本文主要是介绍Docker 容器化技术:构建高效、可移植的开发环境和部署流程|Docker 数据管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在 Docker 中,数据主要分为两类:非持久化数据和持久化数据。
非持久化数据是指不需要长期保存的临时数据,每个 Docker 容器都有自己的非持久化数据,这次存储自动创建,与容器的生命周期相同,因此删除容器会同时删除非持久化数据。
如果需要保留容器的数据进行持久化,就需要使用数据卷,通过将宿主机上的目录与容器的挂载点(数据卷)关联,容器的挂载点内容就是宿主机的目录内容。这样,对宿主机目录的修改就会立即反映在容器中,反之亦然。数据卷与容器解耦,可以独立创建和管理,且不受容器生命周期影响,因此,删除关联卷的容器不会删除卷本身。
1、非持久化数据
每个容器都有自己的本地存储(非持久化数据),一般在容器创建时被自动分配,通常位于 /var/lib/docker/<storage-driver>/ 目录下。这些数据与容器的生命周期一致,创建容器时自动创建,删除容器时自动删除。
Docker 提供了多种存储驱动(storage-driver),常见的有:
AUFS
是一种多层联合文件系统,是文件级别的存储驱动。AUFS 可以透明覆盖一个或多个现有文件系统的层状文件系统,把多层合并成文件系统的单层表示。简单说就是支持将不同目录挂载到同一个虚拟文件系统下的文件系统,可以一层一层地叠加修改文件,无论下面有多少层,这些层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS 创建该文件的一个副本,使用 CoW 将文件从只读层复制到可写层进行修改,结果也保存在可写层,在 Docker 中,只读层是镜像,可写层是容器。
OverlayFS
只有两层的 Union FS,一个 upper 文件系统和一个 lower 文件系统,分别代表镜像层和容器层。当需要修改一个文件时,使用 CoW 将文件从只读的 lower 复制到可写的 upper 进行修改,结果也保存在 upper。
Device mapper
提供了逻辑设备到物理设备的映射框架机制,在这种机制下,用户可以方便地根据自己的需求制定实现存储资源的管理策略。AUFS 和 OverlayFS 都是文件级存储,而 Device mapper 支持块级存储,所有的操作都直接对块进行操作的,而不是对文件。
Btrfs
被称为是下一代写时拷贝文件系统,并入 Linux 内核,是文件级存储,但可以像 Device mapper 一样直接操作底层设备。Btrfs 把文件系统的一部分配置为一个完整的子文件系统,成为 subvolume。采用 subvolume,一个大的文件系统可以被划分为多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配。
