训练集中卡通图片几乎没有,测试集中出现了许多卡通图片。次要原因是细粒度分类效果不好,实验1的结果就可以看出。
接下来的工作就是两个方向,一个细粒度分类,一个domain transfer,师兄讲先看看domain transfer方面的论文吧
这篇关于深度学习总结(2016.9--2016.10)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





