本文主要是介绍【论文笔记】TransReID: Transformer-based Object Re-Identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TransReID
论文地址:https://arxiv.org/abs/2102.04378
代码:https://github.com/damo-cv/TransReID
这篇笔记是按照自己本人的习惯写的(一些词语、句子喜欢用英语表示);在看这篇论文之前,最好了解下ViT。感谢指教:)
程序框图如果有人想看的话,我就整理一下= =
论文阅读
Abstract
one of the key challenges in ReID:Extracting robust feature representation.
CNN:(缺点)一次只处理一个局部邻域,由于卷积和下采样(池化、跨步卷积)操作容易造成细节信息丢失。
ReID
- 双分支学习框架——设计一个与全局分之并行的jigsaw patch module (JPM) 分支,该分支通过shift、patch shuffle重新排列patch embeddings 以此生成更鲁棒的特征;
- side information embeddings (SIE):将摄像头或视角这些非视觉信息插入到learned embeddings中,以减轻它们引起的偏差。
1. Introduction
框架:CNN存在的问题→trandformer的优点→仍需改进的地方→提出TransReID
CNN存在的问题
ReID的关键:提取鲁棒、区分性的特征。
CNN-based method存在的问题:
- CNN集中关注小范围的判别区域,没有用到全局范围内的丰富结构模式rich structural patterns in a global scope;
- 含有更多细节信息detail information的细粒度特征很重要,CNN的下采样操作(池化、跨步卷积)减小了输出特征图的分辨率,影响模型对 相似外观物体的细节特征 的判别能力。
Trandformer的优点
与CNN相比,ViT、DeiT证明纯transformer模型在 图像识别的特征提取 这一方面也很有效。
由于multi-head attention的引入和下采样的移除,transformer更适合解决上面提到的两个问题,理由:
- multi-head attention捕获long range dependencies,驱使模型关注更多样的人体部位(与CNN相比);
!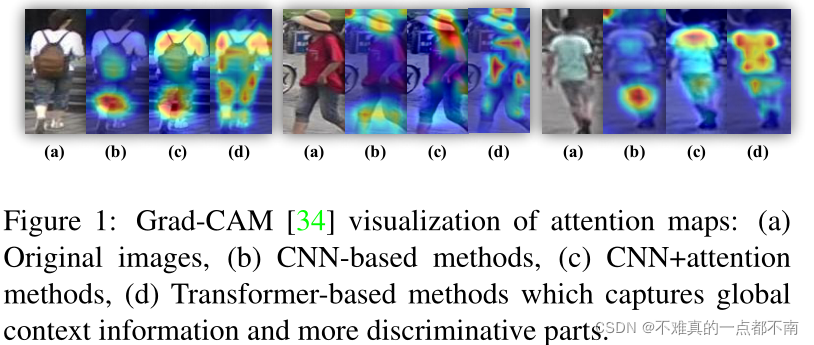
- 没有了下采样,transformer能够保留更多的细节信息。
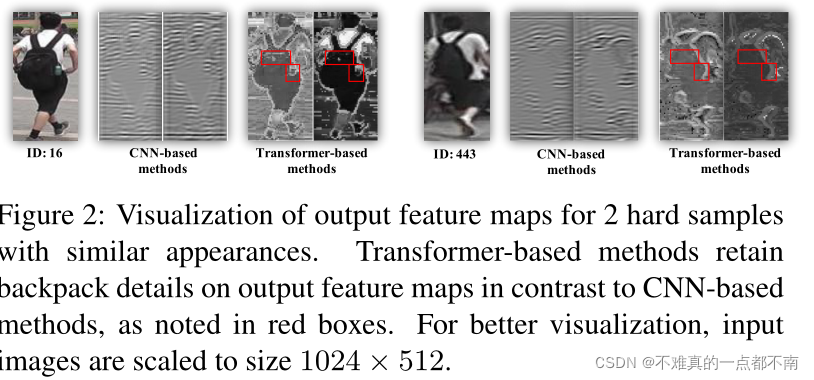
仍需改进的地方
针对ReID的一些问题(遮挡、姿势变化、相机视角),仍需做出改进。
- 局部特征local part features、侧边信息side information在CNN中被认为是增强鲁棒性基本、有效的方法。Learning part/stripe aggregated features makes it robust against occlusions and misalignments.然而,将rigid stripe part methods 从CNN模型扩展到transformer模型,由于将全局序列分成几个孤立的序列,可能会破坏long-range dependencies。
- 另外,考虑到摄像头、视角这些侧边信息(side information),应构建一个不变特征空间(an invariant feature space),减少side information引起的偏差。然而,CNN中side information的复杂设计,如果直接运用到transformer中,不能充分利用the inherent encoding capabilities of transformers。
对于transformer来说,要想解决以上问题,特定模块的设计必不可少。
提出TransReID
- 通过一些关键的适应性调整,构建了一个基于纯transformer的baseline。
- 为扩展long-range dependencies、增强特征稳健性及扰动不变性,提出jigsaw
patches module(JPM),由shift 与patch shuffle 操作组成,重新排列patch embeddings,进一步进行特征学习。在模型的最后一层,JPM与全局分支并行,JPM提取鲁棒特征。 - 引入了side information embedding(SIE)。提出了一个统一的框架,通过learned embeddings有效地整合非视觉线索——也就是encodes side information by learnable embeddings,以减小摄像头或视角导致的数据偏差。如下图,SIE可以减小相机间、相机内匹配对的相似性差异。
