本文主要是介绍基于飞桨搭建的多模态学习工具包PaddleMM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

随着计算机视觉、自然语言处理、语音识别等技术的快速发展,现有的人工智能技术在处理单模态数据方面取得了显著的成效。然而,在现实生活中,数据呈现的形式多种多样,例如我们阅读的文字、听到的声音、观看的视频等,这些多源异构信息称为多模态数据,而机器学习领域将挖掘和分析多模态数据的一类算法归为多模态学习方法。为使人工智能更好地理解真实环境,多模态学习近年来引起了研究者的广泛关注,在相关应用领域取得了长足的进步。
从任务目标进行划分,多模态学习可以分为模态联合学习、跨模态学习和多任务预训练框架:
模态联合学习:侧重于综合利用不同模态信息学习一致性目标,如多模态分类和回归;
跨模态学习:侧重于研究模态之间的关联信息,如跨模态检索、图文生成;
多任务预训练框架:基于Transformer进行无监督预训练,可以在多种下游任务上微调。
项目介绍

小编为你送上项目地址
点击阅读原文即可GET
https://github.com/njustkmg/PaddleMM
多模态学习工具包PaddleMM基于百度飞桨,提供模态联合学习和跨模态学习算法模型库,为处理图片文本等多模态数据提供高效的解决方案,助力多模态学习应用落地:
任务场景:工具包提供多模态融合、跨模态检索、图文生成等多种多模态学习任务算法模型库;
应用案例:基于工具包算法已有相关落地应用,如球鞋真伪鉴定、图像字幕生成、舆情监控等。
多模态模型库
当前,PaddleMM针对图片和文本模态提供了多模态算法模型库(更新中),包括多模态分类、跨模态检索、图文生成和预训练框架四个模块。
多模态分类
多模态分类算法主要分为模型无关的算法(如早融合/晚融合)和基于模型的算法(如CMML、LMF、TMC),具体如下:
早融合/晚融合:分别从特征层面和预测层面融合不同模态的信息,从而进行分类任务;
CMML[1]:针对模态不一致场景自适应加权融合实现稳健的多模态分类;
LMF[2]:基于模态特定因子的低秩多模态融合分类;
TMC[3]:可信预测的多模态融合策略。
跨模态检索
图片和文本的检索任务思路是为两种模态分别提取特征并映射到统一空间中,在共享的语义空间中学习图文的匹配打分,在模型的训练过程中,对匹配的正样本和构造的不匹配负样本分别打分,训练模型学习正负图文样本对之间的差异。工具包实现了基于不同打分度量的典型跨模态检索算法,具体如下:
VSE++[4]:为图像和文本提取全局特征,基于全局特征计算匹配打分;
SCAN[5]:从图像区域和文本单词中学习图文匹配打分;
IMRAM[6]:引入迭代累积相似度改进图文对齐信息;
SGRAF[7]:加入图(Graph)关联相似度来衡量图文匹配。
图文生成
图文生成任务是为了给图像生成描述信息,一般基于编码器-解码器架构,使用编码器从图像中提取特征,并基于图像信息依次生成单词,实现文本的解码。工具包实现了两种不同的算法:
ShowAttendTell[8]:使用VGG编码图像信息得到feature map,利用LSTM进行解码,在解码过程中引入注意力机制选取特定的图像上下文信息指导当前阶段的单词生成;
AoANet[9]:使用类似Transformer结构搭建编码器和解码器,并拓展原始的自注意力提出attention on attention(AOA)模块。
预训练框架