ZFS
是一个革命性的、全新的文件系统,从根本上改变了文件系统的管理方式,完全抛弃了卷管理,不再创建虚拟的卷,而是把所有设备集中到一个存储池中进行管理,管理方式基于存储池,用存储池管理物理存储空间。
默认情况下,容器的所有存储都是用本地存储,所以 /var/lib/docker/<storage-driver>/ 目录下存储了本地所有容器的数据。
如果容器不产生持久化数据,那本地存储即可满足容器运行的需求,但如果希望容器被销毁后数据依旧存在,那就需要对这部分依旧存在的数据进行持久化。
2、持久化数据
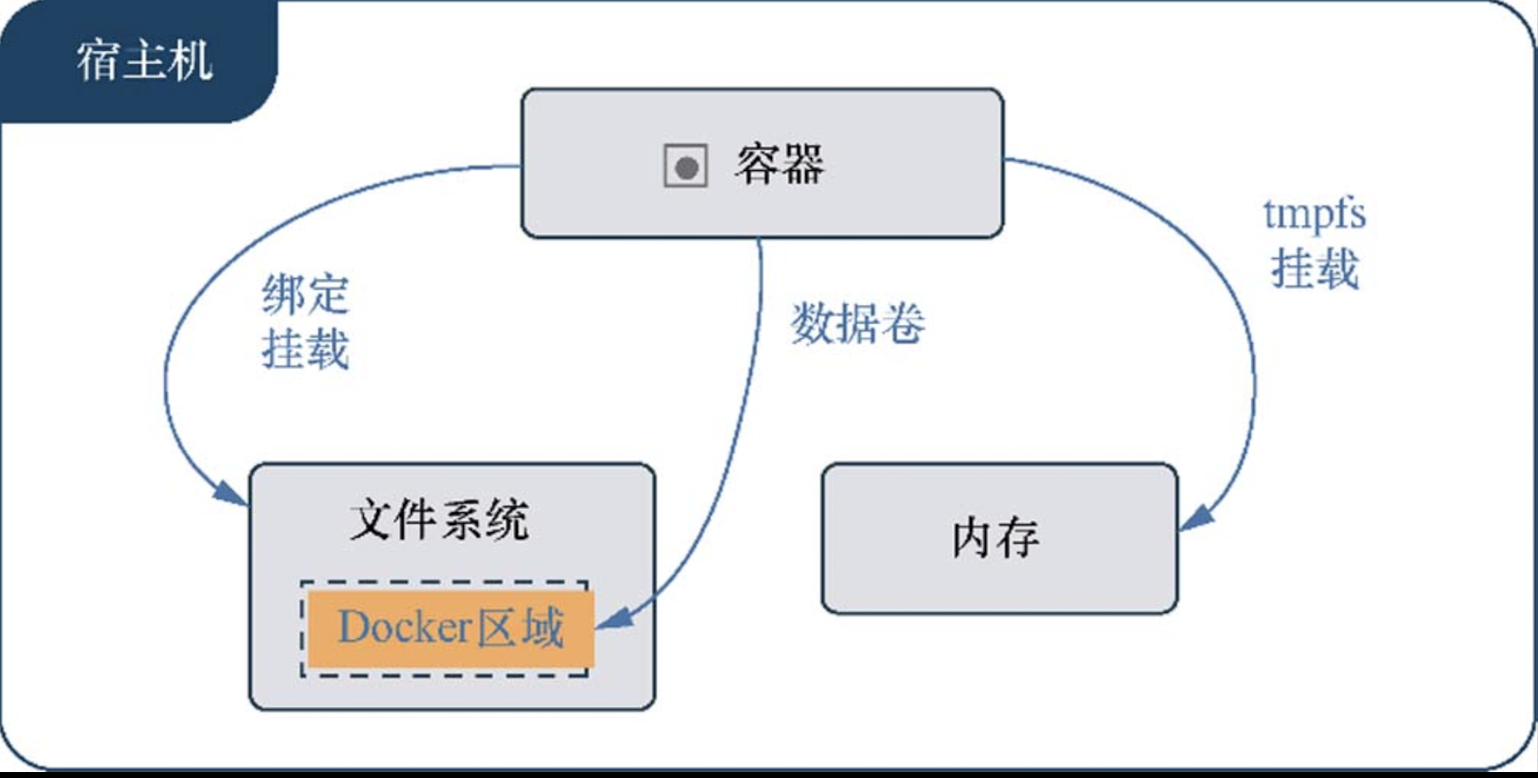
默认情况下,容器的数据保存在可读写层,但容器删除时数据将丢失,为了实现数据的持久性,可以选择三种方式:
- 数据卷(volume):通过 -v 或者 --volume 参数将宿主机目录与容器绑定,推荐使用 --mount,数据卷的存储空间来自宿主机文件系统中的某个目录,比如 /var/lib/docker/volumes/,这是 Docker 官方推荐的持久化方案
- 绑定挂载(bind mount):将宿主机文件、目录挂载到容器上,使用 mount 参数与宿主机目录做绑定,不改变容器内原有的文件,可以被宿主机和容器读写
- tmpfs 挂载:临时性的挂载,文件存在于宿主机内容中,不会持久化
无论选择哪种方式,从容器内部看都是没有区别的,数据都在宿主机的内存中,只不过具体位置有一定的区别。
3、集群节点间共享存储
不论是数据卷还是数据卷容器,都只能在同一台宿主机上的容器中访问。有时,我们需要使不同宿主机节点上的容器能够共享数据,以实现应用的容错处理。在开发应用程序时,有两种方法可以实现此目的:
- 一种方法是通过为应用程序添加逻辑,将文件存储在阿里云 OSS 或 Amazon S3等 云对象存储系统上
- 另一种方法是使用支持将文件写入 NFS 或 Amazon S3 等外部存储系统的驱动程序来创建共享卷
Docker能够集成外部存储系统,使集群中多个节点之间共享外部存储数据变得可行。例如,网络文件系统(NFS)或 Amazon S3 可以在多个 Docker 宿主机之间共享应用程序,因此,无论容器或服务副本在哪个节点上运行,都可以共享该存储。
卷驱动程序允许您从应用程序逻辑中抽象出底层存储系统。例如,如果您的服务使用具有 NFS 驱动程序(或其他分布式数据卷驱动)的共享卷,则可以通过更新服务来使用其他驱动程序(如在云中存储数据),而无需更改应用程序逻辑。
这篇关于Docker 容器化技术:构建高效、可移植的开发环境和部署流程|Docker 数据管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




