本文主要是介绍Node-Red如何采集ModbusRTU设备的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、内容简介
本篇内容主要介绍Node-Red如何通过node-red-contrib-modbus插件采集ModbusRTU设备的数据,用Modbus Slave工具来模拟从站设备,用Virtual Serial Port Driver工具来虚拟串口,数据读写方式与Node-Red跟ModbusTCP通信的方法类似。
二、环境搭建
1.配置Virtual Serial Port Driver
按要求安装好Virtual Serial Port Driver,打开软件,点击“Add pair”按钮添加一对虚拟串口对。
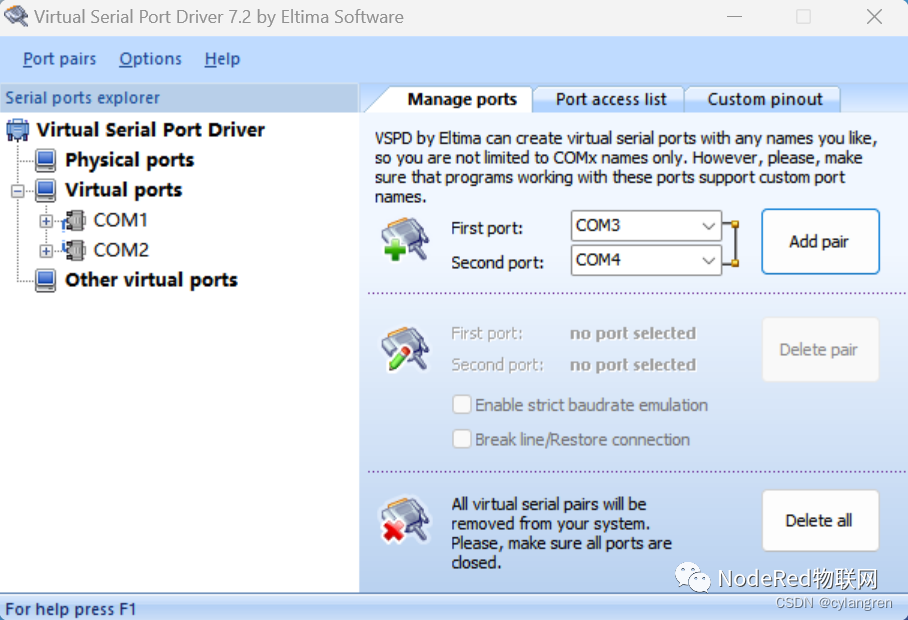
打开设备管理器,可以看到增加了两个串口

这两个串口逻辑上是相连的,可以相互通讯,避免了物理链路连接,方便测试。
2.配置Modbus Slave
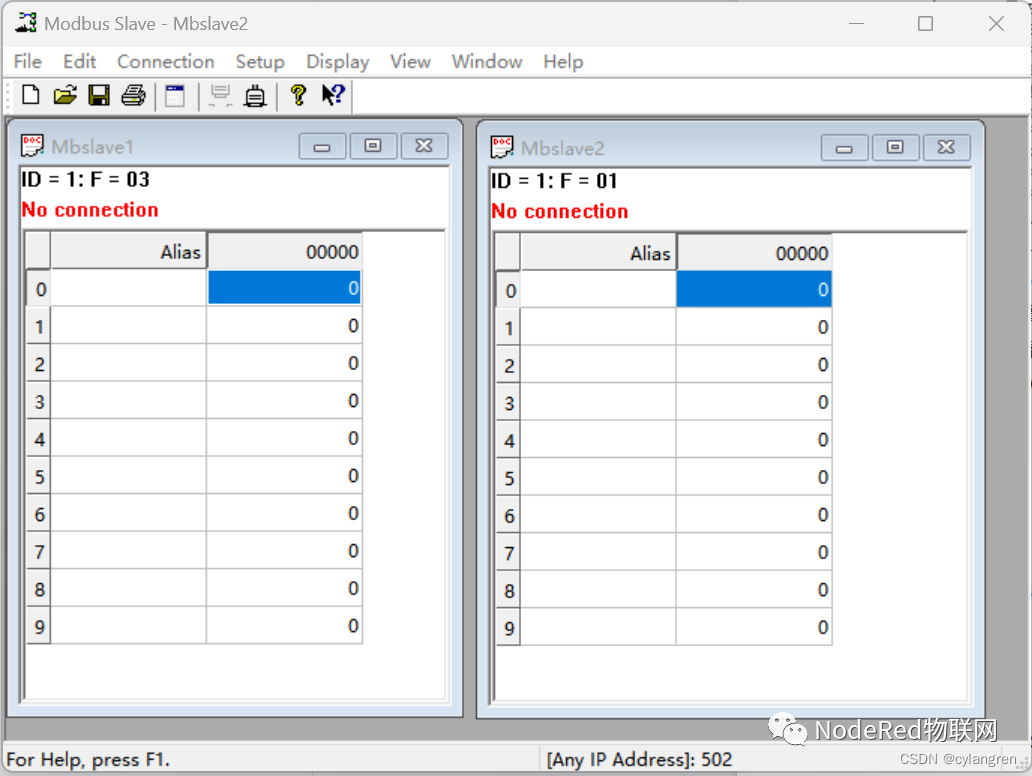
1.新建10个线圈和10个保持寄存器,打开软件已经默认新建了10个保持寄存器,点击“File->New”菜单,再默认新建10个保持寄存器,然后点击“Setup->Slave Definition”菜单,修改Function下拉选项为“01 Coil Status (0x)”,点击“OK”按钮确认。