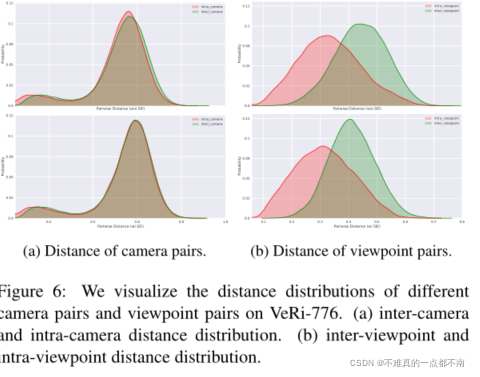
2. Related Work
2.1 Object ReID
相关损失函数:cross-entropy loss (ID loss) 和triplet loss
细粒度特征
Side information
2.2 Pure Transformer in Vision
ViT DeiT
3. Methods
3.1 :一些关键的改进(策略)得到baseline:Overlapping Patches+position embeddings(双线性插值)+监督学习(交叉熵损失函数+三元损失函数)
3.2 :JIM:baseline只用到全局特征→遇到遮挡、错位时需要局部特征→CNN采用局部细粒度特征→简单直接的方法不可行→提出JPM(shift+patch shuffle)
3.3:SIE
JIM、SIE以端到端方式联合训练。
3.1 Transformer-based strong baseline
两个主要阶段:特征提取+监督学习。
baseline的结构与ViT大致一致:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-myMFAU9b-1640483157349)(TransReID%20fb90cfb3e1294c4d895319bfac4ef01e/Untitled%203.png)]](https://img-blog.csdnimg.cn/e1161abc64a54dab9064b88038aa5381.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiN6Zq-55yf55qE5LiA54K56YO95LiN5Y2X,size_20,color_FFFFFF,t_70,g_se,x_16)
Overlapping Patches:ViT、DeiT将图像分割成不重叠的patches→patches周围的局部邻近结构信息丢失→我们使用滑动窗口来生成patches with overlapping pixels。
步长: S S S、patch的大小 P P P(一般 S S S比 P P P小),则相邻两个patch重叠区域的大小: ( P − S ) × P (P−S)×P (P−S)×P。像素 H × W H×W H×W的输入图像被分割成 N N N个patches:
N = N H × N W = [ H + S − P S ] × [ W + S − P S ] N=N_H×N_W=[\frac{H+S-P}S]×[\frac{W+S-P}S] N=NH×NW=[SH+S−P]×[SW+S−P]
补丁越多,性能越好,但计量算也更大。
Position Embeddings:与ViT相同,Position Embeddings编码相对应patches的位置信息,由于ReID任务的图像像素可能会与分类任务的图像像素不同,ImageNet中预训练的position embeddings不能直接拿来用,这里引入双线性插值。
监督学习:损失函数包括ID loss L I D L_{ID} LID——cross-entropy loss without label smooth、三元损失函数(with soft-margin) L T = l o g [ 1 + e x p ( ∣ ∣ f a − f p ∣ ∣ 2 2 − ∣ ∣ f a − f n ∣ ∣ 2 2 ) ] L_T=log[1+exp(||f_a-f_p||_2^2-||f_a-f_n||_2^2)] LT=log[1+exp(∣∣fa−fp∣∣22−∣∣fa−fn∣∣22)]
3.2 Jigsaw patches module(JPM)
transformer-based strong base line利用图像的全局信息。
但遇到遮挡、错位时,我们只能观察到物体的部分信息,CNN一般使用细粒度局部特征解决这些问题。
在transformer中,简单直接的方式是将原模型最后一层的特征 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;
这篇关于【论文笔记】TransReID: Transformer-based Object Re-Identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






