本文主要是介绍【python 的各种模块】(8) 在python使用matplotlib和wordcloud库来画wordcloud词云图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
目标:用python画出,网上流行的wordcloud词云图
1 准备工作
1.1环境准备
1.1.1安装步骤
1.2 资源准备
1.2.1 文本文件内容如下
1.2.2 图片资源
2 代码测试
2.1 第一版代码和效果
2.1.1 代码和效果
2.1.2 一般plt里解决中文乱码问题
2.1.3 wordcloud的中文显示方框解决办法
2.2 修改后的代码
2.3 上述代码解析
2.3.1 导入模块
2.3.2 读取txt文件的内容,存储在变量wordlist里
2.3.3 用mask属性进行图片解码,然后利用解码的图形形式
2.3.4 输出显示
2.3.5 核心函数 WordCloud()
3 wordcloud() 语法详细
3.1 多级对象辨析
3.2 函数基础语法
3.3 函数基础语法相关参数解析
3.3.1 WordCloud的参数:
3.3.2 测试代码
4 词云图片的显示和输出
4.1 几种显示方式
4.1.1 用 plt.imshow(wordcloud)显示词云
4.1.2 用wordcloud.to_image().show() 来显示词云,并不保存图片!
4.2 保存为图片
4.2.1 其他输出函数和依赖的包/模块
4.2.2 使用 wordcloud.to_file(path) 保存词云
4.2.3 使用wordcloud.to_image().save(path)
5 设置图片效果
5.1 mask 蒙版相关
5.1.1 使用透明背景 蒙板
5.1.2 使用蒙版中的颜色
5.1.3 自定义颜色
6 jieba 和分词
目标:用python画出,网上流行的wordcloud词云图

1 准备工作
1.1环境准备
- 确保已经安装了 wordcloud 模块
- 如果你运行代码时,加上了这句from wordcloud import WordCloud,STOPWORDS,
- 报错: 找不到wordcloud 模块 ,那么你就需要先安装wordcloud 模块
1.1.1安装步骤
以我的环境 anaconda为例子
- step1: 运行anaconda prompt 命令行的IDE
- step2: 可以先输入 conda list 看看都安装了什么,也可以不看,^ ^
- step3: 输入 pip show wordcloud ,如果显示找不到就是没有安装
- step4: 输入 pip install wordcloud 安装完成即可
- step5: 输入 pip show wordcloud 检查下是否安装成功,看看版本信息,也可以部看,^ ^


1.2 资源准备

1.2.1 文本文件内容如下
随便找点词语,有重复的,不重复的即可。
开心、喜悦、狂喜、尽情、快乐、愉悦、畅快、欣喜、幸福、得意、痛快、满足、欢乐、快活
快乐,舒畅,舒心,欢畅,夷悦,欣忭,怡悦,得意,愿意,欢跃,夷愉,欢快,喜悦,快活,愉快,欢乐,忻悦,欣喜,欢喜,痛快,雀跃,乐意
眉开眼笑 眉飞色舞 喜上眉梢 喜在眉宇 喜眉笑目 捧腹大笑 手舞足蹈 前仰后合
开怀大笑 欢蹦乱跳 笑容可掬 喜笑顡开 笑逐颜开 相视而笑 谈笑风生 兴高采烈
喜从天降 高高兴兴 开开心心 嘻嘻哈哈 满怀喜悦 满心欢喜 喜出望外 大喜过望
甜美、微笑、兴奋,陶醉,高兴,自豪、欣慰,满意、幸运、嬉笑,满意、幸运、嬉笑,狂笑,荣幸,痛快、满足、欢乐、快活,畅快、欣喜、幸福、得意,开心、喜悦、狂喜、尽情、快乐、愉悦、畅快、欣喜、幸福、逸乐、尽情、舒畅、愉快、喜哈、愉快
1.2.2 图片资源
- 图片要注意,wordcloud是把词语生成在图片中,之前有图像的地方,而不是空白的地方
- 因此不要找那种 空白区域特别大的,否则最后效果可能会让你惊讶

2 代码测试
2.1 第一版代码和效果
2.1.1 代码和效果
- 这效果不对啊,这么多方框是什么情况?
from wordcloud import WordCloud,STOPWORDS
import PIL.Image as image#默认矩形,有想要的形状可以加入图片#plt.rcParams['font.family']='LiSu'# 正常显示中文
#plt.rcParams['axes.unicode_minus']=False# 正常显示负号def get_wordList():f = open(r'C:\Users\Administrator\Desktop\t2.txt')wordList = f.read()return wordList
def get_wordClound(mylist):pic_path = r'C:\Users\Administrator\Desktop\tp2.jpg'#注意路径img_mask = np.array(image.open(pic_path))#图片解码 wordcloud = WordCloud(background_color = "white",mask = img_mask).generate(mylist)#font_path ="C:/Windows/Fonts/msyh.ttc",#mask = img_mask掩码 generate(mylist)获取数据plt.imshow(wordcloud)plt.axis("off")#去除坐标轴
wordList = get_wordList()
get_wordClound(wordList)plt.title("wordcloud词云实验")
plt.show()