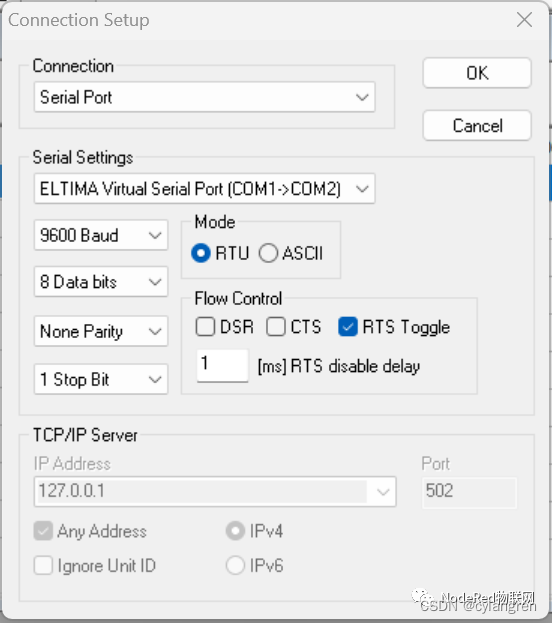
连接串口,点击“Connection->Connect...”菜单,弹出Connection Setup的对话框,在Connection下拉框选择“Serial Port”选项,Serial Settings下载框选择“ELTIMA Virtual Serial Port (COM1->COM2)”选项,波特率选择“9600 Baud”选项,数据位选择“8 Data bits”选项,校验位选择“None Parity”,停止位选择“1 Stop Bit”,其余参数保持不变,点击“OK”确认。
三、数据采集
1.导入流程
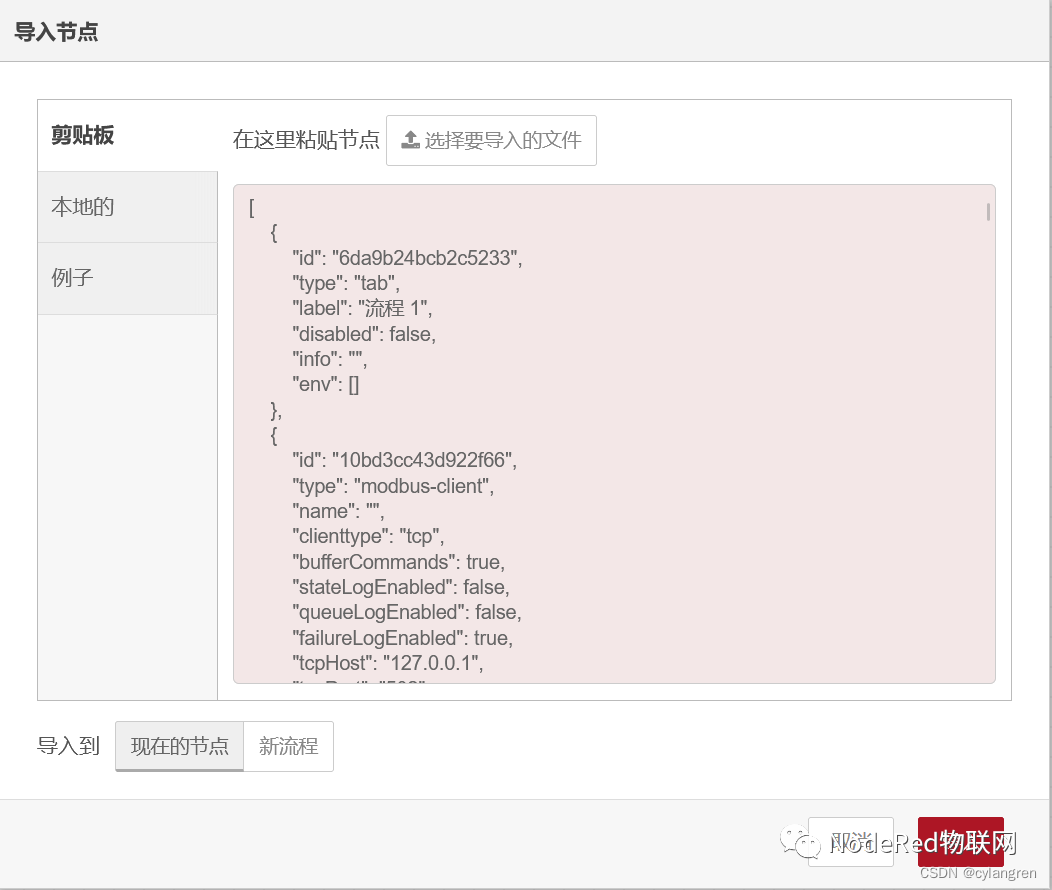