多模态预训练框架基于Transformer的模型,首先在大规模的无标记多模态数据上使用自监督任务进行预训练,接着在下游任务上根据特定标签实现有监督地微调。工具包目前提供了ViLBert[10]算法,该方法为图像和文本分别构建Transformer,在自注意力计算过程中进行模态信息的交互。
工具包说明
PaddleMM分为数据处理、模型库、训练器三个模块。其中,数据模块包括对图像和文本的不同处理形式,如图像的全局特征、局部特征处理,文本的统计信息、分词、BERT处理;模型库涵盖多模态分类、跨模态检索、图文生成等不同任务;训练器针对不同任务给出不同的训练流程,在模型训练中提供不同的训练策略,并收录了不同任务的多种测试指标。
如下图所示,在PaddleMM调用中,需要定义模型配置文件、数据目录和实验记录地址三个变量,我们将所有模型的超参数存放在configs文件夹中,模型的配置文件中会包括两类超参数,第一类是工具包相关超参数,如任务类型,需要文本和图像的处理格式等,在实验中工具包会根据这些信息选择相应的数据读取方式、训练器和测试指标,配置文件中的另一类参数是具体的模型超参数,即模型在使用中推荐的最优超参数。
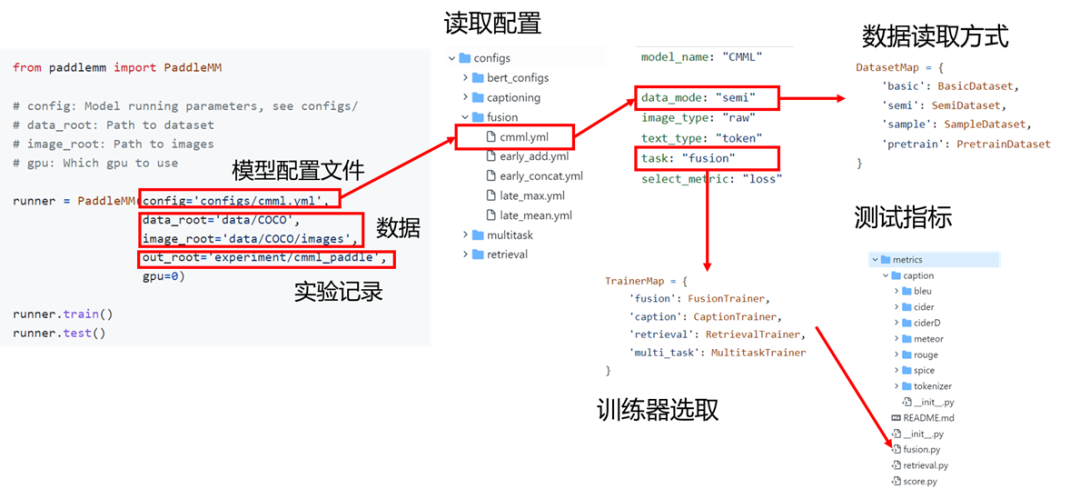
工具包在实际使用中一般包括以下步骤:设置超参数->工具包初始化->模型训练->指标测试,下面是一个示例:
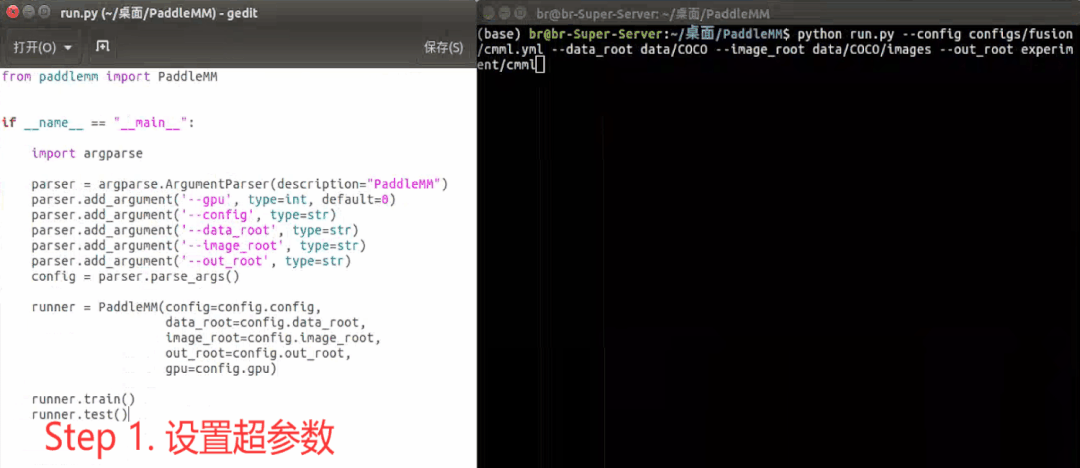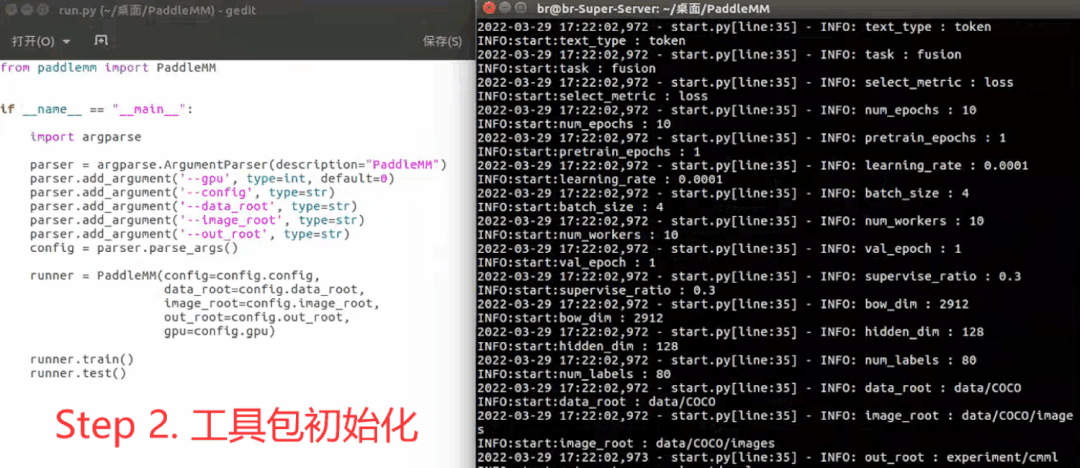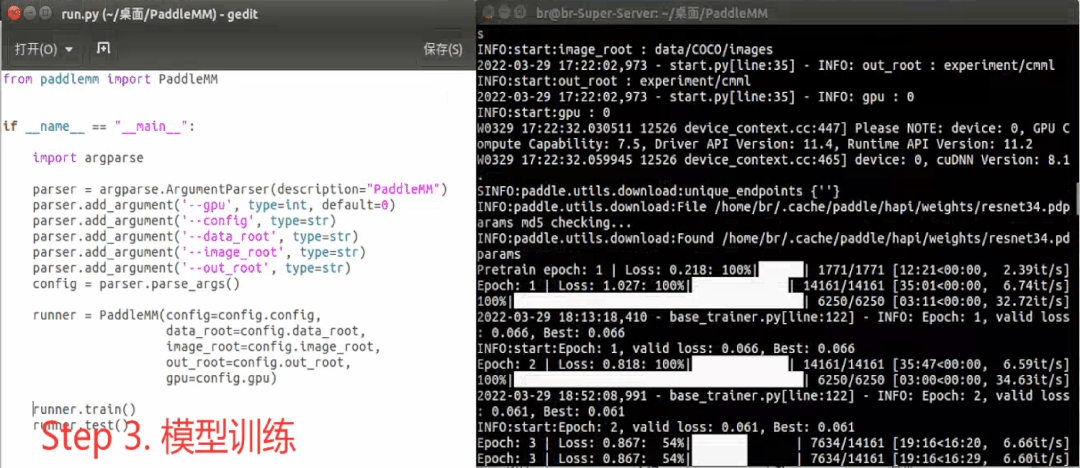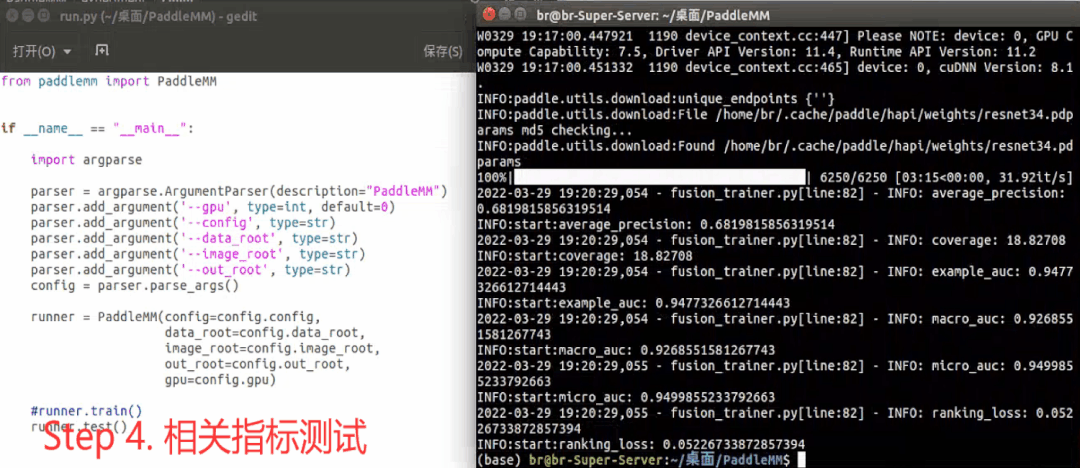
模型开发
我们以CMML[1]算法为例,看看如何在飞桨平台上开发多模态学习模型。CMML,主要是面向分类任务,针对模态信息不一致场景,对来自不同模态的预测自适应加权融合,下图所示整体结构:
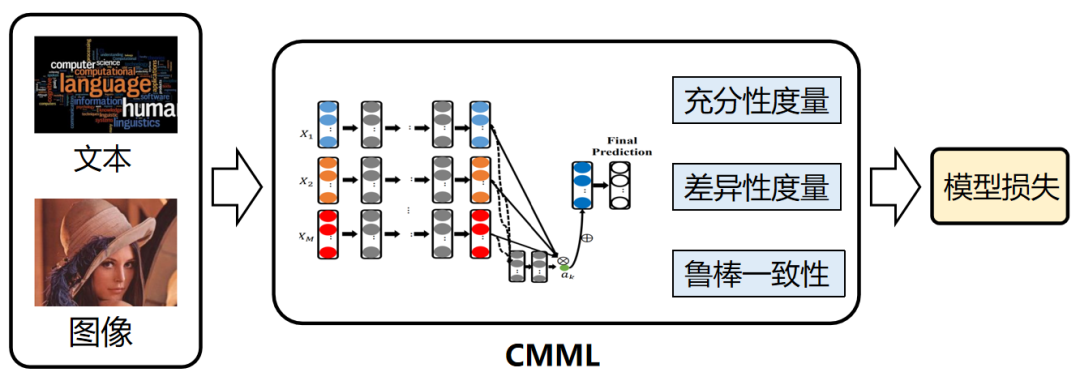
具体来说,CMML输入的有标记和无标记多模态数据,通过文本预测网络和图像预测网络分别计算单模态预测,接着计算以下优化目标:
充分性度量:通过模态注意力学习网络对有标记数据的单模态预测计算权重并自适应加权融合,与真实标记计算交叉熵损失函数;
差异性度量:计算有标记数据的不同模态预测差异,该部分旨在于最大化不同模态预测差异凸显模态强弱,提高模型泛化能力;
鲁棒一致性:对于无标记数据的不同模态预测计算Huber损失,该部分旨在于排除不一致样本的干扰,以实现对模型的鲁棒性约束。
最终,CMML使用三个优化目标得到模型损失,使用梯度下降法优化模型。
AI Studio项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/2423256
数据加载
CMML对文本数据提取词袋特征,基于全局图像数据进行训练,同时CMML是一个半监督的学习模型。因此,我们在数据部分需要准备好有监督和无监督的文本的词袋特征、图像的原始矩阵特征,以及有监督数据的标签信息。
模型开发
CMML主体模型由三个部分组成:
文本预测网络
self.txt_hidden = nn.Sequential(nn.Linear(input_dim, hidden_dim*2),nn.ReLU(),nn.Linear(hidden_dim*2, hidden_dim),nn.ReLU())