2.1.2 一般plt里解决中文乱码问题
matplotlib 对中文的支持有问题
一般画图时,遇到图片相关中文显示问题,一般在代码前面加这2句
plt.rcParams['font.family']='LiSu'# 正常显示中文
plt.rcParams['axes.unicode_minus']=False# 正常显示负号
2.1.3 wordcloud的中文显示方框解决办法
- wordcloud = WordCloud(background_color = "white",mask = img_mask).generate(mylist)
- 函数WordCloud()加上 font_path ="C:/Windows/Fonts/msyh.ttc",
- wordcloud = WordCloud(font_path ="C:/Windows/Fonts/msyh.ttc",background_color = "white",mask = img_mask).generate(mylist)
2.2 修改后的代码
from wordcloud import WordCloud,STOPWORDS
import PIL.Image as image#默认矩形,有想要的形状可以加入图片plt.rcParams['font.family']='LiSu'# 正常显示中文
plt.rcParams['axes.unicode_minus']=False# 正常显示负号def get_wordList():f = open(r'C:\Users\Administrator\Desktop\t2.txt')wordList = f.read()return wordList
def get_wordClound(mylist):pic_path = r'C:\Users\Administrator\Desktop\tp2.jpg'#注意路径img_mask = np.array(image.open(pic_path))#图片解码 wordcloud = WordCloud(font_path ="C:/Windows/Fonts/msyh.ttc",background_color = "white",mask = img_mask).generate(mylist)#mask = img_mask掩码 generate(mylist)获取数据plt.imshow(wordcloud)plt.axis("off")#去除坐标轴
wordList = get_wordList()
get_wordClound(wordList)plt.title("wordcloud词云实验")
plt.show()
2.3 上述代码解析
2.3.1 导入模块
- from wordcloud import WordCloud
- 如果需要作图一般来说,需要导入import matplotlib ,但是在jupyternotebook不import matplotlib,居然也可以引用后面使用 plt.show() 也没有出错
居然不需要 import matplotlib,怀疑又是jupyternotebook这个IDE的特殊性导致的?
jupyternotebook我现在知道的例外的特点:
- 不用写 plt.show() 也能显示matplotlib.pyplot 下的figure内的图形
- 不支持弱引用
- (猜测的) import matplotlib 也可以用plt的内容作图?
2.3.2 读取txt文件的内容,存储在变量wordlist里
def get_wordList():
f = open(r'C:\Users\Administrator\Desktop\t2.txt')
wordList = f.read()
return wordList
2.3.3 用mask属性进行图片解码,然后利用解码的图形形式
- 先进行图片解码,也就是通过wordcloud(mask="") 属性把一张图片转义为一个矩阵。(应该是一个二进制的数值矩阵)
- 然后再利用这个图片解码的矩阵作为 范围就显示图片
def get_wordClound(mylist):
pic_path = r'C:\Users\Administrator\Desktop\tp2.jpg'
img_mask = np.array(image.open(pic_path))
wordcloud = WordCloud(font_path ="C:/Windows/Fonts/msyh.ttc",background_color = "white",mask = img_mask).generate(mylist)
#mask = img_mask掩码 generate(mylist)获取数据
plt.imshow(wordcloud)
plt.axis("off")#去除坐标轴
2.3.4 输出显示
- 用 plt.imshow() 显示图片
- 隐藏坐标轴
plt.imshow(wordcloud)
plt.axis("off")#去除坐标轴
2.3.5 核心函数 WordCloud()
后面详细说明
wordcloud = WordCloud(font_path ="C:/Windows/Fonts/msyh.ttc",background_color ="white",mask = img_mask).generate(mylist)
3 wordcloud() 语法详细
- wordcloud = WordCloud().generate()
3.1 多级对象和方法辨析
- wordcloud.WordCloud().generate(text)
- #导入模块 import wordcloud
- #导入模块的下级 form wordcloud import WordCloud
- #生成WordCloud() 对象 wordcloud.WordCloud() #生成一个wordcloud对象
- #错误写法,wordcloud.WordCloud 并不是下级对象/属性
3.2 函数基础语法
- wordcloud.WordCloud()
help(wordcloud.WordCloud()) 内容太多太长了,这里就不贴了
- 在python里使用 help() 函数获得官方帮助
- help(wordcloud.WordCloud())
import wordcloudhelp(wordcloud.WordCloud())
3.3 函数基础语法相关参数解析
3.3.1 WordCloud的参数,第1部分:
- font_path:可用于指定字体路径
- width:词云的宽度,默认为 400;
- height:词云的⾼度,默认为 200;
- mask:蒙版,可⽤于定制词云的形状;
- min_font_size:最⼩字号,默认为 4;
- max_font_size:最⼤字号,默认为词云的⾼度;
- max_words:词的最⼤数量,默认为 200;
- stopwords:将被忽略的停⽤词,若不指定则使⽤默认停⽤词词库;
- background_color:背景颜⾊,默认为 black;
- mode:默认为RGB模式,如果为RGBA模式且background_color设 为 None,则背景将透明。
- generate(str) 接受一个字符串
- font_path ="C:/Windows/Fonts/msyh.ttc",显示字体,中文一定要设置字体
- repeat: 可以让text里的词语重复使用,适合文件里文本较少的情况
- max_words: 显示的最多的词语数,
- colormap #="winter", "summer" #配色方案
3.3.2 重点说明:font_path ="C:/Windows/Fonts/msyh.ttc",显示字体,中文一定要设置字体
- windows系统的电脑的,字体的存放位置。
- 需要指定一个中文字体即可
3.3.3 WordCloud的参数测试部分
- 比如=改变colormap="winter" 或者"spring" 等可以修改颜色
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hello,hello,hi"
wordcloud=wordcloud.WordCloud(font_path ="C:/Windows/Fonts/msyh.ttc",\width=int(100/0.618),\height=100,\mode='RGBA',\background_color=None,\min_font_size=1,\max_font_size=20,\repeat=True,max_words=20,colormap="spring",).generate(text)plt.imshow(wordcloud)
plt.axis("off")
plt.show()