导入文章Node-Red与ModbusTCP设备通信——读数据中的流程,点击Node-Red右上角的菜单选择“导入”,在弹出的对话框中点击“选择要导入的文件”按钮,选择要导入的文件,点击“打开”确认,回到导入页面,点击“导入”按钮导入文件。
由于跟当前工作流中的节点重复,所以弹出确认对证框,点击“导入副本”按钮即可。

此时重新生成了一个流程标签
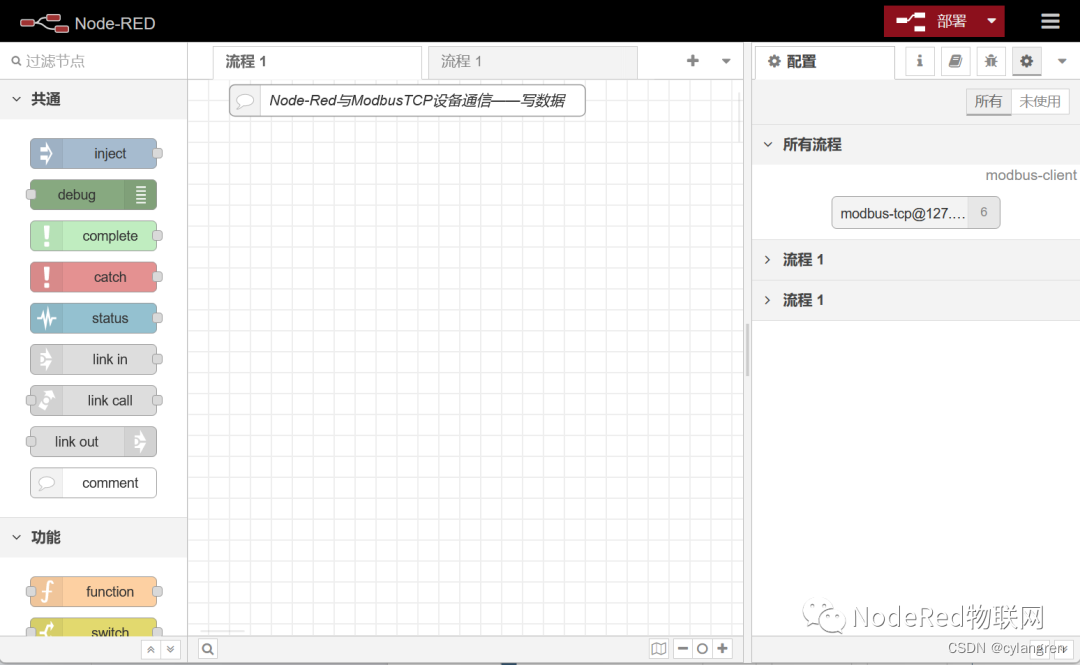
现在需要删除当前流程,点击工作区右上角的菜单,将鼠标移到“流程”菜单项,选择“删除”,当前流程随即被删除,现在工作区只剩一个流程。
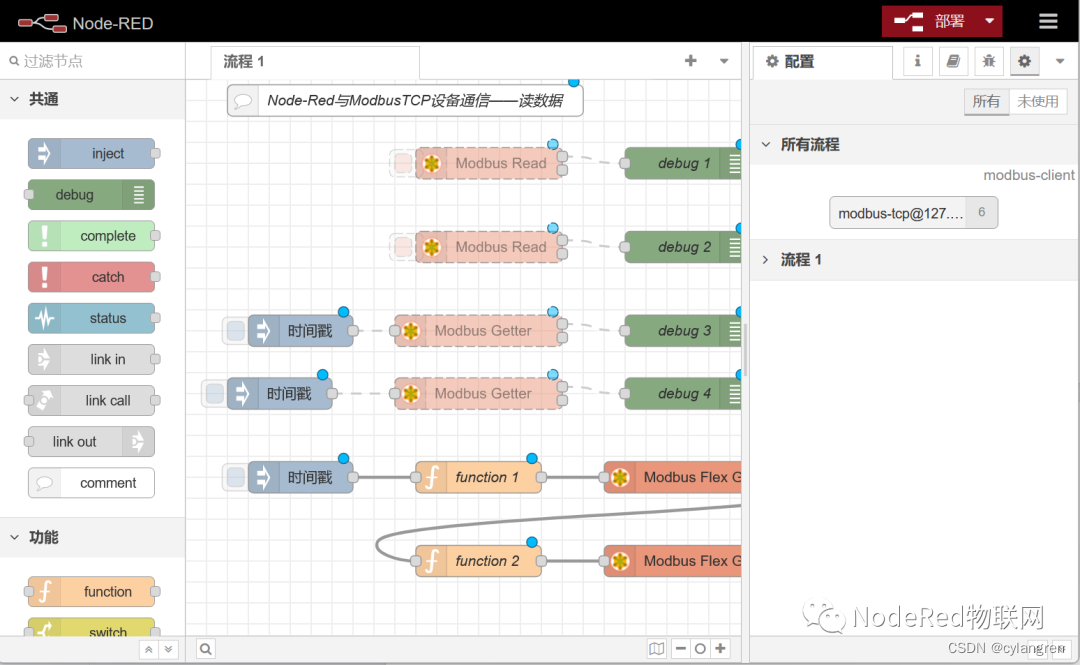
