本文主要是介绍冯诺依曼模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
只要我们学习计算机操作系统,就离不开对冯诺依曼体系结构。因为我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。
1.什么是冯诺依曼模型呢?
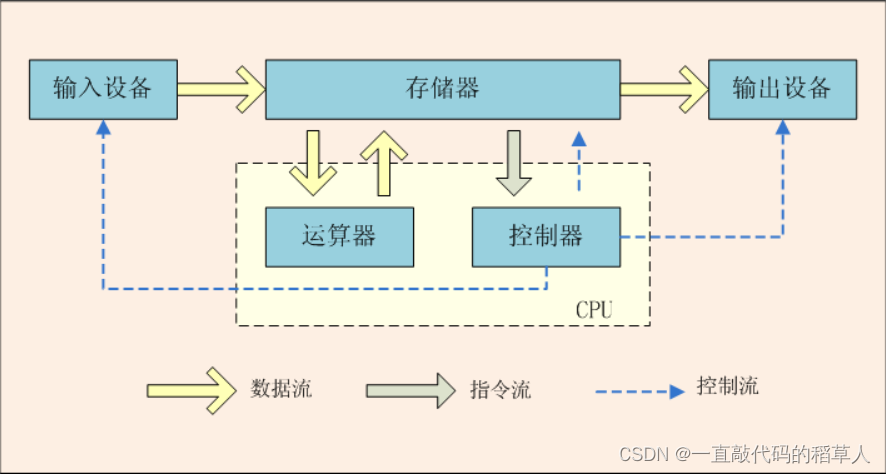
如上图所示,冯诺依曼模型由五大部分组成:输入设备、控制器、运算器、存储器、输出设备
2.五大组成部分:
控制器(Control Unit):从内存中读取指令、翻译指令、分析指令、然后根据指令的内存向有关部件发送控制命令,控制相关部件执行指令包含的操作。
运算器(ALU,Arithmetic Logic Unit):处理数据,完成各种算术运算和逻辑运算。
存储器(Memory):存储数据(内存)
输入设备(Input):鼠标、键盘、触控板等
输出设备(Output):显示器、打印机等
输入输出设备好理解,存储器如何区分内存和外存的区别呢?
给电脑断电以后,数据还在的存储区就是外存,也就是磁盘。如果数据不在,那说明该存储区就是内存。
而控制器就相当于大脑,给身体各个部位下达各种指令,运算器就相当于我们的手,直接干活的部位。控制器和运算器集也是CPU最核心的部件。
在冯诺依曼模型中,输入输出设备不会和CPU直接打交道,而是间接通过内存使CPU处理
3.为什么要在CPU和外设之间要存在内存呢?
首先我们要先明白计算机组成原理的存储器金字塔模型
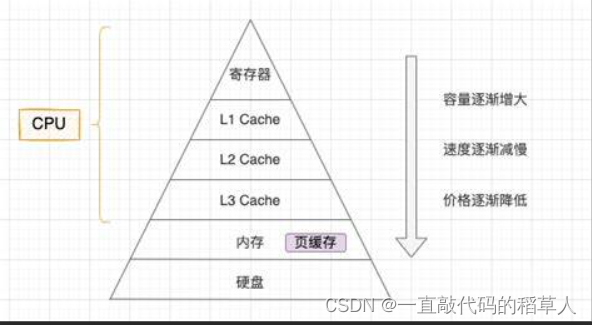
我们可以看到,CPU中寄存器的读取速度是最快的,体积是最小的,磁盘等外设的速度是最慢的,体积是最大的,并且两者的速度差太大!以至于,如果CPU直接在硬盘设备读取写入数据,那么我们CPU大部分的时间都在等待。所以,为了减缓这种差距,我们在CPU和硬盘之间引入了内存。
内存的特点:存储容量和读取写入数据的速度都介于CPU寄存器和硬盘之间,由于有比寄存器较大的容量,我们可以提前往内存区域存入“可能被读取的数据”,也就是预装数据,这样一来,CPU就不会傻傻等硬盘写入数据,而是直接到内存中读取,并且,内存的速度也不慢(相比于硬盘等外设)。
这样一来,有了内存这个缓冲地带,计算机的整体计算效率就会得到提高。
4.冯诺依曼模型发明的意义
冯.诺依曼结构消除了原始计算机体系中,只能依靠硬件控制程序的状况(程序作为控制器的一部分,作为硬件存在),将程序编码存储在存储器中,实现了可编程的计算机功能,实现了硬件设计和程序设计的分离,大大促进了计算机的发展。
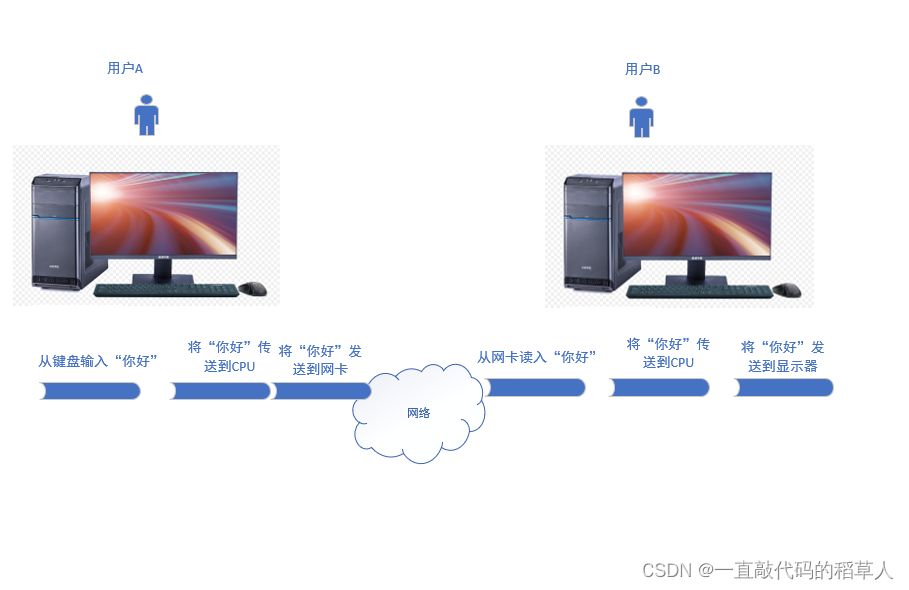
5.分析QQ发消息的数据流动过程(结合冯诺依曼模型)
用户A给用户B用QQ发送消息
这篇关于冯诺依曼模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