self.txt_predict = nn.Linear(hidden_dim, num_labels)图像预测网络
self.resnet = models.resnet34(pretrained=True)
self.resnet = nn.Sequential(*list(self.resnet.children())[:-1])
self.img_hidden = nn.Linear(512, hidden_dim)
self.img_predict = nn.Linear(hidden_dim, num_labels)模态注意力学习网络
self.attn_mlp = nn.Linear(hidden_dim, 1)
self.attn_mlp = nn.Sequential(nn.Linear(hidden_dim, int(hidden_dim/2)),nn.ReLU(),nn.Linear(int(hidden_dim/2), 1)
)在训练中,CMML需要计算以下三种优化目标:
充分性度量
supervised_txt_hidden = self.txt_hidden(supervised_txt)
supervised_txt_predict = self.txt_predict(supervised_txt_hidden)
supervised_txt_predict = self.sigmoid(supervised_txt_predict)supervised_img_hidden = self.resnet(supervised_img)
supervised_img_hidden = paddle.reshape(supervised_img_hidden, shape=[supervised_img_hidden.shape[0], 512])
supervised_img_hidden = self.img_hidden(supervised_img_hidden)
supervised_img_predict = self.img_predict(supervised_img_hidden)
supervised_img_predict = self.sigmoid(supervised_img_predict)attn_txt = self.attn_mlp(supervised_txt_hidden)
attn_img = self.attn_mlp(supervised_img_hidden)
attn_modality = paddle.concat([attn_txt, attn_img], axis=1)
attn_modality = self.softmax(attn_modality)
attn_img = paddle.zeros(shape=[1, len(label)])
attn_img[0] = attn_modality[:, 0]
attn_img = paddle.t(attn_img)
attn_txt = paddle.zeros(shape=[1, len(label)])
attn_txt[0] = attn_modality[:, 1]