2.修改Modbus Server
双击第一个Modbus-Read节点,在弹出的对话框点击Server下拉框后面的“笔形”按钮修改Server参数。
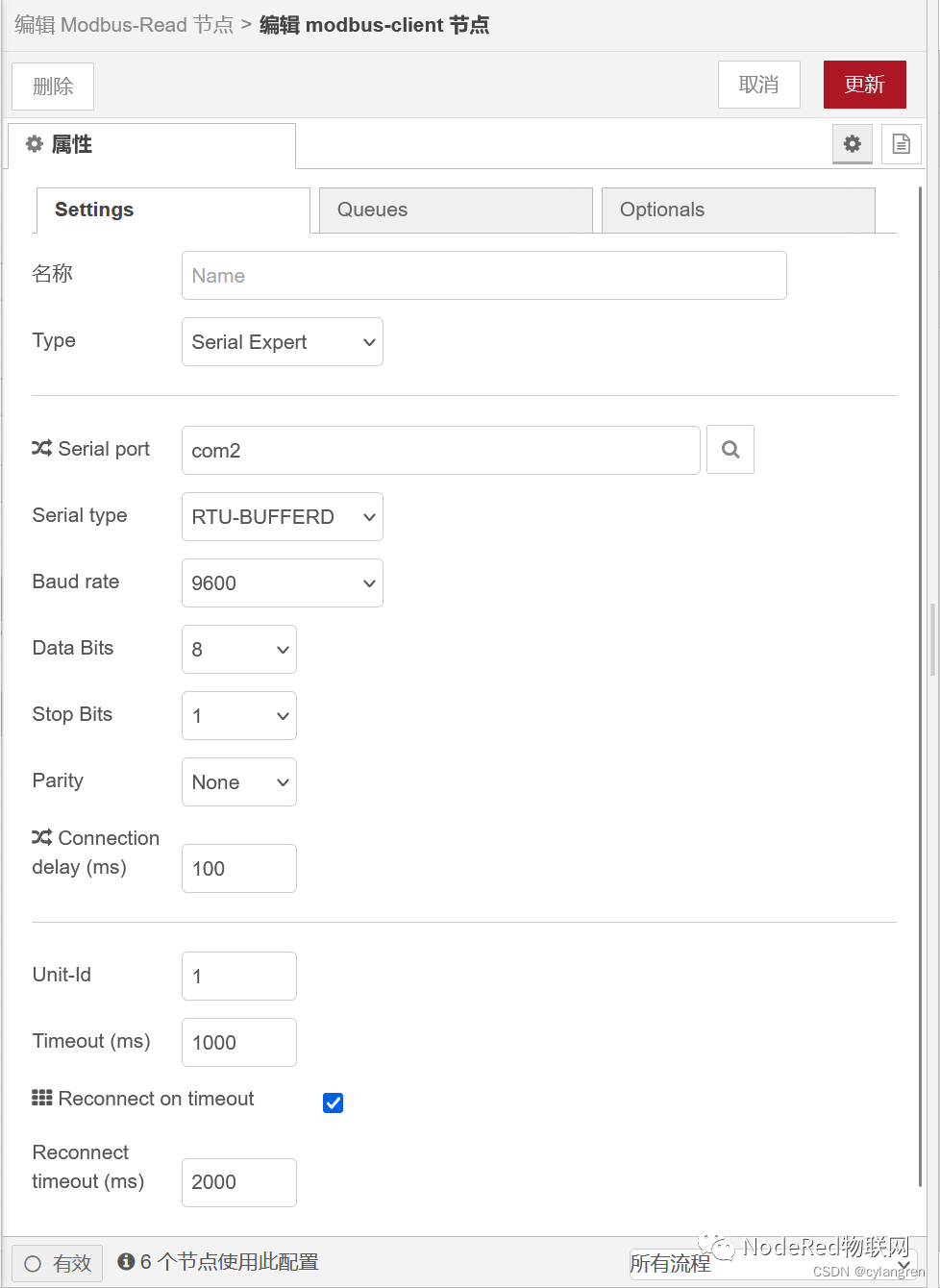
在Type下拉框选择“Serial Expert”选项,在Serial port输入框中输入“com2”,确认Baud rate为“9600”,Data Bits为“8”,Stop Bits为“1”,Parity为“None”,其余参数保持不变,点击“更新”按钮确定。
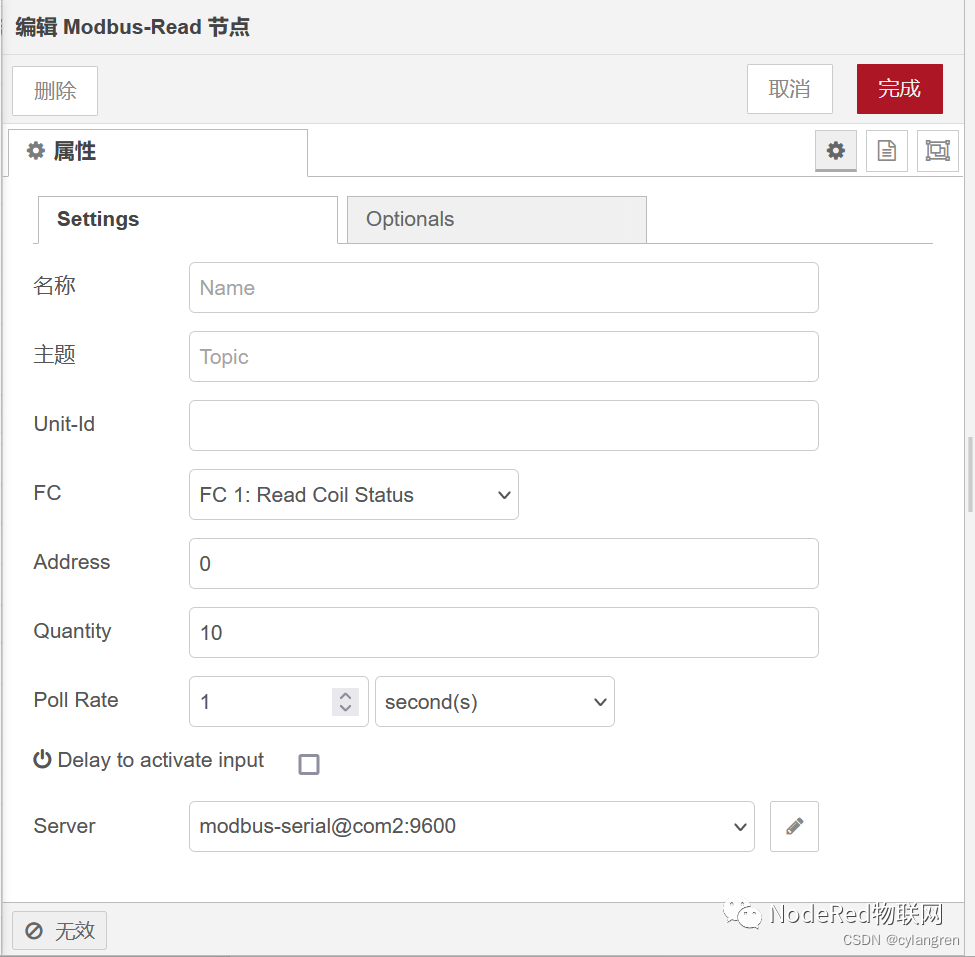
回到节点编辑页面,点击“完成”按钮确定,其它Modbus-Read节点的Server也同步进行了修改,点击工作区右上角的“部署”按钮部署流程。