4 词云图片的显示和输出
4.1 几种显示方式
4.1.1 用 plt.imshow(wordcloud)显示词云
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hi"
wordcloud=wordcloud.WordCloud().generate(text)plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()

# 显示
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")plt.show()
4.1.2 用wordcloud.to_image().show() 来显示词云,并不保存图片!
- 可以用下面2种写法,但是有细微的差别
- wordcloud.to_image().show() # 会直接在 jupyter里直接显示
- wordcloud.to_image() # 会弹出一个图片,你可以手动保存,但不会主动保存
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hi"
wordcloud=wordcloud.WordCloud().generate(text)#这个不行 #plt.show(wordcloud)
wordcloud.to_image().show()
#plt.axis("off")
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hi"
wordcloud=wordcloud.WordCloud().generate(text)#这个不行 #plt.show(wordcloud)
wordcloud.to_image()
#plt.axis("off")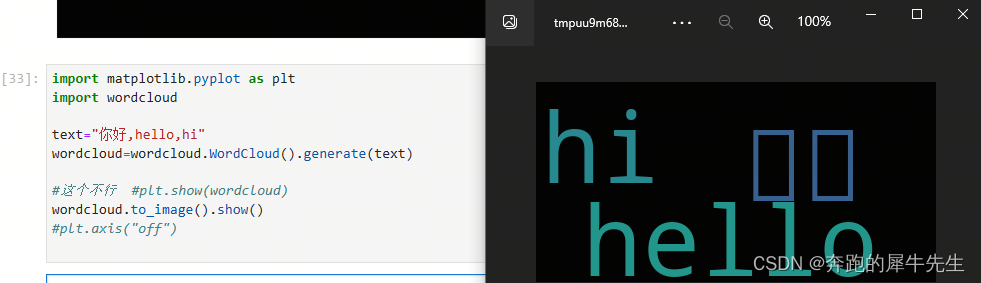
4.2 保存为图片
4.2.1 其他输出函数和依赖的包/模块
- 提供了四个输出函数:
- to_array(self):numpy数组格式
- to_file(self, filename)
- to_html(self):没有实现
- to_image(self):PIL图像
依赖的包
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
import matplotlib.pyplot as plt
import jieba
import jieba.analyse
from PIL import Image
import random
import numpy as np
4.2.2 使用 wordcloud.to_file(path) 保存词云
- wordcloud.to_file(path)
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hi"
wordcloud=wordcloud.WordCloud().generate(text)#这个不行 #plt.show(wordcloud)
wordcloud.to_file(r"C:\Users\Administrator\Desktop\1.png")
#plt.axis("off")
4.2.3 使用wordcloud.to_image().save(path)
- wordcloud.to_image().save(path)
import matplotlib.pyplot as plt
import wordcloudtext="你好,hello,hi"
wordcloud=wordcloud.WordCloud().generate(text)#这个不行 #plt.show(wordcloud)
wordcloud.to_image().save(r"C:\Users\Administrator\Desktop\2.png")
#plt.axis("off")
5 设置图片效果(下面没修改完成。。。)
mask 获得蒙版效果
蒙版==字体的显示区域
设置蒙版的边框
counter_width参数:我们注意到之前生成的图虽然有了边框,但只有一个大致的形状,想要把边框用直线画出来,就需要设置这个参数我们设置contour_width=3,得到的结果为:
11.mode参数:mode参数默认为RGB通道,如果我们想设置词云背景为透明,需要将mode设置为RGBA,background_color设置为None,生成结果为背景透明图片:
5.1 mask 蒙版相关
使用图片的配色??
from wordcloud import ImageColorGenerator from PIL import Image import numpy as np colors=np.array(Image.open("780.jpg")) color_map=ImageColorGenerator(colors)
我们通过将图片转化为array数组来获取它的RGB三通道值,再用wordcloud自带的ImageColorGenerator函数将其转为配色,注意这时候就不能再用colormap参数了,这时候得使用color_func参数:
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
from PIL import Image
import numpy as npcolors=np.array(Image.open("780.jpg"))
color_map=ImageColorGenerator(colors)