attn_txt = paddle.t(attn_txt)supervised_hidden = attn_txt * supervised_txt_hidden + attn_img * supervised_img_hidden
supervised_predict = self.modality_predict(supervised_hidden)
supervised_predict = self.sigmoid(supervised_predict)mm_loss = self.criterion(supervised_predict, label)差异性度量
similar = paddle.bmm(supervised_img_predict.unsqueeze(1), supervised_txt_predict.unsqueeze(2))
similar = paddle.reshape(similar, shape=[supervised_img_predict.shape[0]])
norm_matrix_img = paddle.norm(supervised_img_predict, p=2, axis=1)
norm_matrix_text = paddle.norm(supervised_txt_predict, p=2, axis=1)
div = paddle.mean(similar / (norm_matrix_img * norm_matrix_text))鲁棒一致性
unsimilar = paddle.bmm(unsupervised_img_predict.unsqueeze(1), unsupervised_txt_predict.unsqueeze(2))
unsimilar = paddle.reshape(unsimilar, shape=[unsupervised_img_predict.shape[0]])unnorm_matrix_img = paddle.norm(unsupervised_img_predict, p=2, axis=1)
unnorm_matrix_text = paddle.norm(unsupervised_txt_predict, p=2, axis=1)
dis = 2 - unsimilar / (unnorm_matrix_img * unnorm_matrix_text)mask_1 = paddle.abs(dis) < self.cita
tensor1 = paddle.masked_select(dis, mask_1)
mask_2 = paddle.abs(dis) >= self.cita
tensor2 = paddle.masked_select(dis, mask_2)
tensor1loss = paddle.sum(tensor1 * tensor1 / 2)
tensor2loss = paddle.sum(self.cita * (paddle.abs(tensor2) - 1 / 2 * self.cita))unsupervised_loss = (tensor1loss + tensor2loss) / unsupervised_img.shape[0]模型训练
在CMML训练中,模型读取数据加载器中的图像和文本特征,并将其输入到模型中,通过计算三种不同的优化目标,并将其联合计算损失优化模型。
总结