接下来进行测试,点击最后一个流的inject节点(时间戳),可以在工作区右侧的调试面板看到返回数据,说明读取数据成功。
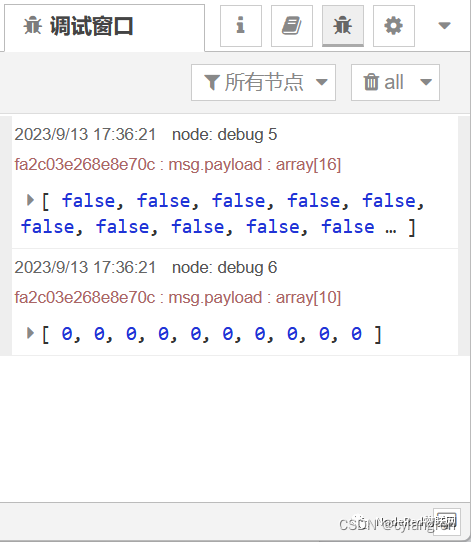
写数据的方法类似,将文章Node-Red与ModbusTCP设备通信——写数据中的流导入工作区,修改对应的Server参数即可。
如果您想获取文章相关的代码、工具等资料,关注公众号“NodeRed物联网”,回复“nr”即可。
这篇关于Node-Red如何采集ModbusRTU设备的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