wd=WordCloud(font_path="C:\\Windows\\Fonts\\simsun.ttc",background_color="white",repeat=True,color_func=color_map)
wd.generate("1 2 33 333 31")
wd.to_file("1.png")
5.1.1 使用透明背景 蒙板
- 透明背景: mode=‘RGBA’, background_color=None
- mask = np.array(Image.open("black_mask.png"))
- wc = WordCloud(font_path='Hiragino.ttf', mode='RGBA', background_color=None, mask=mask, width=600, height=400)
5.1.2 使用蒙版中的颜色
- image_colors = ImageColorGenerator(mask)
- wc.recolor(color_func=image_colors)
5.1.3 自定义颜色
# 颜色函数
def random_color(word, font_size, position, orientation, font_path, random_state):
s = 'hsl(0, %d%%, %d%%)' % (random.randint(60, 80), random.randint(60, 80))
return s
...
wc = WordCloud(color_func=random_color, font_path='Hiragino.ttf',mode='RGBA', background_color=None, mask=mask)
下面2段只要1个,要改
from wordcloud import WordCloud# 创建一个WordCloud对象
wordcloud = WordCloud()# 定义文本
text = "This is a sample text for word cloud generation."# 使用WordCloud.generate()函数生成词云图
wordcloud.generate(text)# 显示词云图
wordcloud.to_image().show()from wordcloud import WordCloud
import matplotlib.pyplot as plt# 创建一个WordCloud对象
wordcloud = WordCloud()# 生成词云图
text = "Python wordcloud词云,在一段文本中提取关键词进行扁平化的展示,更能吸引目标客户的眼球。"
wordcloud.generate(text)# 显示词云图
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()6 jieba 和分词
6.1 中午分词模块,jieba,解霸?结巴?
6.2 获得文本内容
text = open("D:/++/宏观经济和资产配置.txt", encoding="utf-8").read() # 标明文本路径,打开
text = ' '.join(jieba.cut(text))
使用权重
# 提取关键词和权重
freq = jieba.analyse.extract_tags(text_new, topK=200, withWeight=True) # 列表
freq = {i[0]: i[1] for i in freq} # 字典
mask = np.array(Image.open(f"{base_dir}color_mask.png"))
wc = WordCloud(font_path='Hiragino.ttf',mode='RGBA', background_color=None, mask=mask)
res = wc.generate_from_frequencies(freq)
freq = nltk.FreqDist(word_text)
# wc.fit_words(freq) # 然后再generate
wc.generate_from_frequencies(freq)
# 分词
text_new = " ".join(jieba.cut(text))
wc = WordCloud('Hiragino.ttf') # 不加字体会中文乱码
text = ' '.join(jieba.cut(text))
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloudtext = open("D:/++/宏观经济和资产配置.txt", encoding="utf-8").read() # 标明文本路径,打开# 生成对象
wc = WordCloud(font_path = "C:\Windows\Fonts\Microsoft YaHei UI\msyh.ttc",width=500, height=400, mode="RGBA", background_color=None).generate(text)
# 显示词云图
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()#保存文件
wc.to_file("C:/Users/xiao/Desktop/ciyun1.png")这篇关于【python 的各种模块】(8) 在python使用matplotlib和wordcloud库来画wordcloud词云图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