PaddleMM提供了多模态学习的模型和应用工具,我们在这里介绍了工具包的算法概览和使用说明,最后演示了多模态分类算法CMML基于飞桨平台的模型开发流程,希望能对多模态学习在飞桨平台上的落地应用做一点点工作,欢迎交流和star!
相关链接
多模态学习资料:
https://github.com/njustkmg/Multi-Modal-Learning
CMML复现AI Studio项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/2423256
感谢百度人才智库TIC部门和百度飞桨平台对工具包开发的支持:
NJUST-KMG小组:
http://www.njustkmg.cn/
百度人才智库TIC部门:
https://ai.baidu.com/solution/recruitment
百度飞桨平台:
https://www.paddlepaddle.org.cn/
参考文献
[1] Yang Y, Wang K T, Zhan D C, et al. Comprehensive semi-supervised multi-modal learning. IJCAI. 2019.
[2] Faghri F, Fleet D J, Kiros J R, et al. Vse++: Improving visual-semantic embeddings with hard negatives. BMVC. 2018.
[3] Liu Z, Shen Y, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors. ACL. 2018.
[4] Han Z, Zhang C, Fu H, et al. Trusted multi-view classification. ICLR. 2021.
[5] Lee K H, Chen X, Hua G, et al. Stacked cross attention for image-text matching. ECCV. 2018.
[6] Chen H, Ding G, et al. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. CVPR. 2020.
[7] Diao H, Zhang Y, Ma L, et al. Similarity reasoning and filtration for image-text matching. AAAI. 2021.
[8] Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention. PMLR. 2015.
[9] Huang L, Wang W, Chen J, et al. Attention on attention for image captioning. CVPR. 2019.
[10] Lu J, Batra D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. NeurIPS. 2019.

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
这篇关于基于飞桨搭建的多模态学习工具包PaddleMM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









